
GoogLeNet Inception v1詳解
參考:https://my.oschina.net/u/876354/blog/1637819
2014年,GoogLeNet和VGG是當年ImageNet挑戰賽(ILSVRC14)的雙雄,GoogLeNet獲得了第一名、VGG獲得了第二名,這兩類模型結構的共同特點是層次更深了。VGG繼承了LeNet以及AlexNet的一些框架結構,而GoogLeNet則做了更加大膽的網路結構嘗試,雖然深度只有22層,但大小卻比AlexNet和VGG小很多,GoogleNet引數為500萬個,AlexNet引數個數是GoogleNet的12倍,VGGNet引數又是AlexNet的3倍,因此在記憶體或計算資源有限時,GoogleNet是比較好的選擇;從模型結果來看,GoogLeNet的效能卻更加優越。
**小知識:**GoogLeNet是谷歌(Google)研究出來的深度網路結構,為什麼不叫“GoogleNet”,而叫“GoogLeNet”,據說是為了向“LeNet”致敬,因此取名為“GoogLeNet”
那麼,GoogLeNet是如何進一步提升效能的呢?
一般來說,提升網路效能最直接的辦法就是增加網路深度和寬度,深度指網路層次數量、寬度指神經元數量。但這種方式存在以下問題:
(1)引數太多,如果訓練資料集有限,很容易產生過擬合;
(2)網路越大、引數越多,計算複雜度越大,難以應用;
(3)網路越深,容易出現梯度彌散問題(梯度越往後穿越容易消失),難以優化模型。
所以,有人調侃“深度學習”其實是“深度調參”。
解決這些問題的方法當然就是在增加網路深度和寬度的同時減少引數,為了減少引數,自然就想到將全連線變成稀疏連線。但是在實現上,全連線變成稀疏連線後實際計算量並不會有質的提升,因為大部分硬體是針對密集矩陣計算優化的,稀疏矩陣雖然資料量少,但是計算所消耗的時間卻很難減少。
那麼,有沒有一種方法既能保持網路結構的稀疏性,又能利用密集矩陣的高計算效能。大量的文獻表明可以將稀疏矩陣聚類為較為密集的子矩陣來提高計算效能,就如人類的大腦是可以看做是神經元的重複堆積,因此,GoogLeNet團隊提出了Inception網路結構,就是構造一種“基礎神經元”結構,來搭建一個稀疏性、高計算效能的網路結構。
【問題來了】什麼是Inception呢?
Inception歷經了V1、V2、V3、V4等多個版本的發展,不斷趨於完善,下面一一進行介紹
一、Inception V1
通過設計一個稀疏網路結構,但是能夠產生稠密的資料,既能增加神經網路表現,又能保證計算資源的使用效率。谷歌提出了最原始Inception的基本結構:
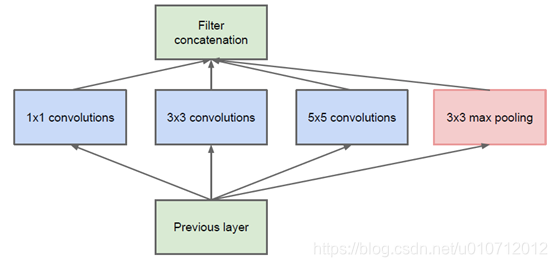
該結構將CNN中常用的卷積(1x1,3x3,5x5)、池化操作(3x3)堆疊在一起(卷積、池化後的尺寸相同,將通道相加),一方面增加了網路的寬度,另一方面也增加了網路對尺度的適應性。
網路卷積層中的網路能夠提取輸入的每一個細節資訊,同時5x5的濾波器也能夠覆蓋大部分接受層的的輸入。還可以進行一個池化操作,以減少空間大小,降低過度擬合。在這些層之上,在每一個卷積層後都要做一個ReLU操作,以增加網路的非線性特徵。
然而這個Inception原始版本,所有的卷積核都在上一層的所有輸出上來做,而那個5x5的卷積核所需的計算量就太大了,造成了特徵圖的厚度很大,為了避免這種情況,在3x3前、5x5前、max pooling後分別加上了1x1的卷積核,以起到了降低特徵圖厚度的作用,這也就形成了Inception v1的網路結構,如下圖所示:
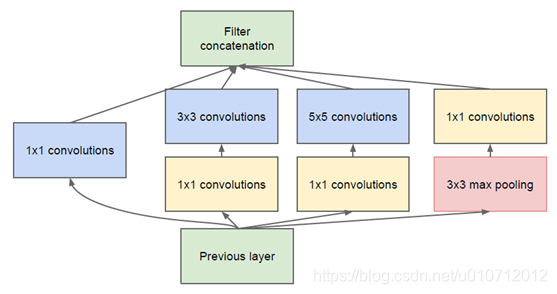
1x1的卷積核有什麼用呢?
