
tensorflow入門_7
阿新 • • 發佈:2018-12-26
這是alexnet網路定義的部分 ,我們只需要修改這一部就可以了
def alex_net(_X, _weights, _biases, _dropout): # Reshape input picture _X = tf.reshape(_X, shape=[-1, 28, 28, 1]) # Convolution Layer conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1']) # Max Pooling (down-sampling) pool1 = max_pool('pool1', conv1, k=2) # Apply Normalization norm1 = norm('norm1', pool1, lsize=4) # Apply Dropout norm1 = tf.nn.dropout(norm1, _dropout) # Convolution Layer conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2']) # Max Pooling (down-sampling) pool2 = max_pool('pool2', conv2, k=2) # Apply Normalization norm2 = norm('norm2', pool2, lsize=4) # Apply Dropout norm2 = tf.nn.dropout(norm2, _dropout) # Convolution Layer conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3']) # Max Pooling (down-sampling) pool3 = max_pool('pool3', conv3, k=2) # Apply Normalization norm3 = norm('norm3', pool3, lsize=4) # Apply Dropout norm3 = tf.nn.dropout(norm3, _dropout) # Fully connected layer dense1 = tf.reshape(norm3, [-1, _weights['wd1'].get_shape().as_list()[0]]) # Reshape conv3 output to fit dense layer input dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1') # Relu activation dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation # Output, class prediction out = tf.matmul(dense2, _weights['out']) + _biases['out'] return out # Store layers weight & bias weights = { 'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])), 'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])), 'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])), 'wd1': tf.Variable(tf.random_normal([4*4*256, 1024])), 'wd2': tf.Variable(tf.random_normal([1024, 1024])), 'out': tf.Variable(tf.random_normal([1024, 10])) } biases = { 'bc1': tf.Variable(tf.random_normal([64])), 'bc2': tf.Variable(tf.random_normal([128])), 'bc3': tf.Variable(tf.random_normal([256])), 'bd1': tf.Variable(tf.random_normal([1024])), 'bd2': tf.Variable(tf.random_normal([1024])), 'out': tf.Variable(tf.random_normal([n_classes])) } # Construct model pred = alex_net(x, weights, biases, keep_prob)
首選要理清他的網路圖 這是alexnet論文的 圖片 ,這裡引用一下 ,每一層與上面對應

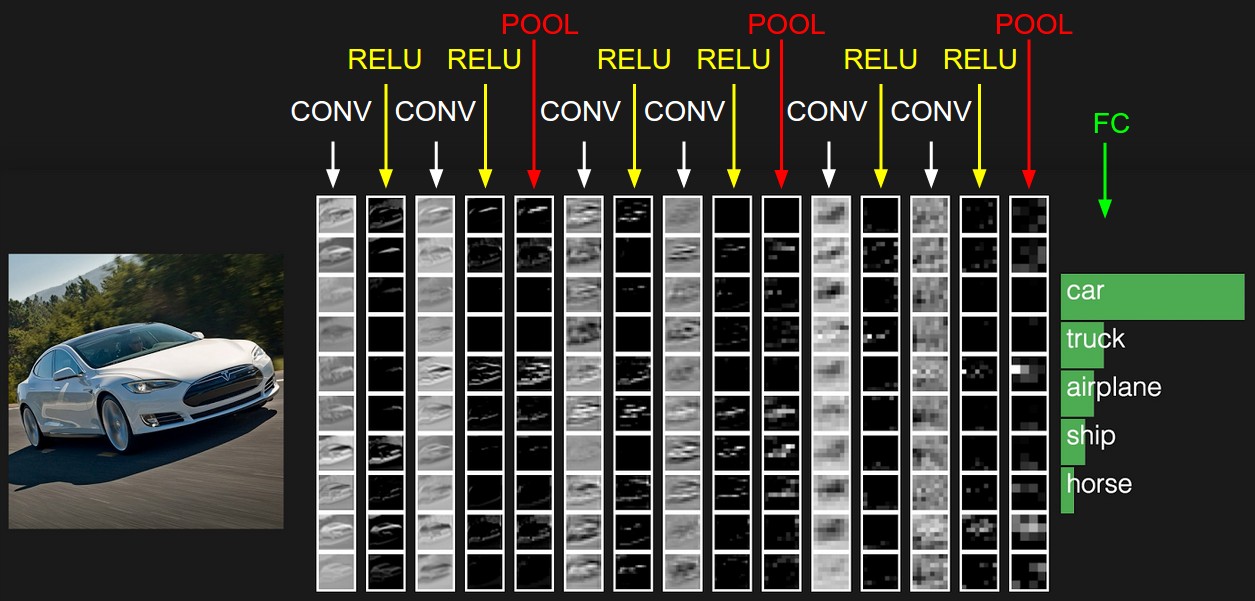
下面 我們 做一個實現 ,我們 給conv1 conv2 conv3 後面加上一個conv4 maxpool ,我們看看核心程式碼區域
Y=wx+b
# Convolution Layer conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1']) # Max Pooling (down-sampling) pool1 = max_pool('pool1', conv1, k=2) # Apply Normalization norm1 = norm('norm1', pool1, lsize=4) # Apply Dropout norm1 = tf.nn.dropout(norm1, _dropout) # Convolution Layer conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2']) # Max Pooling (down-sampling) pool2 = max_pool('pool2', conv2, k=2) # Apply Normalization norm2 = norm('norm2', pool2, lsize=4) # Apply Dropout norm2 = tf.nn.dropout(norm2, _dropout) # Convolution Layer conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3']) # Max Pooling (down-sampling) pool3 = max_pool('pool3', conv3, k=2) # Apply Normalization norm3 = norm('norm3', pool3, lsize=4) # Apply Dropout norm3 = tf.nn.dropout(norm3, _dropout)
我先往上面我們加上conv4一層
#這後面我們加上部分程式碼
#convolution layer conv4 = conv2d('conv4',norm3,tf.Variable(tf.random_normal([2, 2, 256, 512)),tf.Variable(tf.random_normal([512])) # Max Pooling (down-sampling) pool4 = max_pool('pool4', conv4, k=2) # Apply Normalization norm4 = norm('norm4', pool4, lsize=4) # Apply Dropout norm4 = tf.nn.dropout(norm4, _dropout)
這樣我們 我們加上一層conv2 以2 2的卷積核以及 512輸出特徵 2x2的pool .我們先不考慮 精度會不會提高的問題,我們只是自定義一個測試看看
根據上面的卷積一層一層 shape 運算 我們得到
最後一層計算(4-2)/2+1=2
也就是說輸入為2*2*512
這樣我們只需要修改w的矩陣格式 以及 b的矩陣格式即可了

