
hadoop2.x單機搭建分散式叢集超詳細教程
【前言】
1.個人PC機配置:戴爾,筆記本,記憶體8G,硬碟西數500G,CPU酷睿i5
2.由於工作中需要經常在叢集上做測試,另外我一直想學習大資料,因此結合百度+同事,有了此篇教程,初學者,不足之處,可在下方留言
【準備工作】
下載如下5個軟體:
1.VMware,版本10
2.CentOS系統iso映象,版本6.5
3.Xshell軟體
4.jdk,linux版本1.8
5.hadoop軟體包,版本2.7
【注:為方便起見,教程中所有密碼均設定為123456】
【搭建步驟】
1.安裝VMware軟體
詳見我部落格:
2.安裝CentOS虛擬機器系統以及配置網路和遠端連線
詳見我部落格:
網路設定為NAT模式
部落格中用的是SecureCRT工具,個人目前偏愛Xshell,連線方法很簡單,這裡不贅述
此時ifconfig檢視網絡卡,應該直接有ip了,試著在虛擬機器和本地宿主機ping下:
切換root使用者:
3.關閉虛擬機器防火牆
首先檢視當前防火牆狀態:

關閉防火牆:

檢視iptables服務是否開啟:

重啟虛擬機器:

4.安裝並配置jdk
這部分用root許可權操作
(1)先輸入jave-version檢視當前jdk版本,不是1.8就先刪除已有版本的jdk軟體包:

(2)去oracle官網下載jdk1.8的Linux版本(記得下載rpm自安裝版本),然後上傳到/usr/local/src目錄;

(3)輸入如下命令開始安裝jdk:
rpm -i jdk-8u91-linux-i586.rpm
等待安裝完成
在/usr/java路徑下檢視是否有jdk1.8資料夾:

有就安裝成功了。
(3)配置環境變數,讓系統用1.8版本的jdk:
首先修改系統配置檔案:vi /etc/profile
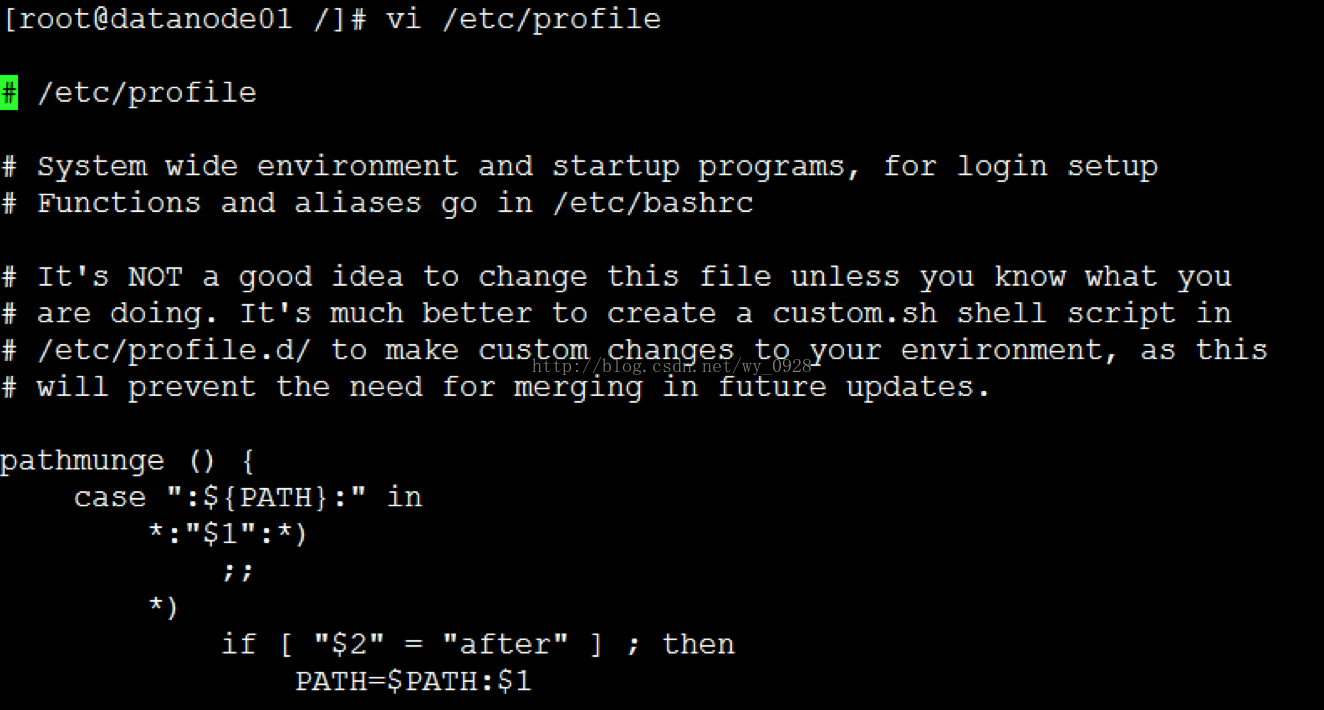
在檔案末尾加上如下幾行(注意等號前後不要留空格):

儲存退出
(4)設定修改後的配置檔案生效:

(5)檢視伺服器當前jdk版本:

至此jdk安裝配置結束。
5.建立hadoop相應的檔案系統
這部分在root許可權下操作
(1)配置hosts檔案,路徑在/etc/hosts:

之後在虛擬機器ping master看看是否通:

