
Large scale GAN training for high fidelity natural image synthesis解讀
《Large scale GANtraining for high fidelity natural image synthesis》這篇文章對訓練大規模生成對抗網路進行了實驗和理論分析,通過使用之前提出的一些技巧,如資料截斷、正交正則化等,保證了大型生成對抗網路訓練過程的穩定性。本文訓練出的模型在生成資料的質量方面達到了前所未有的高度,遠超之前的方法。作者對生成對抗網路訓練時的穩定性進行了分析,藉助於矩陣的奇異值分析。此外,還在生成資料的多樣性與真實性之間做了折中。總體來說,本文的工作相當紮實,雖然沒有大的方法上的創新,但卻取得了非常好的效果,對穩定性的分析也有說服力。
摘要
儘管最近幾年在生成式影象建模上取得了進步,但從ImageNet這樣的複雜資料集生成高解析度、多樣化的影象仍然是一個具有挑戰性的工作。為了達到這一目標,本文作者訓練了到目前為止最大規模的生成對抗網路(BigGAN),並對這種規模下的網路在訓練時的不穩定性進行了研究。作者發現,將正交正則化用於生成器網路能夠起到很好的效果,通過對隱變數的空間進行截斷處理,能夠在樣本的真實性與多樣性之間進行精細的平衡控制。本文提出的方法在類別控制的影象生成問題上取得了新高。如果用ImageNet的128x128解析度影象進行訓練,BigGAN模型生成影象的Inception得分達到了166.3,FID為9.6。
整體簡介
得益於生成對抗網路的出現,生成式影象建模演算法在最近幾年取得了大的進步,可以生成真實的、多樣性的影象。這些演算法直接從樣本資料進行學習,然後在預測階段輸出生成的影象。GAN的訓練是動態的,並且對演算法設定的幾乎每個方面都很敏感,從神經網路的結構到優化演算法的引數。對於這一問題,人們進行了大量的持續的研究,從經驗到理論層面,以確保訓練演算法在各種設定下的穩定性。儘管如此,之前最好的演算法在條件式ImageNet資料建模上的Inception得分為52.5,而真實資料的得分為233,還有很大的差距。
本文的工作致力於減小GAN生成的影象與ImageNet資料集中的影象在真實性與多樣性之間的差距。為了解決此問題,本文提出瞭如下幾個主要的創新:
證實了增大GAN的規模能夠顯著的提升建模的效果,在這裡,模型的引數比之前增大了2-4倍,訓練時的batch尺寸增加了8倍。文章提出了兩種簡單而又具有一般性的框架改進,可以提高模型的伸縮性,並且改進了一種正則化策略來提升條件作用,證明了這些方法能夠提升效能。
作為這些修改策略的副產品,本文提出的模型變得更服從截斷技巧。截斷技巧是一種簡單的取樣方法,能夠在樣本的逼真性、多樣性之間做顯式的、細粒度的控制。
發現了使大規模GAN不穩定的原因,對它們進行了經驗性的分析,更進一步的,作者發現將已有的和新的技巧的組合使用能夠降低這種不穩定性。但是完全的訓練穩定性只有在巨大的效能代價下才能獲得。對穩定性的分析通過對生成器和判別器權重矩陣的奇異值分析而實現。
文章提出的這些修改技巧顯著的提升了class-conditional GAN的效能。實現時,用128x128的ImageNet資料集進行訓練, Inception得分和Frechet Inception距離在之前最好的方法上有了顯著的提升。另外,還在256x256和512x512的解析度下訓練了模型。此外,還在自己的樣本集上進行了訓練,證明了本文提出的方法具有通用性。
下圖為本文的演算法所生成的影象,達到了以假亂真的地步:

