
資料分析師的月薪是多少?爬取一家網站給大家看看
這是我在論壇看到的一篇文章,寫的確實非常不錯。很受用。所以拿出來分享給大家。如果有地方沒做好,還希望大家多多包含。在分享之前呢。我給大家推薦一下我自己弄的python群:960410445 不管是大牛還是小白我都非常歡迎。群裡有些學習資料。適合小白相對來講多些。群裡也有人解答問題。大家可以一起交流。大牛做的小專案。原始碼也是有一部分的。歡迎初學者和進階者還有大牛者進群,進入一個大家庭!






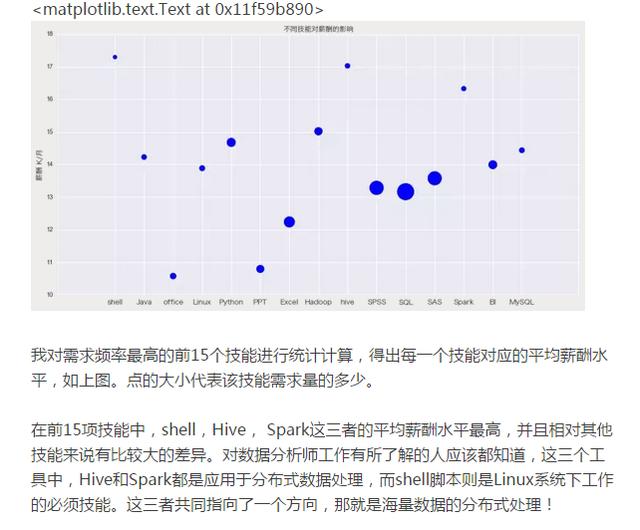


相關推薦
資料分析師的月薪是多少?爬取一家網站給大家看看
這是我在論壇看到的一篇文章,寫的確實非常不錯。很受用。所以拿出來分享給大家。如果有地方沒做好,還希望大家多多包含。在分享之前呢。我給大家推薦一下我自己弄的python群:960410445 不管是大牛還是小白我都非常歡迎。群裡有些學習資料。適合小白相對來講多些。群裡也有人解答問題。大家可
JAVA 爬取指定網站的資料並存入MySQL資料庫中 maven +httpclient+jsoup+mysql
最近在做一個小專案,因為要用的資料爬取,所以研究了好多天,分享一下自己的方法 目錄結構: 自己建立maven工程,匯入相關依賴:pom.xml <?xml version="1.0" enco
JAVA 爬取新聞網站的資料,httpclient和jsoup。
建立maven工程目錄: pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.
爬取動態網站資料(soup的css方式處理資料)
import requests from bs4 import BeautifulSoup url = 'https://knewone.com/discover?page=' def get_in
爬取Aliexpress網站的商品資料,儲存至excel表格
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017/4/19 10:43 # @Author : WuFan import bs4 import requests import re import xlwt import date
Python爬蟲scrapy框架爬取動態網站——scrapy與selenium結合爬取資料
scrapy框架只能爬取靜態網站。如需爬取動態網站,需要結合著selenium進行js的渲染,才能獲取到動態載入的資料。如何通過selenium請求url,而不再通過下載器Downloader去請求這個url?方法:在request物件通過中介軟體的時候,在中介軟體內部開始
爬取攜程和螞蜂窩的景點評論資料\攜程評論資料爬取\旅遊網站資料爬取
本人長期出售超大量微博資料、旅遊網站評論資料,並提供各種指定資料爬取服務,Message to [email protected]。同時歡迎加入社交媒體資料交流群:99918768 前言 為了獲取多源資料需要到各個網站獲取一些景點的評論資訊
爬取小說網站整站小說內容 -《狗嗨默示錄》-
exception chap color row con print 動漫 pri value # !/usr/bin/env python # -*- coding: utf-8 -*- import urllib.request import re import M
webmagic爬取渲染網站
pat sleep 分析 最終 sets 開發者 src ner 分享 最近突然得知之後的工作有很多數據采集的任務,有朋友推薦webmagic這個項目,就上手玩了下。發現這個爬蟲項目還是挺好用,爬取靜態網站幾乎不用自己寫什麽代碼(當然是小型爬蟲了~~|)。好了,廢話少說,以
一個爬取法律網站的爬蟲