(2)檢視虛擬機器系統中是否安裝lvm工具
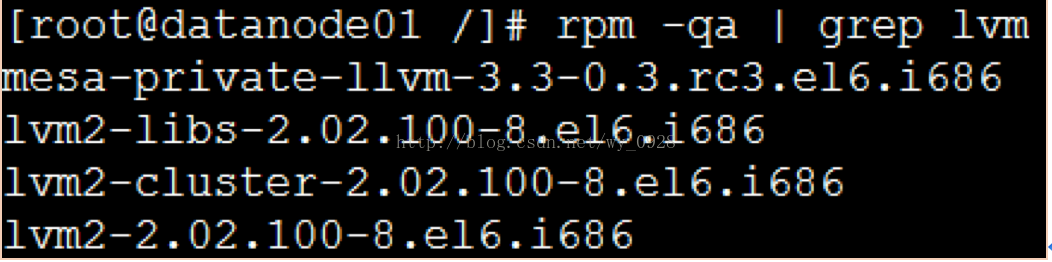
這就表示已安裝。
(3)在虛擬機器中新增3塊硬碟(均為20G)
虛擬機器先關機
a)點選 “編輯虛擬機器設定”---“新增”---“硬碟”---“下一步”,然後一直點選 “下一步”直到完成:
b)接著,重複此操作2遍,會得到以下圖片。最後,點選“確定”並開啟虛擬機器:
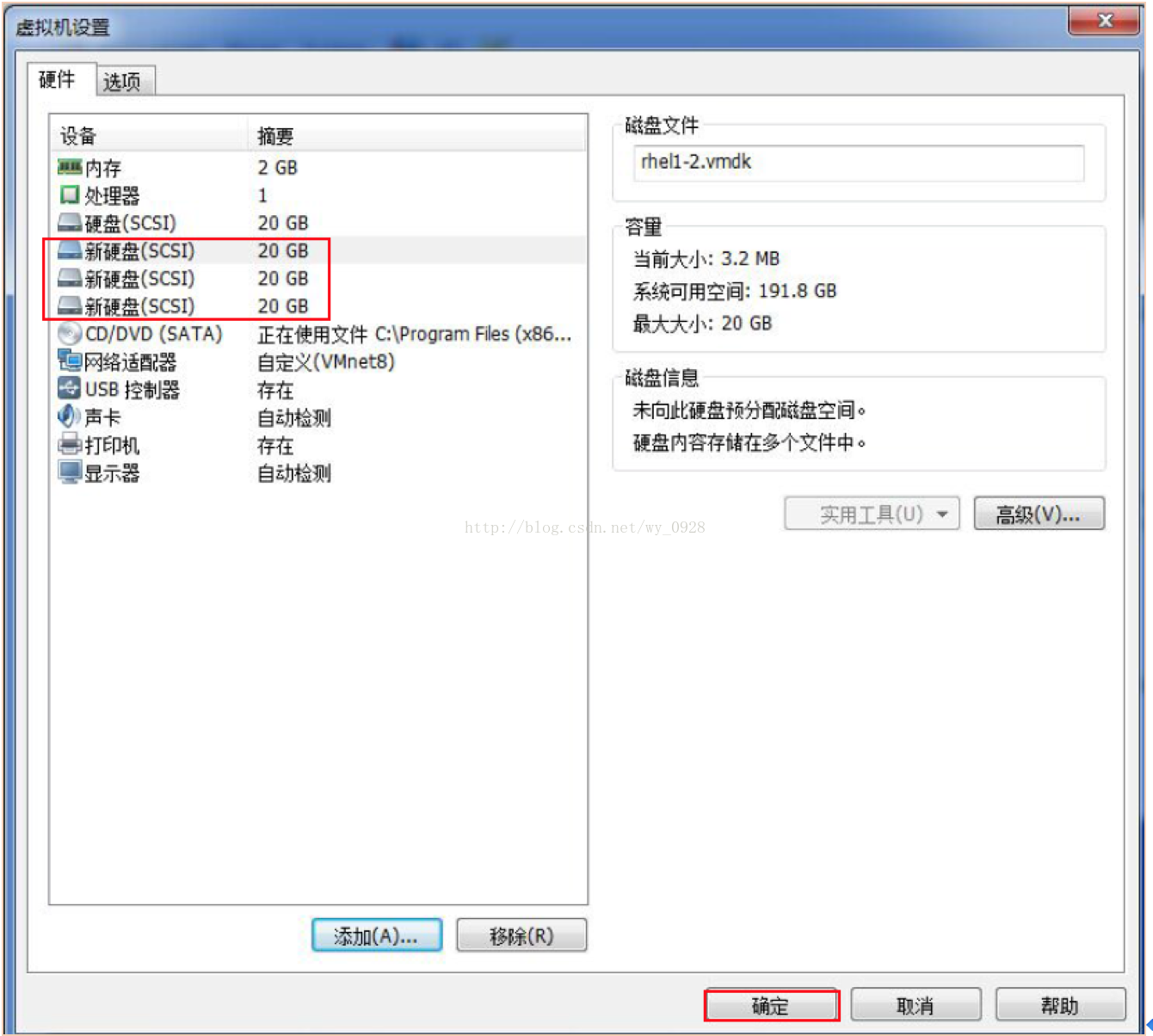
開啟後fdisk -l檢視硬碟是否開啟成功:
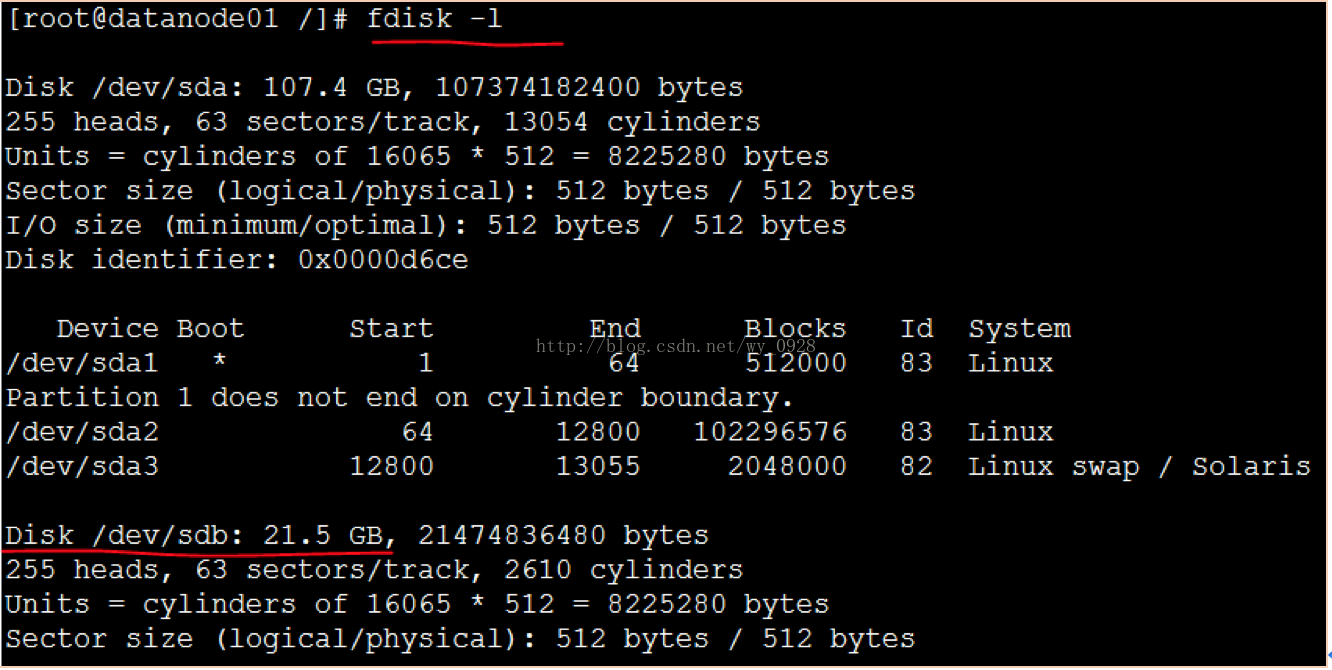
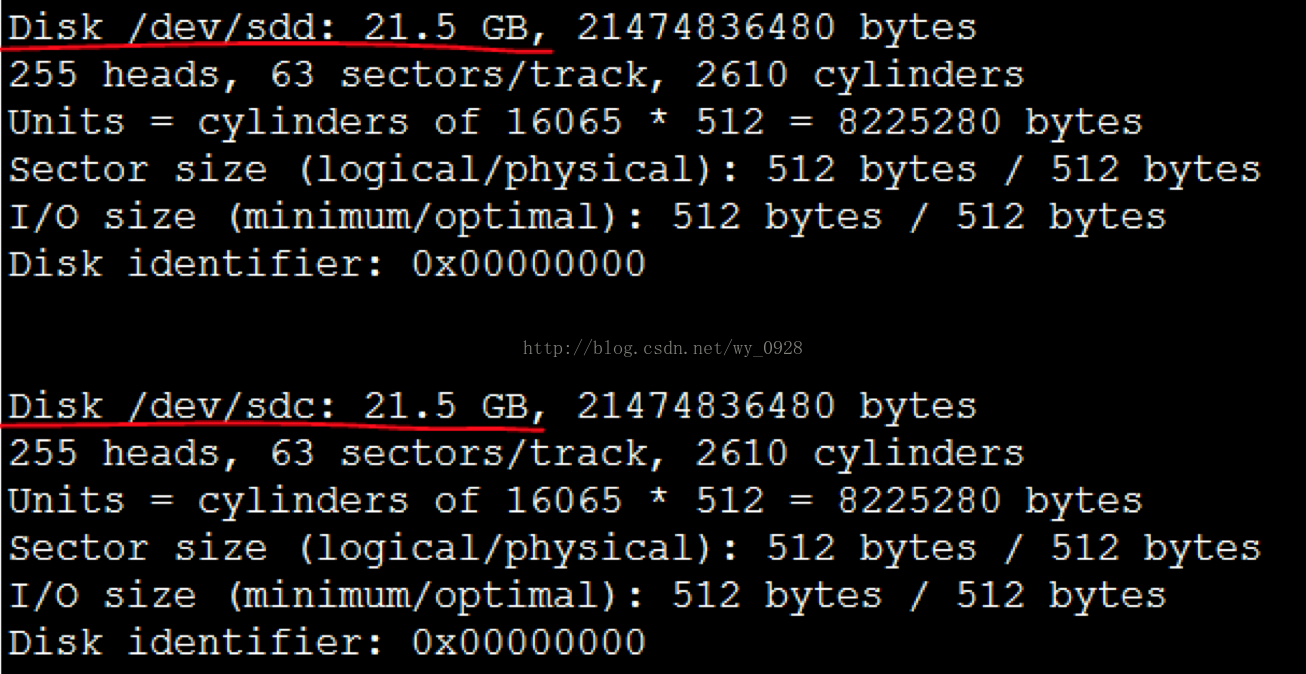
可以看到3個20G的硬碟(sdb、sdc、sdd)
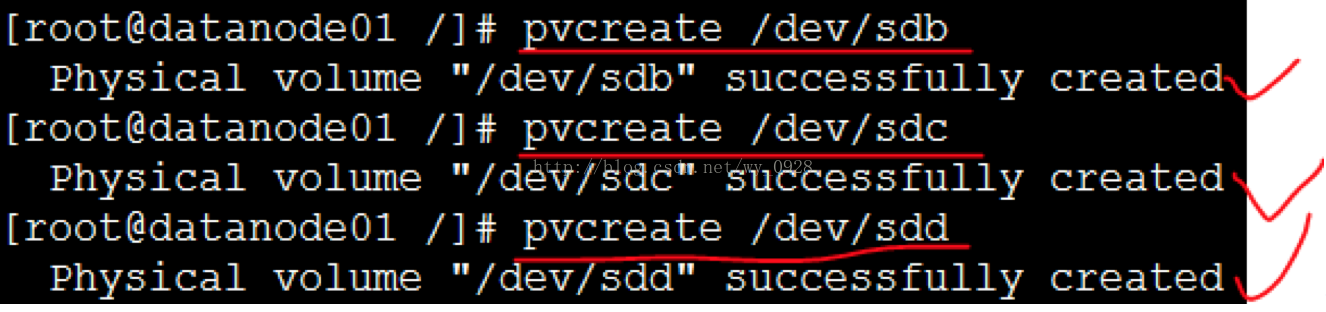
(4)建立物理卷
(pvcreate指令用於將物理硬碟分割槽初始化為物理卷,以便被LVM使用。)
a)使用sdb建立基於sdb的物理卷
pvcreate /dev/sdb
b)使用sdc建立基於sdc的物理卷
pvcreate /dev/sdc
c)使用sdd建立基於sdd的物理卷
pvcreate /dev/sdd
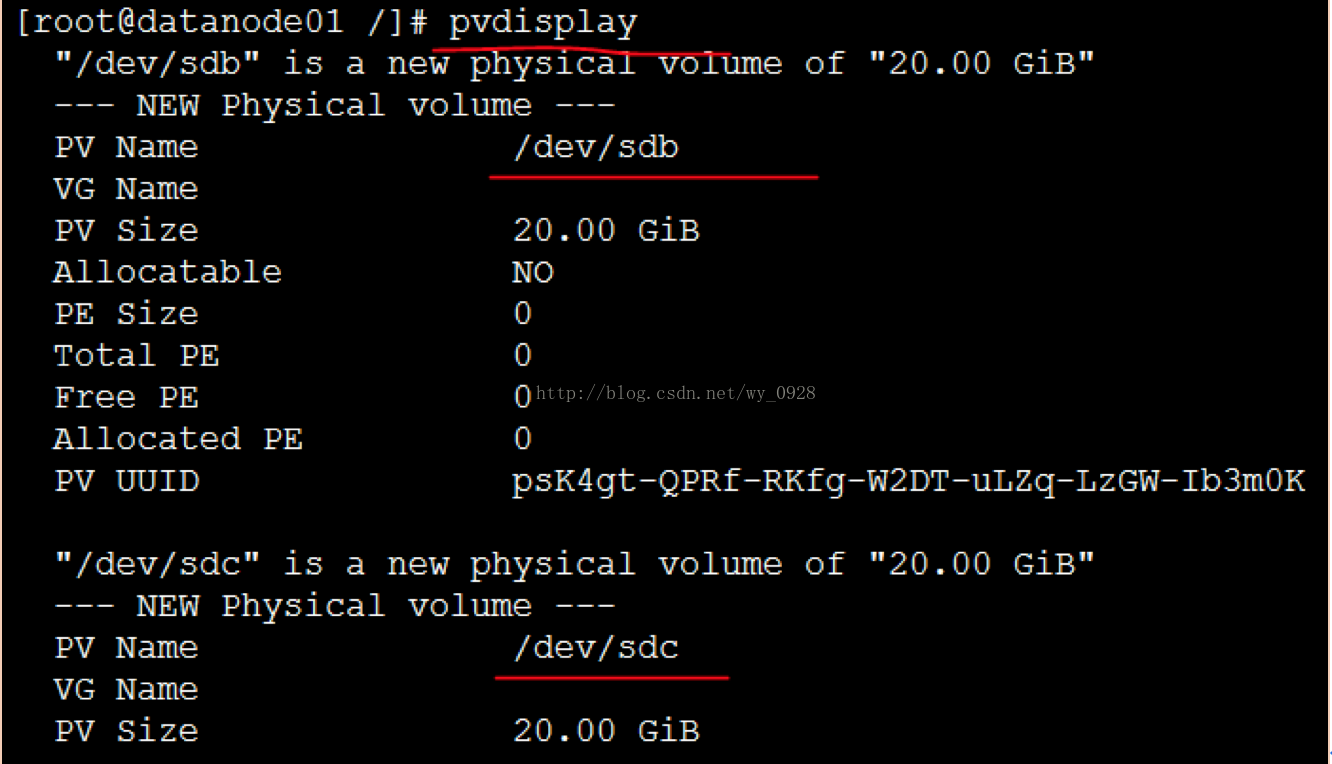
d)檢視物理卷是否建立成功
pvdisplay
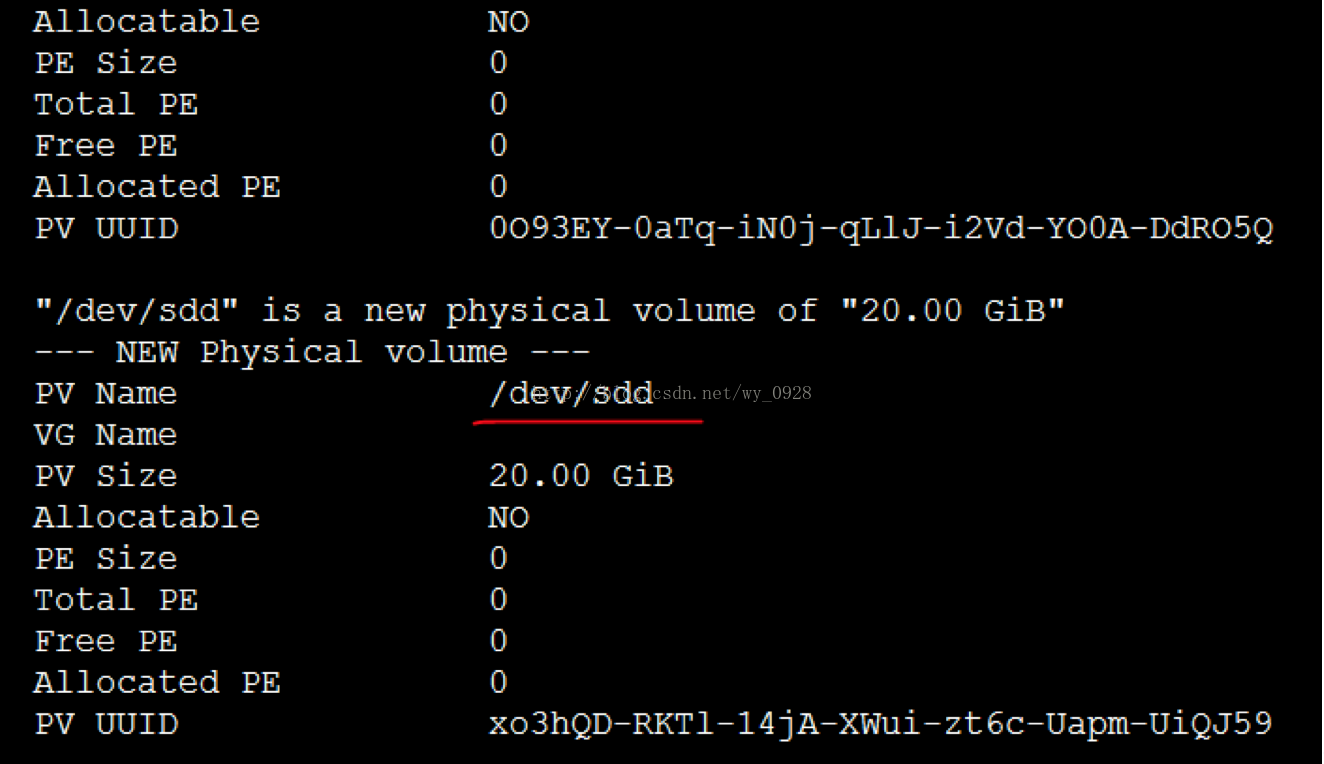
(5)建立卷組和新增新的物理捲到卷組
a)建立一個卷組
vgcreate test_document /dev/sdb
(vgcreate 命令第一個引數是指定該卷組的邏輯名,後面引數是指定希望新增到該卷組的所有分割槽和磁碟)
b)將sdc物理卷新增到已有的卷組(注意vgcreate與vgextend用法的區別)
vgextend test_document /dev/sdc
c)將sdd物理卷新增到已有的卷組(注意vgcreate與vgextend用法的區別)
vgextend test_document /dev/sdd

