
手把手教你如何應用TF-Slim快速實現遷移學習
這是一篇以實踐為主的入門文章,目的在於用盡量少的成本組織起來一套可以訓練和測試自己的分類任務的程式碼,其中就會用到遷移學習,TF-Slim庫的內容,所以我們分為下面幾個步驟介紹:
什麼是遷移學習;
什麼是TF-Slim;
TF-Slim實現遷移學習的例程;
應用自己的資料集完成遷移學習。
實驗環境:Win10+Python3.5+TensorFlow1.1
什麼是遷移學習:
一般在初始化CNN的卷積核時,使用的是正態隨機初始化,此時訓練這個網路的話就是在從頭訓練,然而既然反正都要初始化核引數,那麼為什麼不乾脆拿一個在其他任務中訓練好的引數進行初始化呢?一般認為如果一個網路在某個更為複雜的任務上表現優異的話(這需要大量的資料與長時間的訓練),那麼它的引數是具有比較好的特徵抽取能力的,又因為CNN的前幾層提取的一般為較低階的特徵(邊緣,輪廓等),所以這些引數即使換一個任務的話,也會有不錯的效果(起碼在前幾層是這樣,而且起碼比正態隨機初始化要好)。在一個數據量比較大的任務中完成訓練的過程就是pre-train,用pre-train的引數初始化一個新的網路,並對這些引數再次訓練(微調),使之適用於新任務的過程就是fine-tune。一般情況下,我們會選擇ImageNet資料集上訓練好的網路,因為它經過大資料量與長時間的訓練。好在TensorFlow已經提供了各種
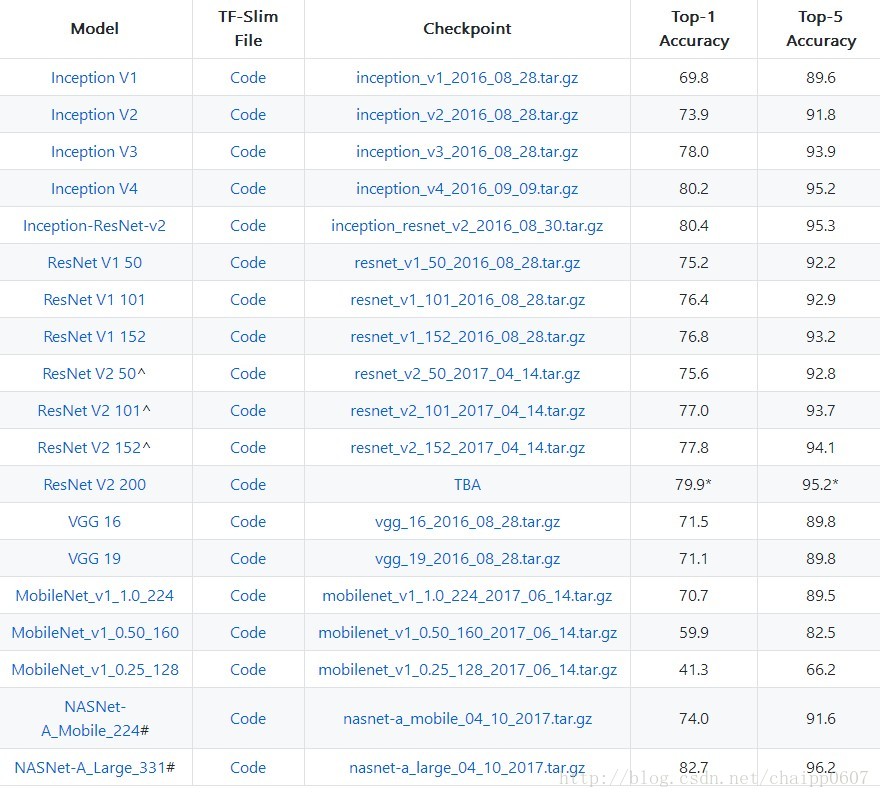
然後我們舉個例子說下Google是怎麼訓練這些模型,在ImageNet資料集上,用128GB記憶體+8個NVIDIA Tesla K40 GPU訓練Inception網路,耗時100個小時,Top1達到73.5%。
什麼是TF-Slim
TF-slim是用於定義,訓練和評估複雜模型的TensorFlow(tensorflow.contrib.slim)的新型輕量級高階API。 可以把它理解為TensorFlow提供的一種更高階的封裝吧,其實它和遷移學習沒什麼關係,只是在後面的內容中會用到,所以在這裡提一下。具體內容可以點選這裡檢視,其翻譯版可點選這裡。
TF-Slim實現遷移學習的例程
在TensorFlow的github網址中提供了一個包含了資料準備+訓練+預測的例程—Flowers,它只需我們執行幾個指令碼或命令列,不需要該任何程式碼就可以,我們先把這個例程解釋一下:
1.準備工作:
首先我們需要再https://github.com/tensorflow/models把TensorFlow-models下載下來,放在本地一個位置上,比如D盤根目錄。
2.轉化TFRecord檔案:
TFRecord檔案是一種TensorFlow提供的資料格式,它可以將圖片二進位制資料和圖片其他資料(如標籤,尺寸等等)儲存在同一個檔案中,有種格式更加利於TensorFlow的讀取機制。所以我們需要先生成Flowers資料集的TFRecord檔案。
TensorFlow-models內提供了一個
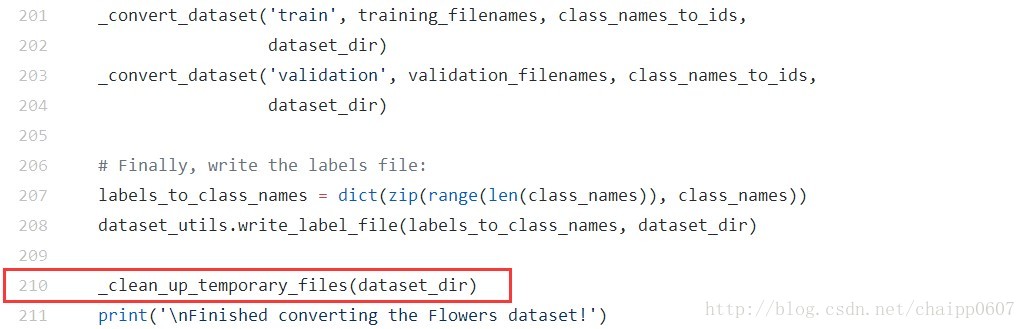
然後我們就可以執行這個檔案了,注意一下我們要執行的是download_and_convert_data.py檔案,要修改的是download_and_convert_flowers.py檔案。因為我的系統是Windows,所以在這裡我就直接使用命令行了,使用Linux的同學可以直接執行.sh檔案,我們只需要進入slim後執行:
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=D:/models-master/research/slim/flowers_5其中floewers_5是資料夾的名字,程式碼將在該檔案加內下載flowers資料集的壓縮包,解壓後生產TFRecord檔案,壓縮包大小大概有200多M的樣子吧。