重連 light str 避免 log nic urllib python 文件的 因為各種原因,需要建立一個法律大全的庫,方便做匹配等。重新拿起了python,發現忘的差不多了。 網上找了一下,這是一個大佬做的一個最簡單的爬蟲,http://www.cnblogs.com
爬取資訊網站的新聞並保存到excel
xls write [] web port fin text doc usr #!/usr/bin/env python#* coding:utf-8 *#author:Jacky from selenium.webdriver.common.keys import Key
python爬蟲-基礎入門-爬取整個網站《1》
python爬蟲-基礎入門-爬取整個網站《1》 描述: 使用環境:python2.7.15 ,開發工具:pycharm,現爬取一個網站頁面(http://www.baidu.com)所有資料。 python程式碼如下: 1 # -*- coding: utf-8 -*- 2 3 i
python爬蟲-基礎入門-爬取整個網站《2》
python爬蟲-基礎入門-爬取整個網站《2》 描述: 開場白已在《python爬蟲-基礎入門-爬取整個網站《1》》中描述過了,這裡不在描述,只附上 python3 的程式碼。 python3 指令碼程式碼: 1 #-*- coding: utf-8 -
python爬蟲-基礎入門-爬取整個網站《3》
python爬蟲-基礎入門-爬取整個網站《3》 描述: 前兩章粗略的講述了python2、python3爬取整個網站,這章節簡單的記錄一下python2、python3的區別 python2.x 使用類庫: >> urllib 庫 >> urlli
Scrapy :爬取培訓網站講師資訊
Scrapy 框架 Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛。 框架的力量,使用者只需要定製開發幾個模組就可以輕鬆的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。 Scrapy 使用
Python爬蟲實戰專案2 | 動態網站的抓取(爬取電影網站的資訊)
1.什麼是動態網站? 動態網站和靜態網站的區別在於,網頁中常常包含JS,CSS等動態效果的內容或者檔案,這些內容也是網頁的有機整體。但對於瀏覽器來說,它是如何處理這些額外的檔案的呢?首先瀏覽器先下載html檔案,然後根據需要,下載JS等額外檔案,它會自動去下載它們,如果我們要爬取這些網頁中的動態
Python爬取小說網站頁面製作電子書
#-*- coding:utf-8 -*- from bs4 import BeautifulSoup from urlparse import urljoin import requests url="http://www.jinyongwang.com/yi/{page}.html
利用Python爬取攝影網站圖片,切勿商用
今天我們繼續爬取一個網站,這個網站為 http://image.fengniao.com/ ,蜂鳥一個攝影大牛聚集的地方,本教程請用來學習,不要用於商業目的,不出意外,蜂鳥是有版權保護的網站。 Python學習資料或者需要程式碼、視訊加Python學習群:9604104
利用scrapy框架遞迴爬取菜譜網站
介紹: 最近學習完scrapy框架後,對整個執行過程有了進一步的瞭解熟悉。於是想著利用該框架對食譜網站上的美食圖片進行抓取,並且分別按照各自的命名進行儲存。 1、網頁分析 爬取的網站是www.xinshipu.com,在爬取的過程中我發現使用xpath對網頁進行解析時總是找不到對應的標籤
Swaggy教你用python實現NBA資料統計的爬取
相信很多喜歡NBA的小夥伴們經常會關注NBA的資料統計,今天我就用虎撲NBA的得分榜為例,實現NBA資料的簡單爬取。https://nba.hupu.com/stats/players是虎撲體育的NBA球員得分榜:當我們右鍵檢視該網站的原始碼時,會發現所有的資料統計都存放在&