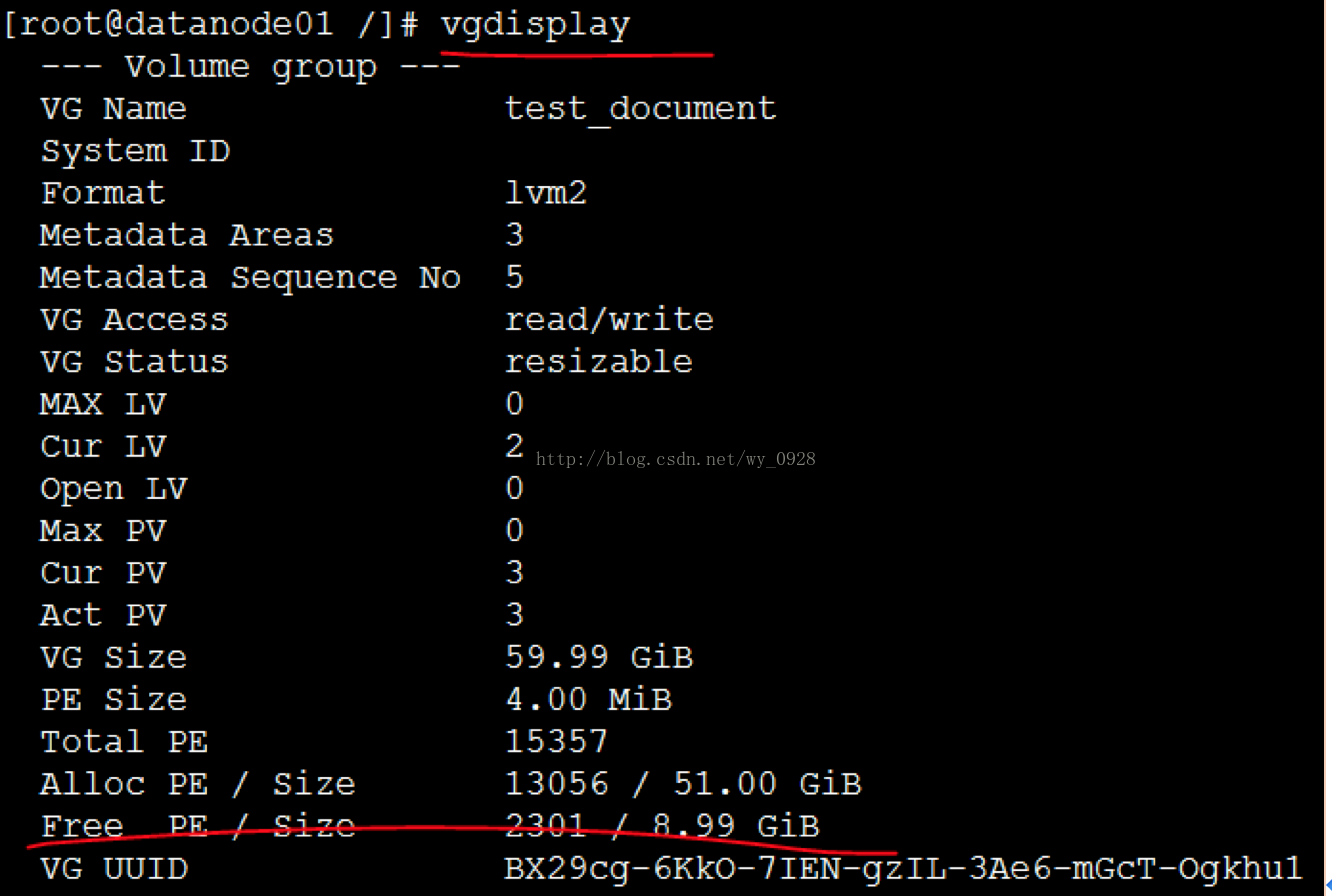
d)檢視卷組大小(發現已經60G了)