這時候 我們成功在官方alexnet網路上加了一層
形成了 conv1--->conv2----->conv3---->conv4---->full---full---softmax分類 的一個自創的新網路
下面 貼出 修改後的alexnet的程式碼
import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
import tensorflow as tf
# Parameters
learning_rate = 0.001
training_iters = 200000
batch_size = 64
display_step = 20
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.8 # Dropout, probability to keep units
# tf Graph input
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32) # dropout (keep probability)
# Create custom model
def conv2d(name, l_input, w, b):
return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(l_input, w, strides=[1, 1, 1, 1], padding='SAME'),b), name=name)
def max_pool(name, l_input, k):
return tf.nn.max_pool(l_input, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME', name=name)
def norm(name, l_input, lsize=4):
return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)
def customnet(_X, _weights, _biases, _dropout):
# Reshape input picture
_X = tf.reshape(_X, shape=[-1, 28, 28, 1])
# Convolution Layer
conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1'])
# Max Pooling (down-sampling)
pool1 = max_pool('pool1', conv1, k=2)
# Apply Normalization
norm1 = norm('norm1', pool1, lsize=4)
# Apply Dropout
norm1 = tf.nn.dropout(norm1, _dropout)
# Convolution Layer
conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2'])
# Max Pooling (down-sampling)
pool2 = max_pool('pool2', conv2, k=2)
# Apply Normalization
norm2 = norm('norm2', pool2, lsize=4)
# Apply Dropout
norm2 = tf.nn.dropout(norm2, _dropout)
# Convolution Layer
conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3'])
# Max Pooling (down-sampling)
pool3 = max_pool('pool3', conv3, k=2)
# Apply Normalization
norm3 = norm('norm3', pool3, lsize=4)
# Apply Dropout
norm3 = tf.nn.dropout(norm3, _dropout)
#conv4
conv4 = conv2d('conv4', norm3, _weights['wc4'], _biases['bc4'])
# Max Pooling (down-sampling)
pool4 = max_pool('pool4', conv4, k=2)
# Apply Normalization
norm4 = norm('norm4', pool4, lsize=4)
# Apply Dropout
norm4 = tf.nn.dropout(norm4, _dropout)
# Fully connected layer
dense1 = tf.reshape(norm4, [-1, _weights['wd1'].get_shape().as_list()[0]]) # Reshape conv3 output to fit dense layer input
dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1') # Relu activation
dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation
# Output, class prediction
out = tf.matmul(dense2, _weights['out']) + _biases['out']
return out
# Store layers weight & bias
weights = {
'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])),
'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])),
'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])),
'wc4': tf.Variable(tf.random_normal([2, 2, 256, 512])),
'wd1': tf.Variable(tf.random_normal([2*2*512, 1024])),
'wd2': tf.Variable(tf.random_normal([1024, 1024])),
'out': tf.Variable(tf.random_normal([1024, 10]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([64])),
'bc2': tf.Variable(tf.random_normal([128])),
'bc3': tf.Variable(tf.random_normal([256])),
'bc4': tf.Variable(tf.random_normal([512])),
'bd1': tf.Variable(tf.random_normal([1024])),
'bd2': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# Construct model
pred = customnet(x, weights, biases, keep_prob)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})
print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
# Calculate accuracy for 256 mnist test images
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.})下面我們執行測試 我們的custom自定義net網路吧
下面是執行的截圖



最後 精度為89 所以網路設計 是有很多值得考慮的事情 這個後面可能會講到
