
R語言︱線性混合模型理論與案例探究(固定效應&隨機效應)
http://blog.csdn.net/sinat_26917383/article/details/51636011
線性混合模型與普通的線性模型不同的地方是除了有固定效應外還有隨機效應。
筆者認為一般統計模型中的橫截面迴歸模型中大致可以分為兩個方向:一個是互動效應方向(調節、中介效應)、一個是隨機性方向(固定效應、隨機效應)。
兩個方向的選擇需要根據業務需求:
互動效應較多探究的是變數之間的網路關係,可能會有很多變數,多變數之間的關係;
而隨機性探究的是變數自身的關聯,當需要著重顧及某變數存在太大的隨機因素時(這樣的變數就想是在尋在內生變數一樣,比如點選量、不同人所在地區等)才會使用。具體見:
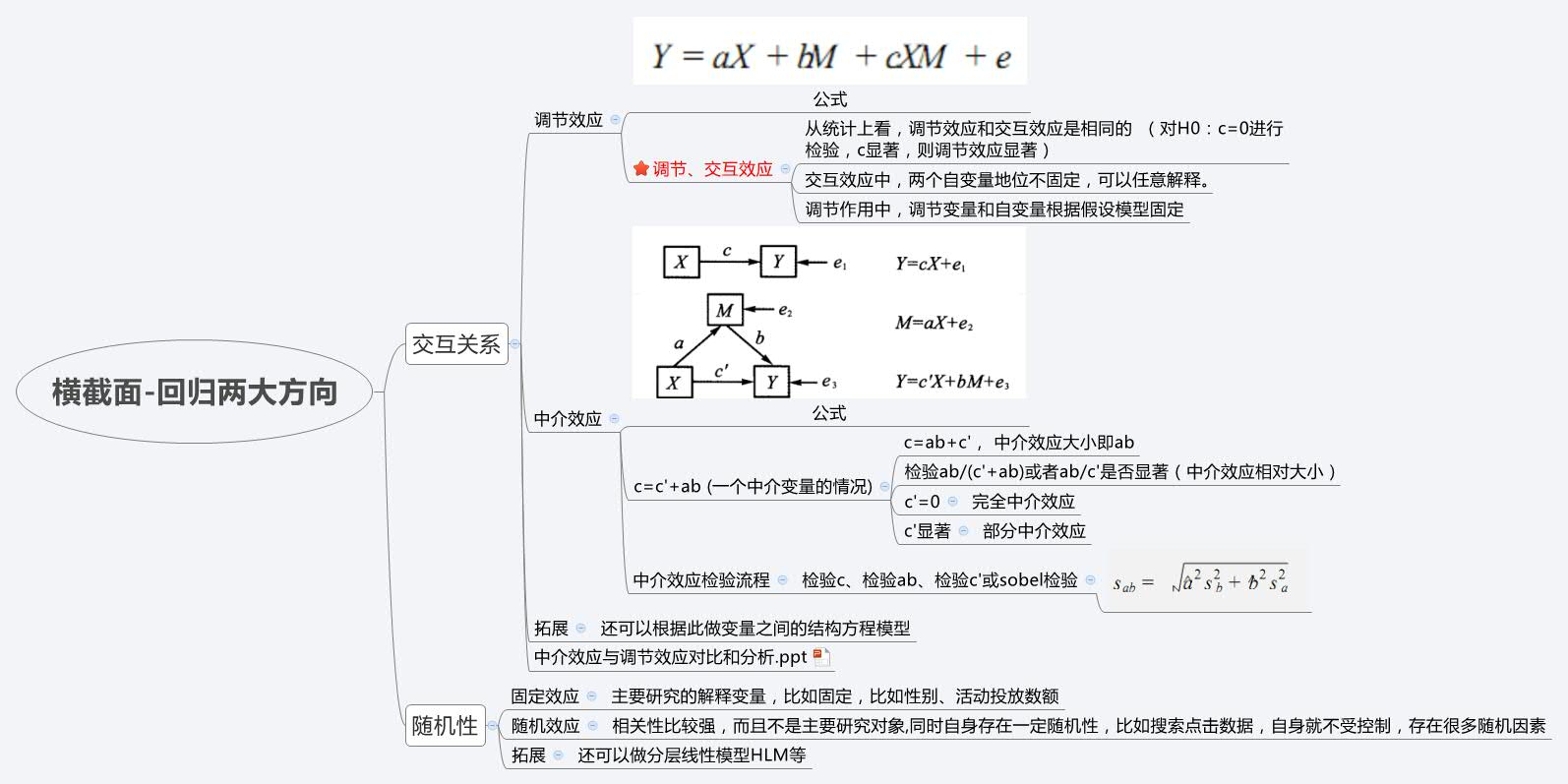
___________________________________________________________________________________
一、線性混合模型理論
普通的線性迴歸只包含兩項影響因素,即固定效應(fixed-effect)和噪聲(noise)。噪聲是我們模型中沒有考慮的隨機因素。而固定效應是那些可預測因素,而且能完整的劃分總體。例如模型中的性別變數,我們清楚只有兩種性別,而且理解這種變數的變化對結果的影響。
那麼為什麼需要
Mixed-effect Model?因為有些現實的複雜資料是普通線性迴歸是處理不了的。例如我們對一些人群進行重複測量,此時存在兩種隨機因素會影響模型,一種是對某個人重複測試而形成的隨機噪聲,另一種是因為人和人不同而形成的隨機效應(random effect)。如果將一個人的測量資料看作一個組,隨機因素就包括了組內隨機因素(noise)和組間隨機因素(random effect)。這種巢狀的隨機因素結構違反了普通線性迴歸的假設條件。
你可能會把人員(組間的隨機效應)看作是一種分類變數放到普通線性迴歸模型中,但這樣作是得不償失的。有可能這個factor的level很多,可能會用去很多自由度。更重要的是,這樣作沒什麼意義。因為人員ID和性別不一樣,我們不清楚它的意義,而且它也不能完整的劃分總體。也就是說樣本資料中的路人甲,路人乙不能完全代表總體的人員ID。因為它是隨機的,我們並不關心它的作用,只是因為它會影響到模型,所以不得不考慮它。因此對於隨機效應我們只估計其方差,不估計其迴歸係數。
混合模型中包括了固定效應和隨機效應,而隨機效應有兩種方式來影響模型,一種是對截距影響,一種是對某個固定效應的斜率影響。前者稱為
Random intercept model,後者稱為 Random Intercept and Slope Model。Random intercept model的函式結構如下
Yij = a0 + a1*Xij + bi + eij
a0: 固定截距
a1: 固定斜率
b: 隨機效應(隻影響截距)