(6)啟用卷組

(7)建立邏輯卷
a)lvcreate -L5120 -n lvhadooptest_document
(該命令是在卷組test_document上建立名字為lvhadoop,大小為5120M的邏 輯卷,並且裝置入口為/dev/test_document/lvhadoop ,test_document為卷組名,lvhadoop為邏輯卷名)
b)lvcreate -L51200 -n lvdatatest_document
(該命令是在卷組test_document上建立名字為lvdata,大小為51200M的邏 輯卷,並且裝置入口為/dev/test_document/lvdata ,test_document為卷組名,lvdata為邏輯卷名)

注意,如果分配過大的邏輯卷lvcreate -L10240 -n lvhadoop test_document會提示剩餘空間不足,此時可用命令vgdisplay去產檢視剩餘空間的大小。
(8)建立檔案系統
a) mkfs -t ext4/dev/test_document/lvhadoop
b) mkfs -t ext4/dev/test_document/lvdata
(9)建立資料夾
a)在linux根目錄下建立hadoop資料夾 mkdir -p /hadoop
b)在linux根目錄下建立data資料夾 mkdir -p /data
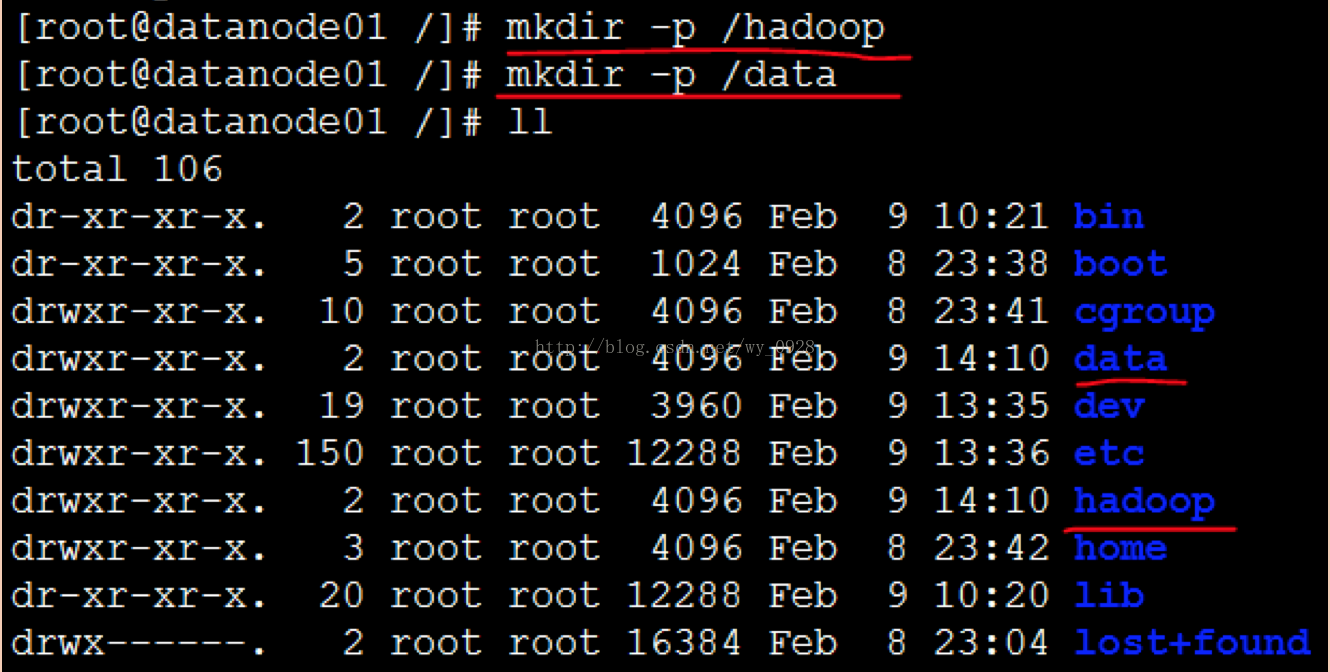
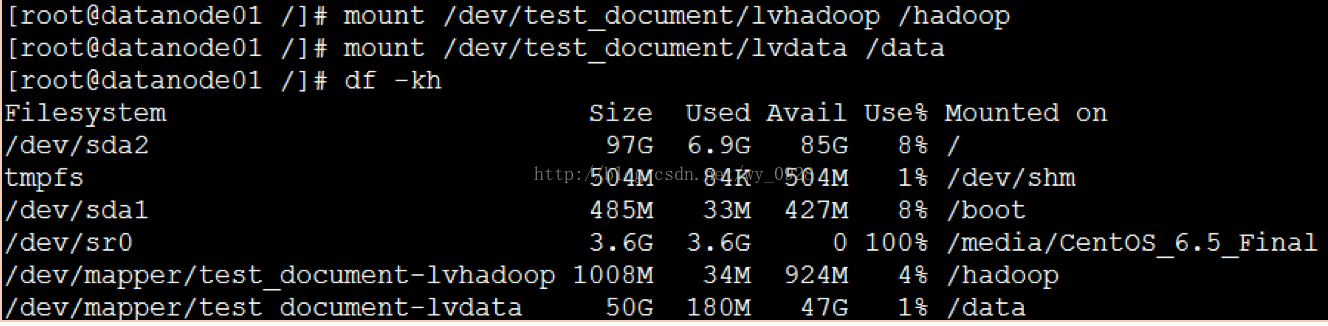
(10)掛載
a)mount /dev/test_document/lvhadoop /hadoop
b)mount /dev/test_document/lvdata /data
c)掛載後,再使用 df -kh 命令檢視
(11)修改自動掛載的配置檔案
如果下次重啟linux系統後,掛載裝置就又看不到了,我們需要把這個檔案寫入到fstab 分割槽表文件裡面。
a)vi /etc/fstab
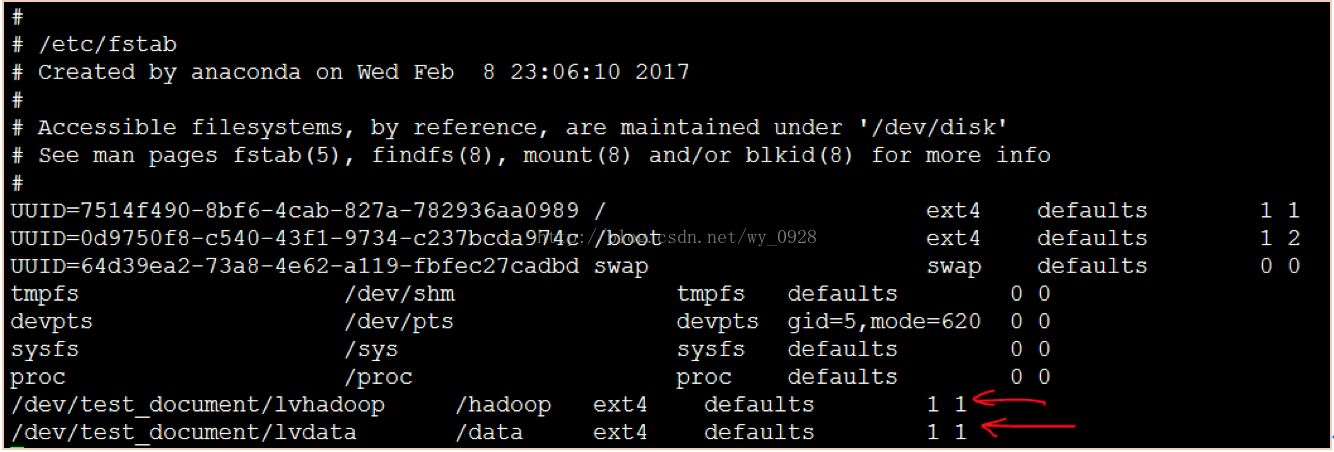
在檔案末尾加上如上兩行,然後按“ESC”---“shirt”+“:”---輸入“x”---回車,之後reboot重啟虛擬機器。
6.建立hadoop組和使用者
(1)建立組
groupadd -g 3000 cloudadmin
(2)建立使用者
useradd -u3001 -g cloudadmin hadoop