1x1卷積的主要目的是為了減少維度,還用於修正線性啟用(ReLU)。比如,上一層的輸出為100x100x128,經過具有256個通道的5x5卷積層之後(stride=1,pad=2),輸出資料為100x100x256,其中,卷積層的引數為128x5x5x256= 819200。而假如上一層輸出先經過具有32個通道的1x1卷積層,再經過具有256個輸出的5x5卷積層,那麼輸出資料仍為為100x100x256,但卷積引數量已經減少為128x1x1x32 + 32x5x5x256= 204800,大約減少了4倍。
基於Inception構建了GoogLeNet的網路結構如下(共22層):
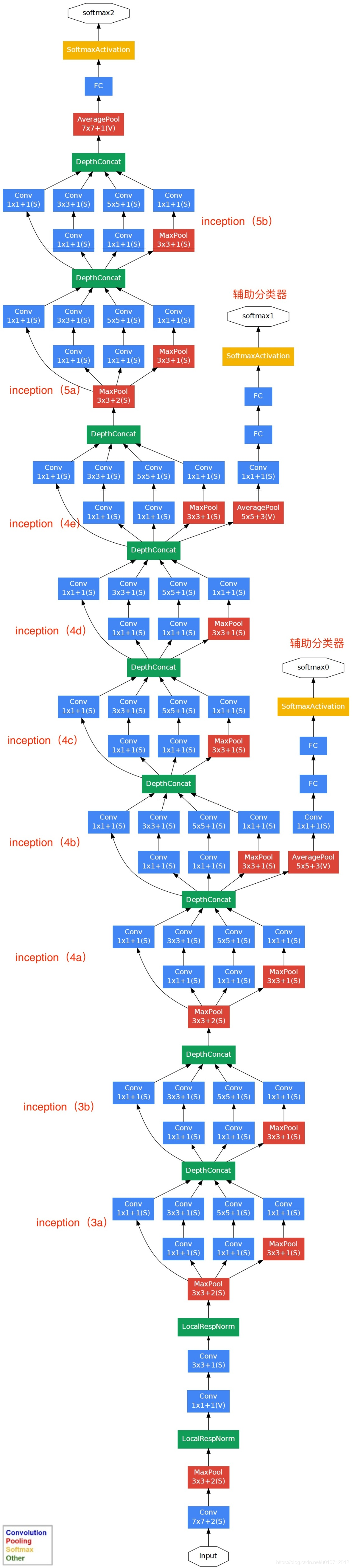
對上圖說明如下:
(1)GoogLeNet採用了模組化的結構(Inception結構),方便增添和修改;
(2)網路最後採用了average pooling(平均池化)來代替全連線層,該想法來自NIN(Network in Network),事實證明這樣可以將準確率提高0.6%。但是,實際在最後還是加了一個全連線層,主要是為了方便對輸出進行靈活調整;
(3)雖然移除了全連線,但是網路中依然使用了Dropout ;
(4)為了避免梯度消失,網路額外增加了2個輔助的softmax用於向前傳導梯度(輔助分類器)。輔助分類器是將中間某一層的輸出用作分類,並按一個較小的權重(0.3)加到最終分類結果中,這樣相當於做了模型融合,同時給網路增加了反向傳播的梯度訊號,也提供了額外的正則化,對於整個網路的訓練很有裨益。而在實際測試的時候,這兩個額外的softmax會被去掉。
GoogLeNet的網路結構圖細節如下:
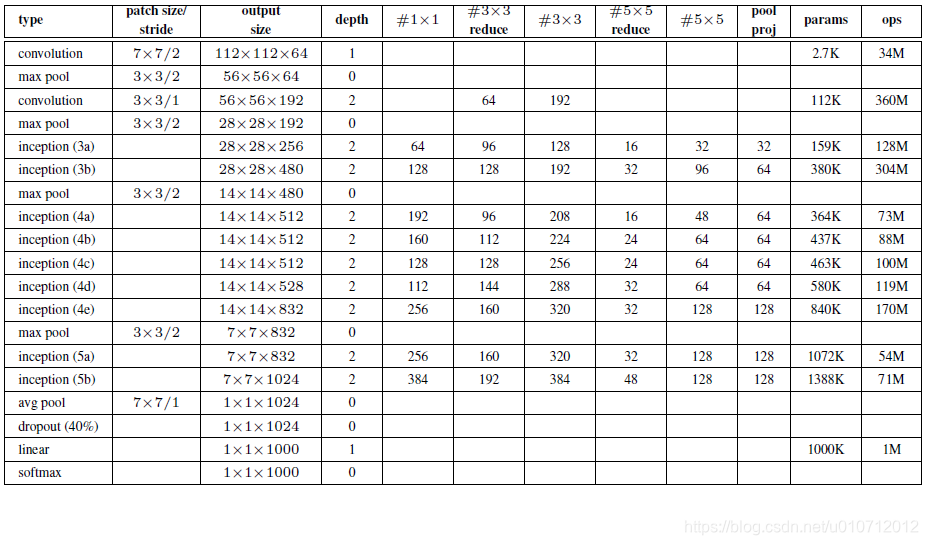
注:上表中的“#3x3 reduce”,“#5x5 reduce”表示在3x3,5x5卷積操作之前使用了1x1卷積的數量。
GoogLeNet網路結構明細表解析如下:
0、輸入
原始輸入影象為224x224x3,且都進行了零均值化的預處理操作(影象每個畫素減去均值)。
1、第一層(卷積層)
使用7x7的卷積核(滑動步長2,padding為3),64通道,輸出為112x112x64,卷積後進行ReLU操作
經過3x3的max pooling(步長為2),輸出為((112 - 3+1)/2)+1=56,即56x56x64,再進行ReLU操作
