
Hbase架構以及原理
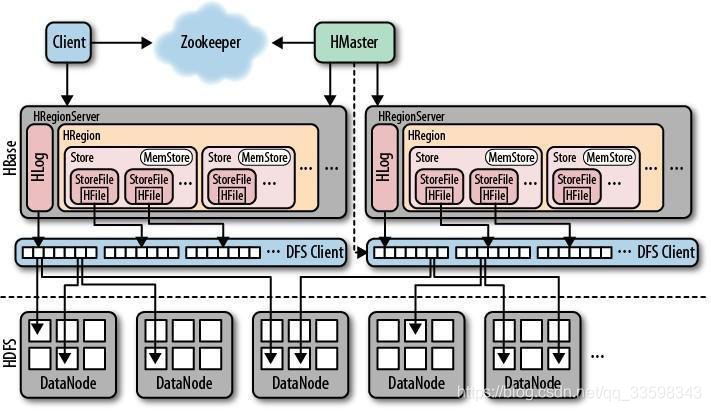
HMaster:
1.為Region server分配region
2.負責Region server的負載均衡
3.發現失效的Region server並重新分配其上的region。
4.HDFS上的垃圾檔案回收。
5.處理schema更新請求。
HRegionServer:
HMaster在功能上主要負責Table表和HRegion的管理工作,具體包括:
1、管理使用者對Table表的增、刪、改、查操作;
2、管理HRegion伺服器的負載均衡,調整HRegion分佈;
3、在HRegion分裂後,負責新HRegion的分配;
4、在HRegion伺服器停機後,負責失效HRegion伺服器上的HRegion遷移。
HRegion:儲存資料,以Rowkey方向來劃分多個Region(看下面-root-和-meta-的詳解的時候就明白了)
Store:為一個儲存單元,為column familly,一個列族的所有資訊
MemStore:是一個記憶體區域
Hlog:記錄操作資訊,保證資料完整性
StoreFile:是hbase中的資料檔案,而HFile是它的資料儲存的實體
StoreFile以HFile格式儲存在HDFS上。HFile是Hadoop的二進位制格式檔案。實際上StoreFile就是對HFile做了輕量級包裝,即StoreFile底層就是HFile
讀資料的時候:
大致流程:
Client訪問Zookeeper獲得的元資料,然後去指定的HRegionServer中的HRegion查詢資料,首先去MemStore去看看有沒有,有就直接返回,沒有就去StoreFile找。

詳細流程:
Client通過ZK獲得-ROOT-表的位置,然後訪問它獲得-META-表中對應的Region的位置,然後去讀,請求先到MemStore中查資料,查不到就到BlockCache中查,再查不到就會到StoreFile上讀,並把讀的結果放入BlockCache,快取返回資料。

寫資料的時候:
大致流程:

Client獲得Zookeeper儲存的HMaster返回的元資料資訊,去指定的HRegionServer中的HRegion下,首先是把Log寫入到HLog中,HLog是標準的Hadoop Sequence File,由於Log資料量小,而且是順序寫,速度非常快;同時把資料寫入到記憶體MemStore中,成功後返回給Client,所以對Client來說,HBase寫的速度非常快,因為資料只要寫入到記憶體中,就算成功了。
接著檢查MemStore是否已滿,如果滿了,就把記憶體中的MemStore Flush到磁碟上,形成一個新的StoreFile。
當Storefile檔案的數量增長到一定閾值後,系統會進行合併(Compact),在合併過程中會進行版本合併和刪除工作,形成更大的storefile。
當Storefile大小超過一定閾值後,會把當前的Region分割為兩個(Split),並由Hmaster分配到相應的HRegionServer,實現負載均衡
-ROOT- 與-MATE-

HBase的所有Region元資料被儲存在.META.表中,隨著Region的增多,.META.表中的資料也會增大,並分裂成多個新的Region。為了定位.META.表中各個Region的位置,把.META.表中所有Region的元資料儲存在-ROOT-表中,最後由Zookeeper記錄-ROOT-表的位置資訊。所有客戶端訪問使用者資料前,需要首先訪問Zookeeper獲得-ROOT-的位置,然後訪問-ROOT-表獲得.META.表的位置,最後根據.META.表中的資訊確定使用者資料存放的位置,如下圖所示。

ROOT-表永遠不會被分割,它只有一個Region,這樣可以保證最多隻需要三次跳轉就可以定位任意一個Region。為了加快訪問速度,.META.表的所有Region全部儲存在記憶體中。客戶端會將查詢過的位置資訊快取起來,且快取不會主動失效。如果客戶端根據快取資訊還訪問不到資料,則詢問相關.META.表的Region伺服器,試圖獲取資料的位置,如果還是失敗,則詢問-ROOT-表相關的.META.表在哪裡。最後,如果前面的資訊全部失效,則通過ZooKeeper重新定位Region的資訊。所以如果客戶端上的快取全部是失效,則需要進行6次網路來回,才能定位到正確的Region。