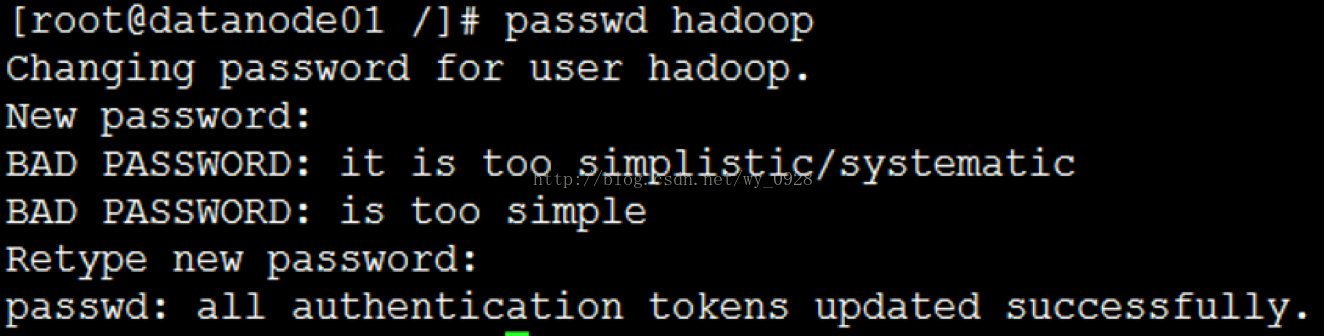
(3)修改密碼
passwd hadoop 密碼改為:123456(與root使用者的密碼一致)
(4)修改檔案的系統許可權
a)修改hadoop檔案的系統許可權 chown -Rhadoop:cloudadmin /hadoop
b)修改data檔案的系統許可權 chown -Rhadoop:cloudadmin /data
c)檢視 ls -l / | grep cloudadmin

7.下載hadoop軟體包
點選左側的Download Hadoop
單擊releases
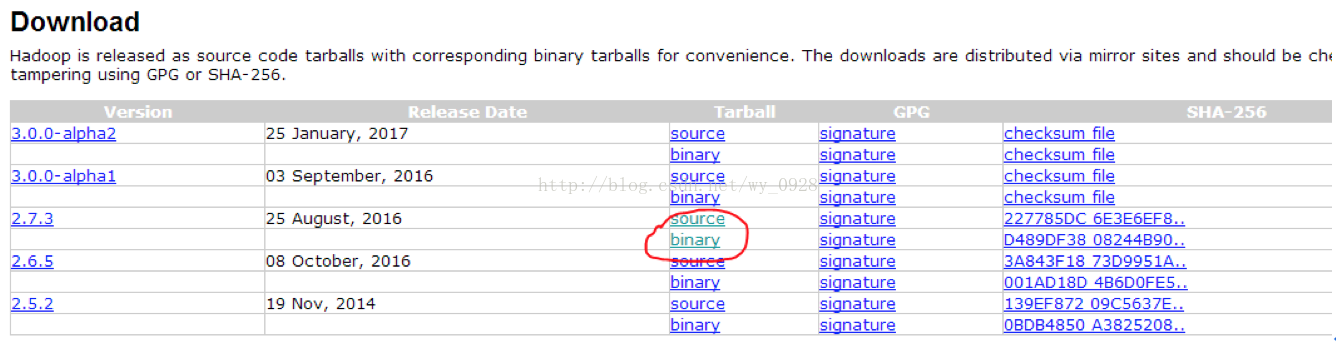
單擊binary,注意source是原始碼,不要下載錯了
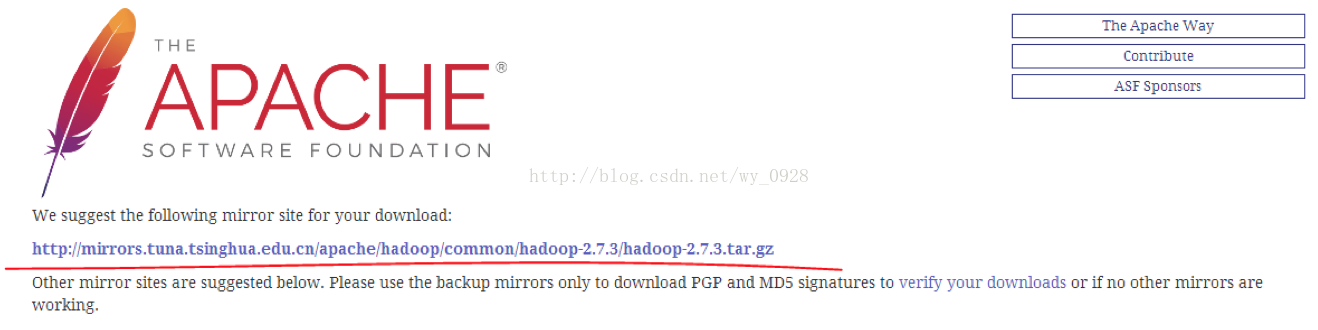
單擊上圖的連結進行下載