X: 固定效應
e: 噪聲
混合線性模型有時又稱為多水平線性模型或層次結構線性模型由兩個部分來決定,固定效應部分+隨機效應部分.
(以上內容來源於資料探勘入門與實戰公眾號)
1、模型簡述
混合線性模型有時又稱為多水平線性模型或層次結構線性模型由兩個部分來決定,固定效應部分+隨機效應部分。
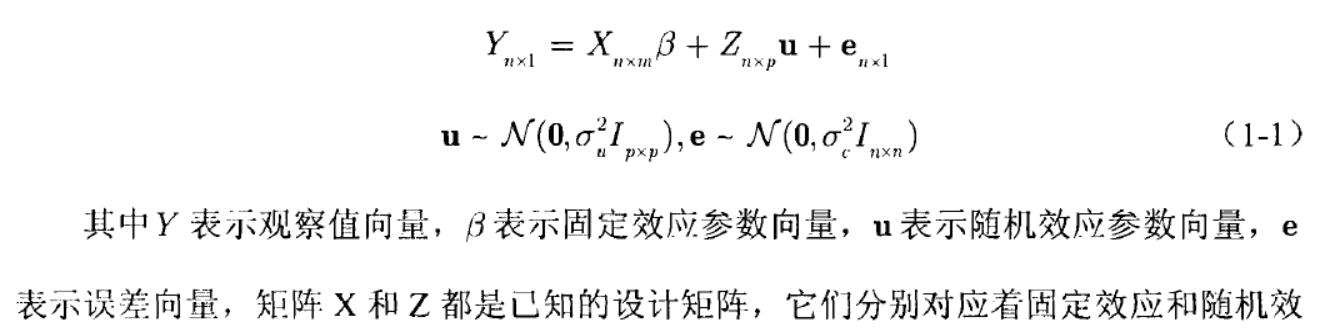
2、協方差結構
來源於論文混合線性模型的應用(該論文涉及到兩個案例),為了減少混合線性模型中方差協方差矩陣中引數的個數,統計學家提供了一些方差協方差矩陣(Y)的系統結構模式供實際工作應用。
常見的協方差結構有:

3、與普通線性迴歸模型以及廣義線性模型的區別(參考經管之家論壇帖子)
(1)線性迴歸模型,適用於自變數X和因變數Y為線性關係,具體來說,畫出散點圖可以用一條直線來近似擬合。一般線性模型要求觀測值之間相互獨立、殘差(因變數)服從正態分佈、殘差(因變數)方差齊性
(2)線性混合模型,線上性模型中加入隨機效應項,消了觀測值之間相互獨立和殘差(因變數)方差齊性的要求。
(3)廣義線性模型,是為了克服線性迴歸模型的缺點出現的,是線性迴歸模型的推廣。首先自變數可以是離散的,也可以是連續的。離散的可以是0-1變數,也可以是多種取值的變數。廣義線性模型又取消了對殘差(因變數)服從正態分佈的要求。殘差不一定要服從正態分佈,可以服從二項、泊松、負二項、正態、伽馬、逆高斯等分佈,這些分佈被統稱為指數分佈族。
關於分佈:因變數的分佈有放寬,但是自變數沒有分佈的要求
與線性迴歸模型相比較,有以下推廣:
a、隨機誤差項不一定服從正態分佈,可以服從二項、泊松、負二項、正態、伽馬、逆高斯等分佈,這些分佈被統稱為指數分佈族。
b、引入聯接函式$g(\cdot )$。因變數和自變數通過聯接函式產生影響。根據不同的資料,可以自由選擇不同的模型。大家比較熟悉的Logit模型就是使用Logit聯接、隨機誤差項服從二項分佈得到模型。
(4)與分層線性模型(HLM)的區別。
介於線性模型與分層線性模型之間,線性混合模型平行地以加入解釋變數的形式加入了隨機效應,分層線性模型是以係數項為二層迴歸引入了隨機效應。分層線性模型較之線性混合模型更具隨機性。
___________________________________________________________________________________
二、R語言中的線性混合模型
來自部落格R中的線性混合模型介紹(翻譯部落格)(來自科學網鄧飛部落格)原來來自:http://www.r-bloggers.com/linear-mixed-models-in-r/
1、nlme lme4 Asreml包
R中有很多軟體包可以做混合線性模型,這裡我只介紹nlme、lme4和ASreml(對!ASreml是商業版,但是還有對應的R包),這些都是基於Reml的演算法,當然還有一些包是基於貝葉斯的演算法,這部分在其他章節介紹。
