
HBase分散式資料庫理論介紹
阿新 • • 發佈:2018-12-26
HBase的原型是Google的BigTable論文,可以在我的資源裡下載中文版的paper。
本不想設定積分可供免費下載,可是CSDN改版後不能自定義積分了,是系統根據資源動態分配的。
這一改版實在是不人性化,市場應該是自由的,更何況這種共享的資源。
https://download.csdn.net/download/xdsxhdyy/10801955
在Hadoop生態系統中HBase扮演的角色是:解決大規模資料的離線批量處理問題
HBase的四維座標[行鍵,列族,列限定符,時間戳] 來確定一個單元格。
HBase系統架構
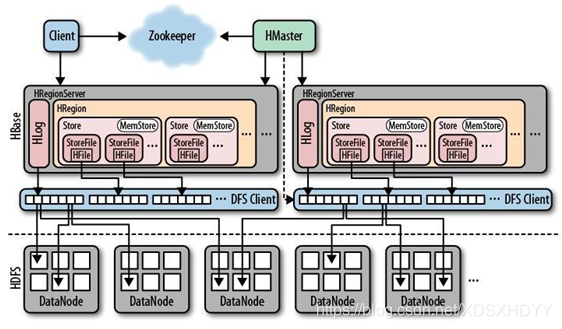
1.客戶端
- 客戶端包含訪問HBase的介面,在快取中維護著已經訪問過的Region位置資訊,加快後續訪問過程
2.ZooKeeper伺服器
- ZooKeeper是一個很好的叢集管理工具,保證任何時刻總有唯一一個Master作為叢集的總管,被大量用於分散式計算、提供配置維護、域名服務、分散式同步、組服務等
3.Master
- 主伺服器Master主要負責監控RegionServer,處理RegionServer故障轉移,
- 處理元資料的變更,處理region的分配或移除
- 實現不同Region伺服器之間的負載均衡
- 通過Zookeeper釋出自己的位置給客戶端
4.RegionServer
- 是HBase中最核心的模組,負責維護分配給自己的Region,並響應使用者的讀寫請求
- 負責儲存HBase的實際資料,重新整理快取到HDFS,維護HLog
5.HFile
- 在磁碟上儲存原始資料的實際的物理檔案,是實際的儲存檔案。
6.Store
- HFile儲存在Store中,一個Store對應HBase表中的一個列族。
7.MemStore
- 記憶體儲存,位於記憶體中,用來儲存當前的資料操作。
8.Region
- Hbase表的分片,HBase表會根據RowKey值被切分成不同的region儲存在RegionServer中,在一個RegionServer中可以有多個不同的region。
HBase讀寫資料流程
-
HRegionServer儲存著一張.META.的元資料資訊表,讀取和寫入資料之前一般client會先去訪問zookeeper獲取-ROOT-表的位置進而找到.META.表在哪個HRegionServer上儲存著,通過元資料資訊表,就可以確定當前將要讀寫的資料所對應的RegionServer伺服器和Region
-
當用戶讀取資料時,Region伺服器會首先訪問MemStore快取,如果找不到再去磁碟上面的StoreFile中尋找
-
使用者寫入資料時,被分配到相應的Region伺服器去執行
使用者資料首先被寫入到MemStore(快取)和Hlog(日誌)中
只有當操作寫入Hlog之後,commit()呼叫才會將其返回給客戶端
HBase與傳統關係資料庫的對比分析
1.資料型別:關係資料庫採用關係模型,有豐富的資料型別和儲存方式;HBase採用簡單資料模型,儲存未經解釋的字串
2.資料操作:關係資料庫有豐富的操作,涉及多表連線。HBase只有簡單的操作
3.儲存模式:關係資料庫是基於行模式儲存;HBase是基於列儲存的
4.資料索引:關係資料庫針對不同列構建複雜的多個索引;HBase只有一個索引---行鍵
5.資料維護:關係資料庫中更新是用新值換舊值;HBsae更新不會刪除舊版本,而是新舊同時保留
6.可伸縮性:關係資料庫很難實現橫向擴充套件;HBase分散式資料庫可靈活實現水平擴充套件