2、第二層(卷積層)
使用3x3的卷積核(滑動步長為1,padding為1),192通道,輸出為56x56x192,卷積後進行ReLU操作
經過3x3的max pooling(步長為2),輸出為((56 - 3+1)/2)+1=28,即28x28x192,再進行ReLU操作
3a、第三層(Inception 3a層)
分為四個分支,採用不同尺度的卷積核來進行處理
(1)64個1x1的卷積核,然後RuLU,輸出28x28x64
(2)96個1x1的卷積核,作為3x3卷積核之前的降維,變成28x28x96,然後進行ReLU計算,再進行128個3x3的卷積(padding為1),輸出28x28x128
(3)16個1x1的卷積核,作為5x5卷積核之前的降維,變成28x28x16,進行ReLU計算後,再進行32個5x5的卷積(padding為2),輸出28x28x32
(4)pool層,使用3x3的核(padding為1),輸出28x28x192,然後進行32個1x1的卷積,輸出28x28x32。
將四個結果進行連線,對這四部分輸出結果的第三維並聯,即64+128+32+32=256,最終輸出28x28x256
3b、第三層(Inception 3b層)
(1)128個1x1的卷積核,然後RuLU,輸出28x28x128
(2)128個1x1的卷積核,作為3x3卷積核之前的降維,變成28x28x128,進行ReLU,再進行192個3x3的卷積(padding為1),輸出28x28x192
(3)32個1x1的卷積核,作為5x5卷積核之前的降維,變成28x28x32,進行ReLU計算後,再進行96個5x5的卷積(padding為2),輸出28x28x96
(4)pool層,使用3x3的核(padding為1),輸出28x28x256,然後進行64個1x1的卷積,輸出28x28x64。
將四個結果進行連線,對這四部分輸出結果的第三維並聯,即128+192+96+64=480,最終輸出輸出為28x28x480
第四層(4a,4b,4c,4d,4e)、第五層(5a,5b)……,與3a、3b類似,在此就不再重複。
從GoogLeNet的實驗結果來看,效果很明顯,差錯率比MSRA、VGG等模型都要低,對比結果如下表所示:

這就是GoogLeNet的初級版本形式v1,下次來看看改進版inception v2是什麼模樣!