幾個包的介紹:
|
包 |
優點 |
缺點 |
|
nlme |
這是一個比較成熟的R包,是R語言安裝時預設的包,它除了可以分析分層的線性混合模型,也可以處理非線性模型。在優勢方面,個人認為它可以處理相對複雜的線性和非線性模型,可以定義方差協方差結構,可以在廣義線性模型中定義幾種分佈函式和連線函式。 |
它的短板: |
|
lme4 |
lme4包是由Douglas Bates開發,他也是nlme包的作者之一,相對於nlme包而言,它的執行速度快一點,對於睡覺效應·隨機效應的結構也可以更復雜一點,但是它的缺點也和nlme一樣 |
1、不能處理協方差和相關係數結構 |
|
ASReml-R |
ASReml-R是ASReml的R版本,它的優點: |
主要的缺點: |
2、R語言案例
資料來源:一個傳統的裂區資料來說明不同軟體包的用法,這個資料oats是在MASS包中,是研究大麥品種和N肥處理的裂區試驗,其中品種為主區,肥料為裂區。
- library(MASS)
- data(oats)
- names(oats) = c('block', 'variety', 'nitrogen', 'yield')
3、nlme包
用這個包很簡單,y-變數寫在左邊,然後是固定因子,然後是隨機因子,注意1|block/mainplot是裂區試驗殘差的寫法,因為裡面有兩個殘差。程式碼如下:
- library(nlme)
- m1.nlme = lme(yield ~ variety*nitrogen,
- random = ~ 1|block/mainplot,
- data = oats)
- summary(m1.nlme)
方差分析結果為:
- anova(m1.nlme)
- numDF denDF F-value p-value
- (Intercept) 1 45 245.14333 <.0001
- variety 2 10 1.48534 0.2724
- nitrogen 3 45 37.68561 <.0001
- variety:nitrogen 6 45 0.30282 0.9322
如果假設認為這些調查物件是同質的,也就是個體間沒有差異性,那麼可以將資料完全彙集(complete pooling)到一起,直接利用lm函式進行迴歸。但這個混合效應模型的同質假設往往不成立,資料彙集導致過度簡化。另一種思路是假設研究的異質性,將不同的個體分別進行迴歸,從而得到針對特定個體的估計值,這稱為不彙集(no pooling)。但這種方法導致每個迴歸所用到的樣本減少,從而難以估計統計量的標準差。
多層迴歸模型的思路是前兩者的折中,所以又稱為部分彙集(partial pooling)。在R語言中我們使用mgcv包中的lmer函式來完成這項工作。首先載入faraway包以便讀取psid資料集,然後載入mgcv包,再將年份資料中心化以方便解釋模型,最後用lmer函式進行建模。
4、lme4包