下載完成之後,程式碼會隨機的抽取350張圖片組成驗證集,剩下的3320張組成訓練集,並分別打成5個TFRecord檔案。
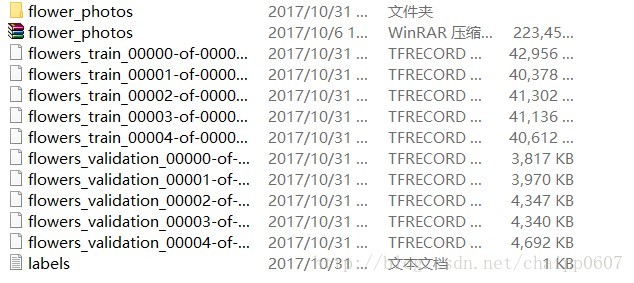
再回到floewers_5資料夾中,我們就可以看到下面這些東西,一個壓縮檔案,一個解壓縮之後的資料夾,10個TFRecord檔案和一個labels檔案。
3.遷移Inception-V4訓練新任務
資料集準備完成後,我們就可以進行訓練,這裡使用TF提供的Inception-V4網路,首先我們需要在上面提到的那個圖裡下載下來Inception-V4模型檔案解壓縮,我放在了D:\models-master\research\slim\pre_train下。
然後我們可以直接執行train_image_classifier.py檔案:
python train_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_5
--checkpoint_path=D:/models-master/research/slim/pre_train/inception_v4.ckpt
--model_name=inception_v4
--checkpoint_exclude_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--trainable_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--train_dir=D:/models-master/research/slim/flowers_5/my_train
--learning_rate=0.001
--learning_rate_decay_factor=0.76
--num_epochs_per_decay=50
--moving_average_decay=0.9999
--optimizer=adam
--ignore_missing_vars=True
--batch_size=32
執行結果:
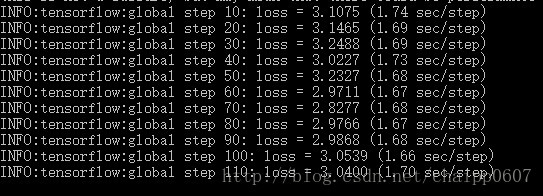
4.準確率驗證
短暫的訓練之後,我們就可以測試下驗證集上的準確率了,執行eval_image_classifier.py檔案:
python eval_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_5
--dataset_split_name=validation
--model_name=inception_v4
--checkpoint_path=D:/models-master/research/slim/flowers_5/my_train
--eval_dir=D:/models-master/research/slim/flowers_5/validation_result
--batch_size=32
可以看到,一個5分類資料集經過短暫的訓練後,top1只有17%,top5沒有意義,必然是1。
應用自己的資料集完成遷移學習
在上面我們沒有改動一行程式碼(改了一行是為了方便看資料),就完成了從資料準備到訓練再到預測的全部過程,現在終於到了最關鍵的地方,就是怎麼跑通我們自己的資料集,在組織資料的過程中,最天然的方式肯定就是按照資料的類別放進不同的資料夾裡,這也就是為什麼我們要選擇Flowers這個資料集,下面我們就把剛剛下載的資料刪除一個類別,重新重複一遍剛才的過程,在下面的過程中我們需要修改一些程式碼。
1.準備工作:
把之前下載並解壓的flower_photos資料夾複製到新建的flower_4資料夾中,把玫瑰的資料刪掉,這樣我們的資料就變成了4分類,圖片總數為3028個,順便把flower_photos資料夾的名字改成my_photo。
2.轉化TFRecord檔案:
修改download_and_convert_flowers.py檔案程式碼如下:
43行 _NUM_VALIDATION = 300 //驗證集的圖片數量
49行 _NUM_SHARDS = 4 //TFRecord的數量
83行 flower_photos換成my_photo //資料的資料夾名稱
註釋190行 //不再下載資料集
註釋210行 //不刪除壓縮檔案和解壓縮後的檔案命令列換成如下,然後執行:
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=D:/models-master/research/slim/flowers_4再回到floewers_4資料夾中,我們就可以看到下面這些東西,我們放進去的my_photo檔案,8個TFRecord檔案和一個labels檔案。
3.遷移Inception-V4訓練新任務:
修改檔案flowers.py程式碼如下:
34行SPLITS_TO_SIZES = {'train': 2728, 'validation': 300} //資料個數
36行 _NUM_CLASSES = 4 // 類別數修改命令列執行train_image_classifier.py檔案:
python train_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_4
--checkpoint_path=D:/models-master/research/slim/pre_train/inception_v4.ckpt
--model_name=inception_v4
--checkpoint_exclude_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--trainable_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--train_dir=D:/models-master/research/slim/flowers_4/my_train
--learning_rate=0.001
--learning_rate_decay_factor=0.76
--num_epochs_per_decay=50
--moving_average_decay=0.9999
--optimizer=adam
--ignore_missing_vars=True
--batch_size=32
4.準確率驗證:
測試新的資料,不需要修改程式碼,改下命令列就可以了:
python eval_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_4
--dataset_split_name=validation
--model_name=inception_v4
--checkpoint_path=D:/models-master/research/slim/flowers_4/my_train
--eval_dir=D:/models-master/research/slim/flowers_5/validation_result
--batch_size=32

可以看到,由於我們的資料少了1分類,top1也上升到了24%。
到這裡,我們只修改了7行程式碼和對應的命令列檔案就完成一個從資料準備到最後測試的過程,當代碼跑通之後,我們就可以回去看原始碼了,然後可以重新組織和修改程式碼建立一個自己的工程。