背景知識
生成對抗網路由一個生成器G和一個判別器D組成,前者的作用是根據隨機噪聲資料生成逼真的隨機樣本,後者的作用是鑑別樣本是真實的還是生成器生成的。在最早的版本中,GAN訓練時的優化目標為達到如下極大值-極小值問題的納什均衡:
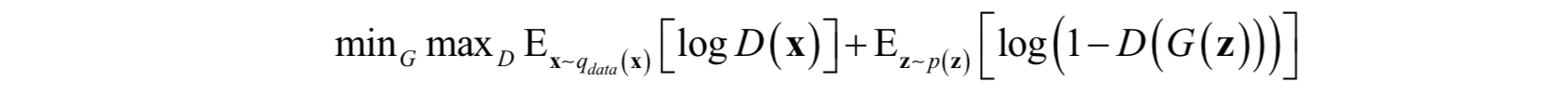
其中Z∈Rdz為隱變數,是一個隨機向量,從概率分佈p(z)產生,如正態分佈N(0,1)或均勻分佈U(-1,1)。當用於影象類任務時,G和D一般是卷積神經網路。如果不使用一些輔助性的增加穩定性技巧,訓練過程非常脆弱,收斂效果差,需要精細設計的超引數和網路結構的選擇以保證效果。
之前的相關工作
近期的研究工作集中在修改初始的GAN演算法,使得它更穩定。這些方法中,既有經驗性的分析,也有理論性的分析。其中一種思路是修改訓練時的目標函式以確保收斂。另外一種思路是通過梯度懲罰或歸一化技術對D進行限定,這兩種方法都是在抵抗對無界的目標函式的使用,確保對任意的G,D都能提供梯度。
與文字的方法非常相關的是譜歸一化(Spectral Normalization),它強制D的Lipschitz 連續性,這通過對它們的最大奇異值進行執行時動態估計,以此對D的引數進行歸一化而實現。另外還包括逆向動力學,對主奇異值方向進行自適應正則化。文獻[1]分析了G的雅克比矩陣的條件數,發現GAN的表現依賴於此條件數。文獻[2]發現將譜歸一化作用於G能夠提高穩定性,使得訓練演算法每次迭代時能夠減小D的迭代次數。本文對這些方法進行了進一步分析,以弄清GAN訓練的機理。
另外一些工作聚焦在網路結構的選擇上。SA-GAN增加了一種稱為self-attention的模組來增強G和D的能力。ProGAN通過使用逐步增加的解析度的影象訓練單個模型。
條件GAN為GAN增加了類資訊,作為生成器和判別器的輸入。類資訊可以採用one hot編碼,和隨機噪聲拼接起來,作為G的輸入。另外,可以在批量歸一化層中加入。另外,在D中也加入了類別資訊。
最後要說的是評價指標,這和資料生成一樣困難,目前常用的是IS和FID,本文對演算法的比較採用了這兩個指標。
Inception Score 使用瞭如下兩種評判標準來檢驗模型的表現:
-
生成圖片的質量
-
生成圖片的多樣性
其計算方式如下:
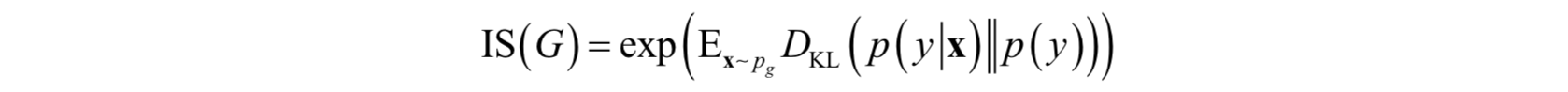
其中y為類別標籤,x為樣本向量,pg為生成器生成的樣本所服從的概率分佈,DKL為KL散度。IS的值越大越好。p(y)是生成圖片的類別y關於生成器G(z)的邊緣概率分佈:
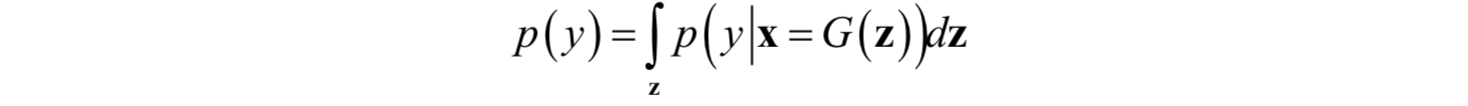
![]()
如果生成圖片的類別只有一種,那麼生成影象的IS依然會很高,這是IS顯著的缺點。而Fréchet Inception Distance(FID)相較於IS更加適合用於圖片生成質量的評價,與IS不同,越小的值意味著更好的生成圖片的質量以及更豐富的圖片的多樣性。在所有生成的影象僅為一種類別時,其取值將會很高。FID的計算方式是使用Inception網路中的某一層的特徵,並使用多元高斯分佈對提取的特徵進行建模。假設訓練樣本對應的特徵featx ~N(μx,∑x),生成圖片對應的特徵featg ~N(μg,∑g)則:

tr為矩陣主對角線元素之和,即矩陣的跡。
增大GAN的規模
本文的重點是探討增大模型的規模,訓練樣本的batch尺寸來獲得性能上的提升。作為基礎模型,選用了SA-GAN,使用hinge loss目標函式。通過class-conditional BatchNorm為G提供類資訊,通過projection為D提供類資訊。優化器的設定與文獻[4]相同,對G使用了譜歸一化,但學習率減半,G每迭代一次,D迭代兩次。另外,使用了正交初始化和 Xavier初始化。每個模型按照輸出影象解析度來選用對應數量核數的TPU進行訓練,如輸出128x128解析度的影象就使用128個核TPU進行訓練。值得注意的是,G的批量歸一化是在對所有裝置一起進行的,而不是每個裝置單獨做自己的歸一化。
首先做的是增大batch的尺寸,並立刻發現這種做法所帶來的效果。下表的前面4行列出了不同batch尺寸時的得分:

從上表中的第二行和第五行記錄了在不使用任何其他文中提到的改進措施情況下,batch size 分別為256 和2048時的實驗結果。可以看出,在batch size增大8倍之後,IS就獲得了46%的提升。作者推斷這是因為batch size增大之後,每個batch中的資料覆蓋到的模式更多,一場能為生成器和判別器提供更好的梯度。但是,單純的增加batch size帶來了非常明顯的副作用:在迭代次數較少的情況下,效果反而更好,如果繼續訓練,訓練過程不再穩定,並出現訓練坍塌的現象。關於這個現象的原因將在下文的分析部分詳細剖析。
接下來所做的是增加網路的寬度,即通道數,每一個層增加50%,網路的引數因此增加了一倍。這樣做帶來了21%的IS提升。增加網路的深度則沒有帶來這樣的效能改善,反而,在ImageNet資料集上導致了效能的下降。作者認為這是因為在引數增加的情況下,模型的能力相對於資料集的複雜度過剩導致的。與增加batch size不同的是,增加寬度並不會導致訓練坍塌的情況出現,只會帶來效能的下降。
由於G的條件BatchNorm層有大量的引數,本文沒有采用這種做法。本文選擇了共享的類嵌入,線性投影到各個層的gains和biases,在減小了計算需求和記憶體需求的情況下,訓練速度提升了37%。另外,還使用了層次隱變數空間,具體做法是將噪聲向量送人到G的多個層中,而不只是輸入層。使用這種方法可以是的不同解析度不同層級的特徵被噪聲向量直接影響。
用截斷技巧在真實性和多樣性之間做折中
生成器的隨機噪聲輸入一般使用正態分佈或者均勻分佈的隨機數。本文采用了截斷技術,對正態分佈的隨機數進行截斷處理,實驗發現這種方法的結果最好。對此的直觀解釋是,如果網路的隨機噪聲輸入的隨機數變動範圍越大,生成的樣本在標準模板上的變動就越大,因此樣本的多樣性就越強,但真實性可能會降低。首先用截斷的正態分佈N(0,1)隨機數產生噪聲向量Z,具體做法是如果隨機數超出一定範圍,則重新取樣,使得其落在這個區間裡。這種做法稱為截斷技巧:將向量Z進行截斷,模超過某一指定閾值的隨機數進行重取樣,這樣可以提高單個樣本的質量,但代價是降低了樣本的多樣性。下圖證明了這一點:

通過這種截斷處理,可以在生成的資料的真實性和多樣性之間進行折中。
另外還對生成器使用了正交性條件,這種正則化定義為:

其中W是權重矩陣,β是超引數。這種正則化限定性太強,本文實現時做了一些修改,保證在放鬆約束的同時模型又具有光滑性。實驗中發現效果最好的是:

其中,1是元素值全為1的矩陣。這種簡單的正則化旨在最小化filter之間的餘弦相似度,對效能有顯著的提升。
總結
實驗結果發現,現有的GAN技巧已經足以訓練處大規模的、分散式的、大批量的模型。儘管這樣,訓練時還是容易坍塌,實現時需要提前終止。
分析
這一段對GAN的穩定性進行了分析,著重探索了影響穩定性的因素,並給出了一些解決方案。對穩定性的分析通過對權重矩陣的奇異值進行分析而實現。作者對生成器和判別器的穩定性分別進行了分析。
生成器的不穩定性
對於GAN的穩定性,之前已經有一些探索,從分析的角度。本文著重對小規模時穩定,大規模時不穩定的問題進行分析。實驗中發現,權重矩陣的前3個奇異值σ0,σ1,σ2蘊含的資訊最豐富。
在訓練中,G的大部分層的譜範數都是正常的,但有一些是病態的,這些譜範數隨著訓練的進行不斷的增長,最後爆炸,導致訓練坍塌。如下圖所示:

為了確定上面的結論糾結是導致訓練坍塌的原因,還是僅僅只是一個現象,在這裡對G使用了正交正則化方法,抵抗譜爆炸問題。首先,對各個權重的最大奇異值直接進行正則化。其次,用部分奇異值分解對最大特徵值進行截斷處理。給定權重矩陣W,它的第一個奇異向量u0以及v0,σclamp為σ0為截斷後的值。權重的更新公式為:

![]()
在實驗中發現,無論是否做譜歸一化,上面這種技巧都可以防止奇異值的逐步增長和爆炸。這也證明了光使用這種技巧無法保證訓練的穩定性,因此還需要考慮判別器D。
判別器的不穩定性
和生成器G一樣,這裡也通過分析判別器D的權重矩陣的譜來揭示其行為,然後通過新增一些額外的約束條件來穩定其訓練過程。通過觀察D的σ0發現,和G不同的是,D的譜有很多噪聲,σ0/σ1的表現很正常,奇異值在整個訓練過程中會增長,在崩潰時會發生跳躍,而不是爆炸。
D的譜的峰值表明,它週期性的接收大的梯度,但Frobenius範數卻是光滑的。意味著這種作用主要集中在最大的幾個奇異方向。作者設想,這種噪聲是最優化演算法在對抗訓練過程中產生的,因為G會週期性的產生強烈擾動D的批次樣本。如果這種譜噪聲與不穩定性有因果關係,那麼一個很自然的解決辦法是使用梯度懲罰,顯式的對D的雅克比矩陣的變化進行正則化。實驗中使用了下面的懲罰項:![]()
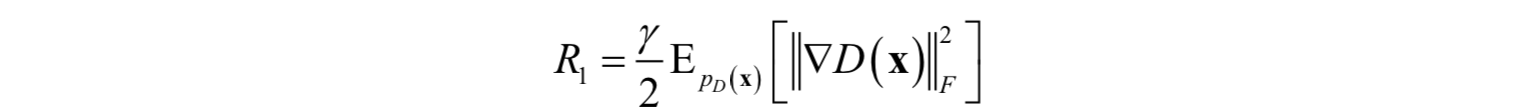
其中γ的值設定為10。結果訓練變得穩定,並且提高了G和D的譜的光滑性和有界性。但效能卻嚴重退化,IS值降低了45%。降低懲罰值部分的緩解了這種退化,但增加了病態譜。用各種不同強度的正交正則化,dropout,L2正則化重複這種實驗,揭示了類似的行為。即加大懲罰項,訓練變得穩定,但效能變差。
另外,在實驗中還觀察到在訓練中D的損失函式降到了0,但在崩潰發生時會發生尖銳的反彈即向上的跳躍。對這一現象的一種解釋是D發生了過擬合,記住了之前的訓練樣本,而不是學習生成的樣本和真實樣本之間的有意義的分類邊界。為了測試D的記憶,用ImageNet的訓練和測試集對沒有崩潰的判別器進行了效能測試,並統計多少比例的樣本被判定為真實的或生成的。結果是,對訓練樣本集的準確率是98%,對測試樣本集的準確率是50-55%,和隨機猜測沒有什麼區別。這證明D確實記住了訓練樣本,作者認為這與D的角色一致,不是顯式的進行泛化,而是提取訓練樣本集,為G提供有用的訓練訊號。
總結
作者得出的結論是,穩定性不單單來源於G或者D,而是兩者在對抗訓練過程中相互作用的結果。它們病態條件的症狀可以用來跟蹤和鑑別不穩定性,確保合理的條件被證明對於訓練是必須的但對防止訓練崩潰時不充分的,即必要不充分。對D進行嚴格的限制能確保穩定性,但會嚴重損失最終生成的資料的質量。以現有的技術,可以放寬這個條件並允許崩潰在訓練出一個好的結果之後發生和達到更好的資料生成效果。

實驗
在實驗中,作者使用了ImageNet和自己的資料集作為評測,與之前的方法進行了比較。下面分別進行介紹。
ImageNet上的結果
作者用ImageNet ILSVRC 2012資料集對模型進行了驗證,包括128x128,256x256,以及512x512三種解析度。生成器和判別器的網路結構如下圖所示:

引數設定為下表第8行:

對於128X128解析度的模型,生成器和判別器的網路結構如下圖所示:![]()

最後的結果如下表所示:

本文提出的方法能夠在生成的樣本的質量和多樣性之間組折中,不同的IS下,可以得到不同的FID。IS-FID曲線如下圖所示:


內部資料集上的結果
為了驗證本文提出的方法對更復雜、更大規模、更多樣性的資料集也有效,作者在自己內部的資料集上也進行了測試。這個資料集有292M張影象,包括8.5K個類。比ImageNet大兩個數量級。有些影象有多個標籤,即輸入多個類,對這種情況,作者隨機從這些標籤中選擇一個使用。為了計算在這個樣本集上訓練的GAN的IS和FID,作者使用了在這個樣本集上訓練的Inception v2分類器。實驗結果如下表所示:

所有模型在訓練時的batch尺寸都是2048。
總結
本文證明了將GAN用於多類自然影象生成任務時,加大模型的規模可以顯著的提高生成的影象的質量,對生成的樣本的真實性和多樣性都是如此。通過使用一些技巧,本文提出的方法的效能較之前的方法有了大幅度的提高。另外,還分析了大規模GAN在訓練時的機制,用它們的權重矩陣的奇異值來刻畫它們的穩定性。討論了穩定性和效能即生成的影象的質量之間的相互作用和影響。
參考文獻
[1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair,
and Aaron Courville Yoshua Bengio. Generative adversarial nets. In NIPS, 2014.
[2] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. In NIPS, 2016.