
Bagging,Random Forests以及Boosting
為了防止分類迴歸樹陷入過擬合,我們有一系列改善措施來提高樹的效能,常見的有Bagging和Random Forests以及Boosting演算法。首先來了解一下什麼是Bootstrap。
Bootstrap是一種資料抽樣方法,最普通的單一樹的生成過程是利用所有訓練資料進行劃分然後產生決策枝幹,而Bootstrap的做法是在訓練資料中去抽樣資料重新獲得訓練資料集,即從原始訓練資料集去可重複地抽樣n個樣本來作為新的訓練資料集,從而訓練得到一個決策樹。
通過Bootstrap抽樣方法產生B個新的訓練集,從而可以運用不同的資料集訓練得到B個不同的決策樹,然後對於輸入資料x,我們可以由這B個不同的決策樹去投票來決定最終的分類結果。這種演算法稱為Bagging或Bootstrap aggregation,Bagging演算法可以顯著地提高單一決策樹的效能,Bagging是很多樹的投票結果,因此可以使得決策邊界變得更加平滑了。例如下面一組Bagging的結果與單一決策樹形狀對比。
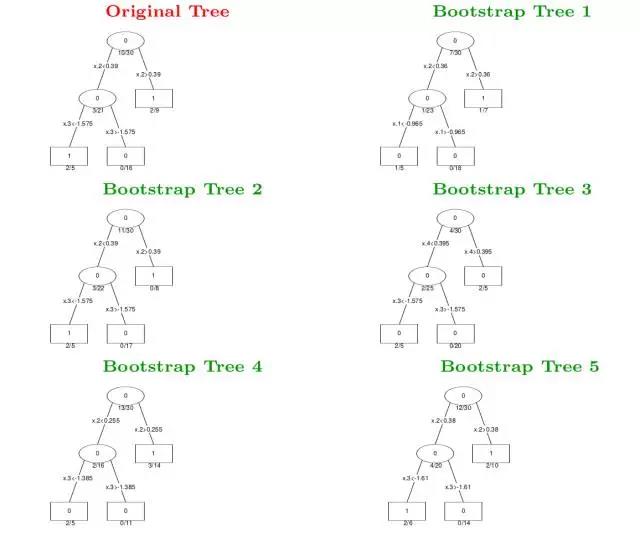
值得注意的是,在Bagging中,由於Bootstrap抽樣會使得一些樣本無法抽到,那麼這些樣本將作為測試樣本得到測試誤差,該誤差又稱為”out-of-bagging”誤差。
隨機森林(Random Forests,簡稱RF)演算法是在Bagging演算法的基礎上再做修正的,RF的做法是在每一步劃分時,假設一共有m個特徵屬性,只從中隨機挑選log2(m)或sqrt(m)個特徵來計算劃分熵,而其他的步驟和Bagging是一樣的。
Boosting演算法是在Bagging的基礎上引入權重因子,即對每個決策樹加一個修正權重,最終的分類器是所有分類器的權重和。
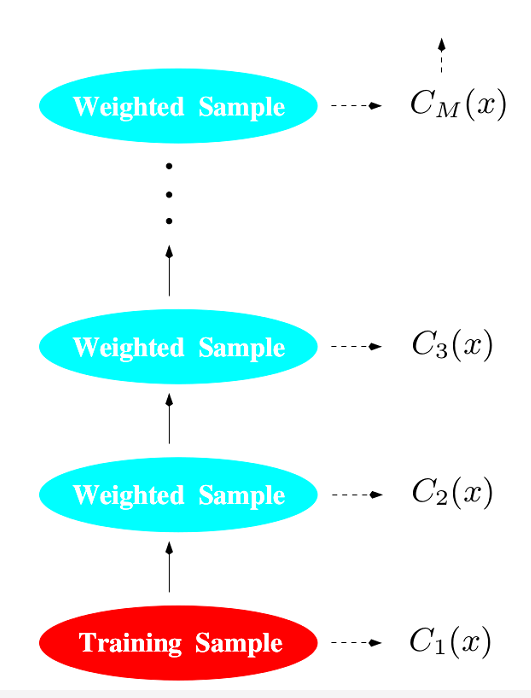
Boosting演算法具體流程如下:
1、首先,假設有N個觀察樣本(即測試樣本,或out-of-bagging樣本),初始化權重為w_i=1/N;
2、對於M個分類器,重複以下四步:
(1)訓練一個樹分類器C_m;
(2)計算該樹分類器的權重誤差
Err_m=SUM(w_i*I(y_i!=C_m(x_i)))/SUM(w_i);
(3)計算alpha_m=log[(1-Err_m)/Err_m];
(4)更新N個權重
w_i=w_i*exp[alpha_m*I(y_i!=C_m(x_i))]
並且歸一化所有w,得到新的w_i;
3、計算分類樹的最終輸出C(x)=sign[SUM(alpha_m*C_m(x))];
這裡的SUM是指對下標進行求和,I是誤差函式。