上圖中-src是原始碼檔案,我們用另外一個。
8.在虛擬機器中解壓hadoop
(1)將下載的壓縮包上傳到/hadoop目錄下(rz命令):

(2)切換到hadoop使用者
重啟虛擬機器,用hadoop使用者登入,注意Xshell遠端連線的時候,新建個hadoop使用者登入視窗
(退出hadoop使用者exit,檢視當前使用者whoami)

(3)解壓hadoop壓縮包:tar -zxvfHadoop-2.7.3-src.tar.gz,解壓完成後出現hadoop資料夾:

之後ll檢視:

9.建立叢集(規劃1個主節點,2個從節點)
為了看著舒服,將當前虛擬機器改名為hm(直接在VMware右鍵重新命名即可);
(1)克隆2臺虛擬機器
在VMware虛擬機器中右鍵-管理-克隆
直接下一步
直接下一步
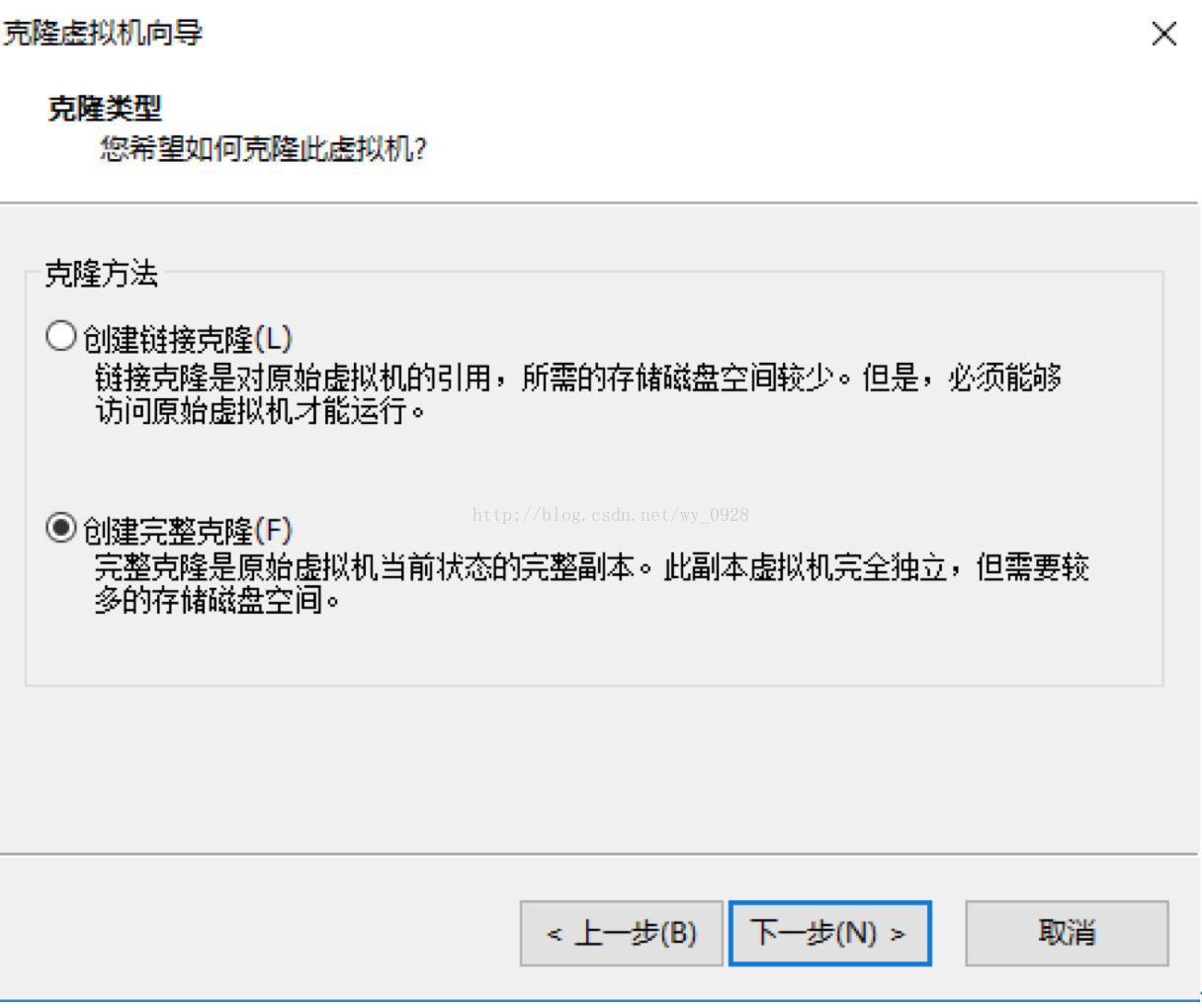
選擇建立完整克隆,下一步,將名稱改為hd001:
點完成開始克隆,克隆完成後:
點關閉即可,用同樣的方法再克隆一臺虛擬機器(注意名稱為hd002)。
克隆的時候,新虛擬機器ip自動更新1,就是比如第一臺虛擬機器ip為192.168.99.1,那麼克隆出第二臺,ip自動更新為192.168.99.2,以此類推。
(2)修改3臺虛擬機器的主機名
開啟3臺虛擬機器,用Xshell連線的時候注意ip不同,之後3臺虛擬機器都切換成root使用者:
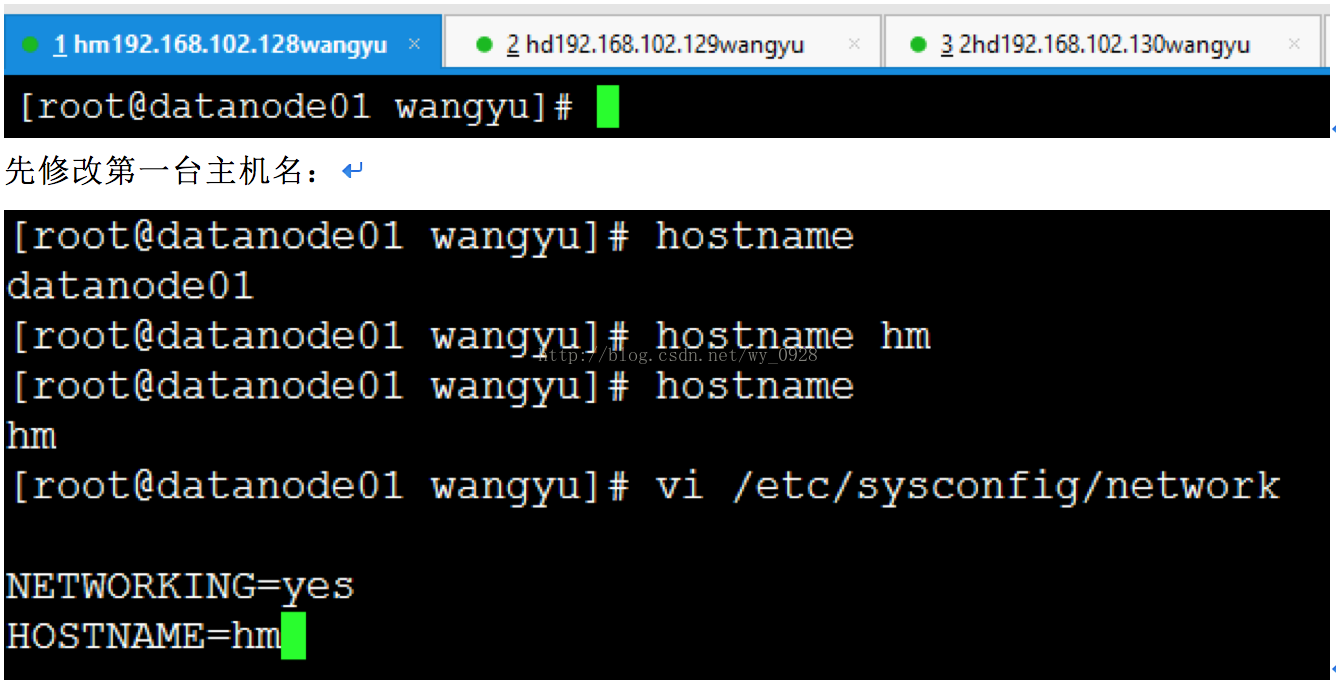
其中hostname是檢視當前主機名,hostname hm是將主機名改為hm,但是這麼做重啟會失效,因此我們修改配置檔案network,之後reboot重啟此虛擬機器。
其餘所有虛擬機器都重複上述操作,注意主機名hm改為hd001和hd002。
(3)修改3臺虛擬機器的ip和mac
全部用root使用者登入!