lme4包的語法也相似,隨機效應有著和nlme相同的語法,不同的是lme4包它的結果給出了隨機效應的標準差,而不是方差。
- library(lme4)
- m1.lme4 = lmer(yield ~ variety*nitrogen + (1|block/mainplot),
- data = oats)
- summary(m1.lme4)
- anova(m1.lme4)
lmer函式使用和lm是類似的,一般變量表示固定效應,括號內豎線右側的person表示它是一個隨機效應,它與模型中其它變數相加,而且與年份cyear變數相乘,影響其斜率。這就是一個隨機效應模型。如果認為隨機效應隻影響模型截距,那麼固定效應迴歸模型可以用下面的公式
5、ASReml-R包
它的功能很強大,用在這裡有些殺雞用牛刀的感覺。程式碼如下:- library(asreml)
- m1.asreml = asreml(yield ~ variety*nitrogen,
- random = ~ block/mainplot,
- data = oats)
- summary(m1.asreml)$varcomp
- wald(m1.asreml)
___________________________________________________________________________________
三、線性混合模型解讀
1、難點
建模前提:資料服從正態分佈的假設;
固定、隨機效應變數選擇:哪些變數歸類到隨機效應(相關性比較強,而且不是主要研究物件,同時自身存在一定隨機性,比如搜尋點選資料,自身就不受控制,存在很多隨機因素);固定效應(主要研究的解釋變數)。
協方差結構的選擇:可以利用AIC、BIC指標來判斷,常見的有8個協方差結構。
2、案例一:論文《混合線性模型的應用》的案例解讀
模型為:成績(被解釋變數)=性別(固定效應)+地區(隨機效應)
協方差結構的選擇:將隨機引數向量的方差協方差矩陣設定為無結構型。
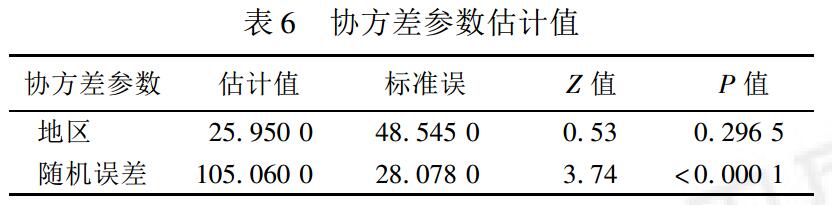
剩餘誤差ε的方差估計值為105.06,地區隨機效應的方差估計值g=25.95,但無統計學意義,表示地區間的變異不大( 由於樣本含量較小之故)。比較這 2 個值的大小反映考試成績在同一地區內學生間的變異大於地區間的變異。為了更好地解釋模型,仍將地區隨機效應保留在模型中。
一個學生的考試成績的總方差為105.06+25.95,可以估計出組內相關係ρ=25.95/(105.06+25.95)=0.1980,這表示同一地區學生考試成績的聚集性達到近,20%。
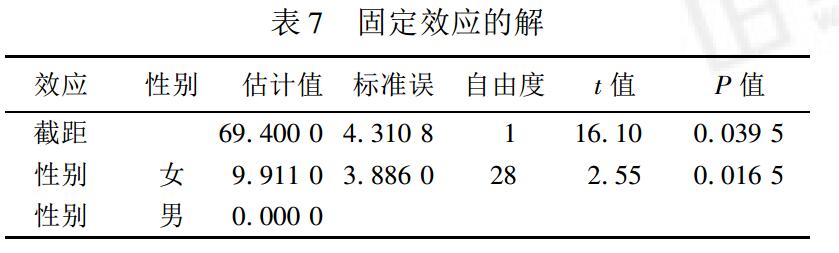
固定效應變數性別對學生考試影響的引數估計值為9.911,具有統計學意義。男生的平均成績預報值為69.4分,女生的平均成績預報值為69.4+9.91=79.31分。這一預報值是控制地區變異後的結果,不同於模型中的條件平均預報值。