先修改第一臺虛擬機器的ip和mac,輸入cat/etc/udev/rules.d/70-persistent-net.rules檢視,如果不是下圖的樣子,將其餘網絡卡註釋掉,另外複製它的MAC地址:

進入network-scripts目錄,編輯其內的ifcfg-eth0檔案,將該虛擬機器的ip和剛剛複製的mac地址覆蓋上:
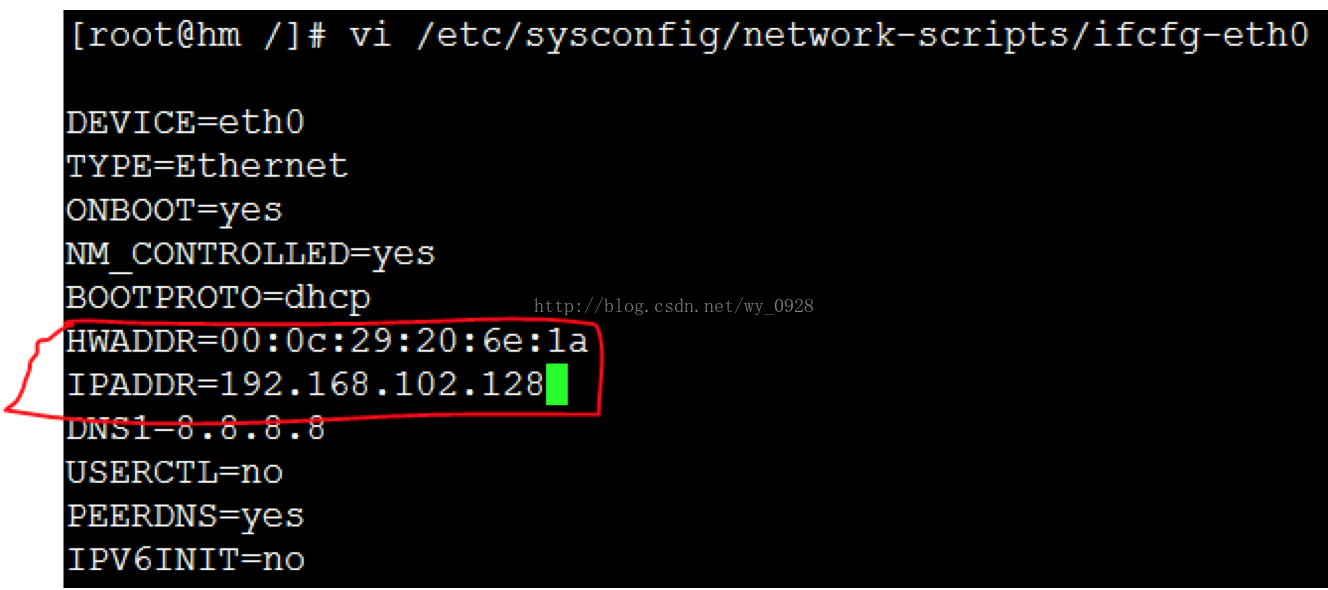
重啟網絡卡
至此,第一臺虛擬機器的ip和mac配置完畢,接著配置第二臺虛擬機器的ip和Mac地址,輸入vi /etc/udev/rules.d/70-persistent-net.rules修改,因為上面的MAC地址與第一臺虛擬機器相同,因此我們用下一個,並將網絡卡修改為eth0:

後續步驟同上,接著同理配置第三臺虛擬機器的ip和Mac地址。
(4)修改對映關係
用root登入第一臺虛擬機器,輸入vi /etc/hosts,按照下圖配置,圖中的ip為各個虛擬機器的ip:
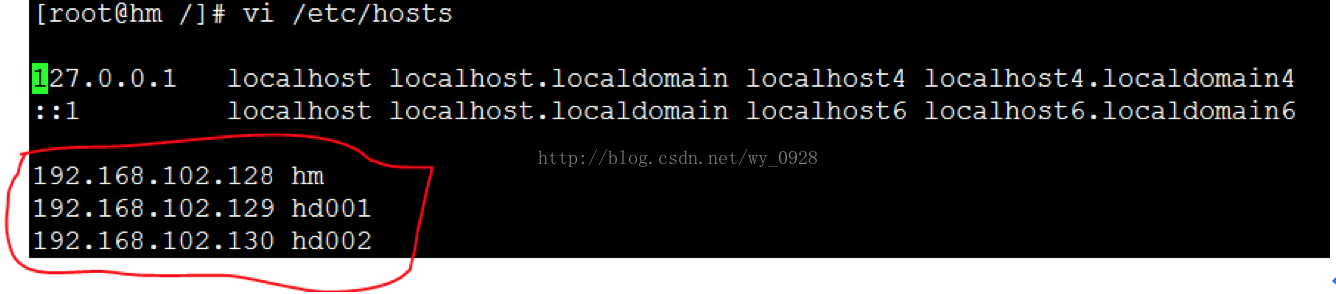
進入/etc資料夾:
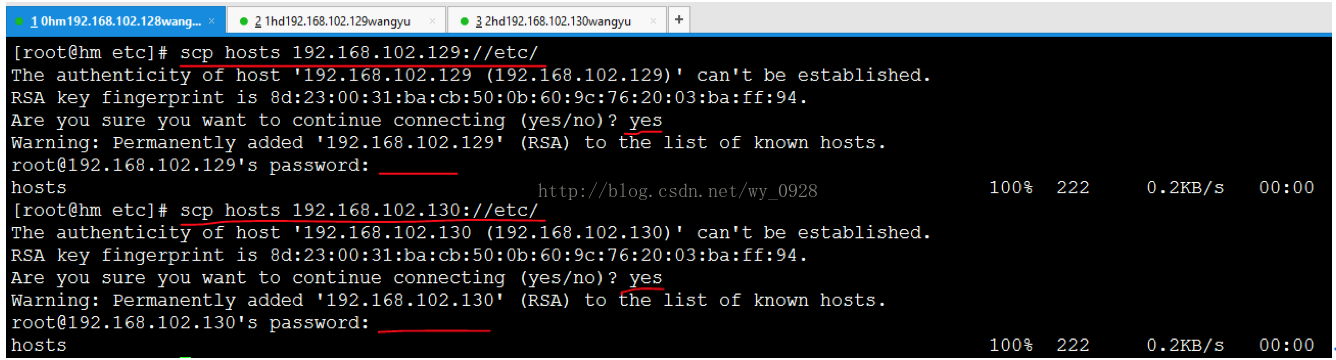
scp hosts192.168.102.129://etc/
將hm etc資料夾下的hosts傳到192.168.102.128 的etc下
scp hosts192.168.102.130://etc/
將hm etc資料夾下的hosts傳到192.168.102.130 的etc下
有提示時,輸入yes,密碼是剛設定的123456
再去另外2臺虛擬機器檢視檔案是否傳輸成功cat /etc/hosts
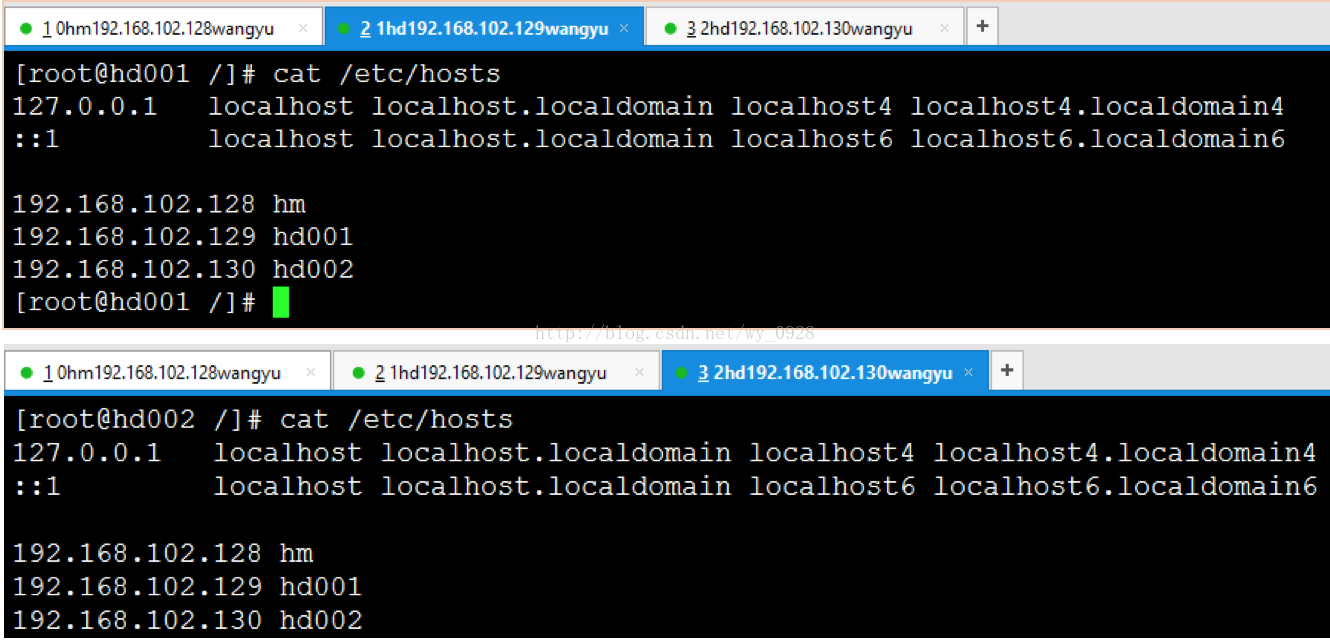
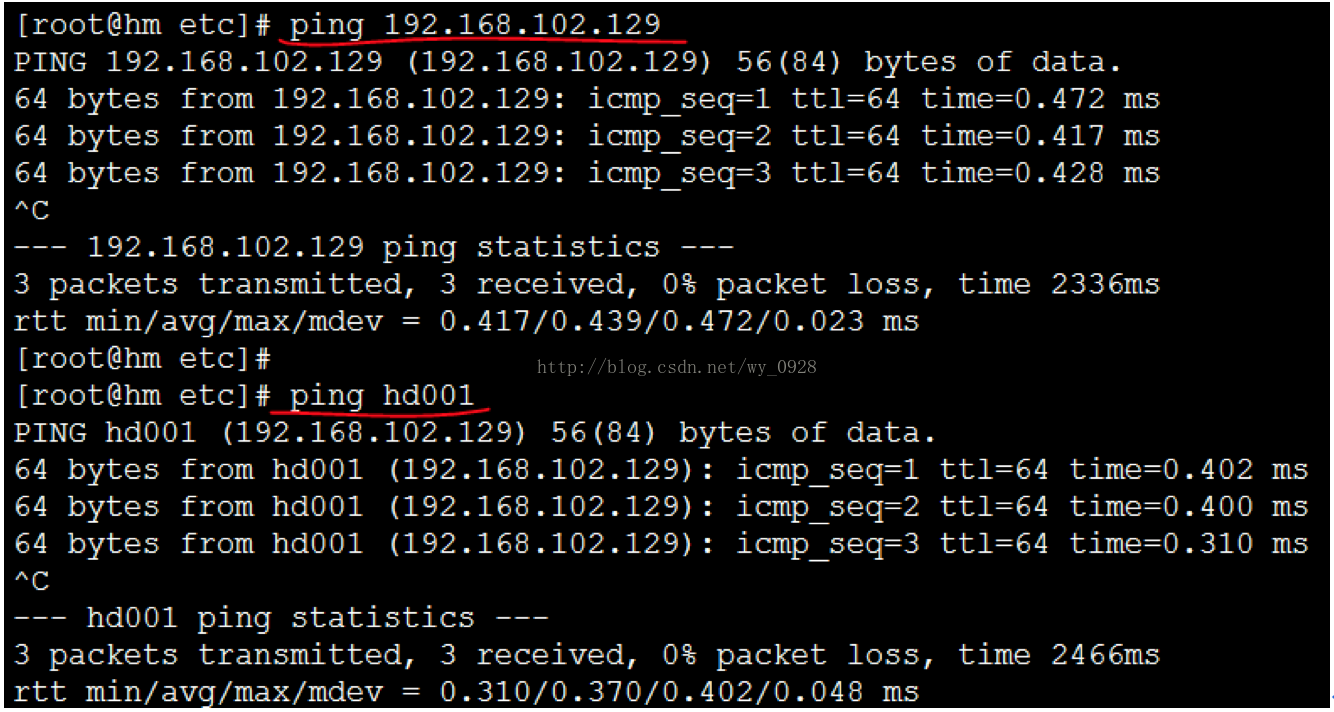
在每臺虛擬機器中進行ping通測試,這裡每臺虛擬機器都需要測試與另外所有虛擬機器是否通,且ping ip和ping 主機名都要測試(這裡很容易漏測):
10.在叢集中配置SSH免密登入
(1)重啟所有虛擬機器,均用hadoop使用者登入
(2)在主節點hm的Xshell裡輸入ssh-keygen -t rsa命令,然後一直按回車即可
在主節點hm上執行如下命令:
cd ~
cd .ssh
catid_rsa.pub >> authorized_keys
scp authorized_keys192.168.102.129:/root/.ssh/
scpauthorized_keys 192.168.102.130:/root/.ssh/
出現提示就輸入yes,密碼是之前設定的123456,這裡如果在scp時提示Permission denied,是因為當前登入的hadoop使用者沒有許可權,解決辦法3個:其一是為hadoop使用者授權,其二是切換成root使用者進行操作,其三是將authorized_keys從主節點下載到本地再逐一上傳到所有從節點。
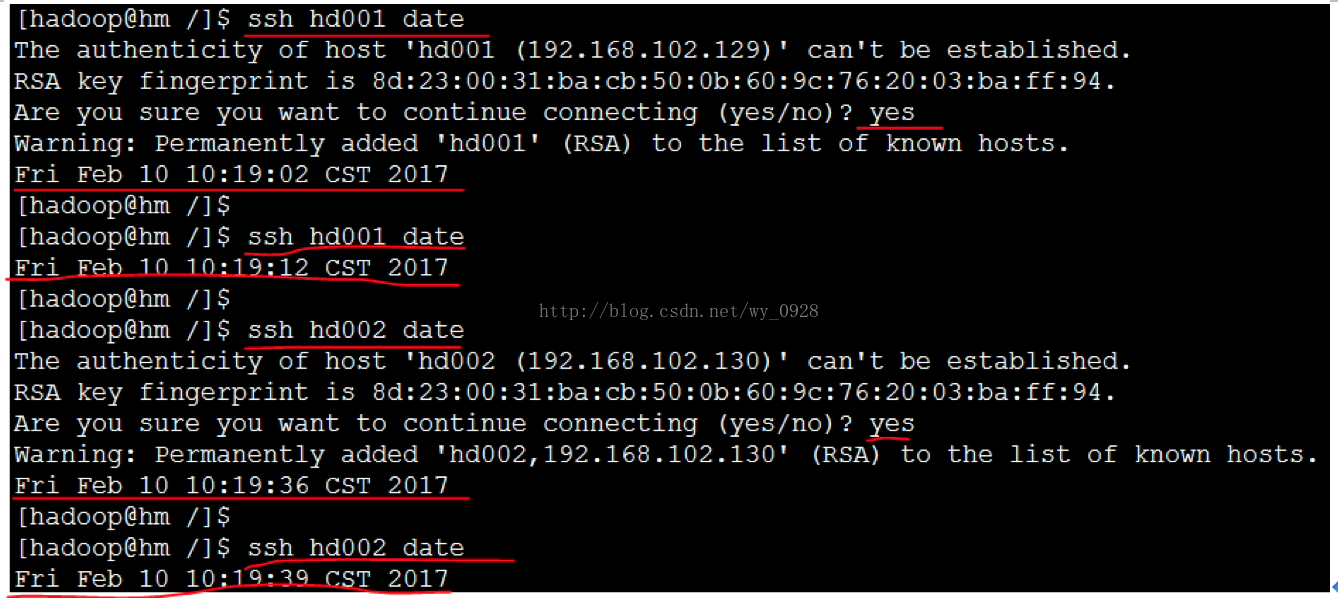
(3)SSH免密碼登入驗證
ssh hd001date
ssh hd002date
第一次輸入會有提示,輸入yes,後面就正常
11.修改hadoop叢集的配置檔案
在hadoop使用者下進行以下操作:
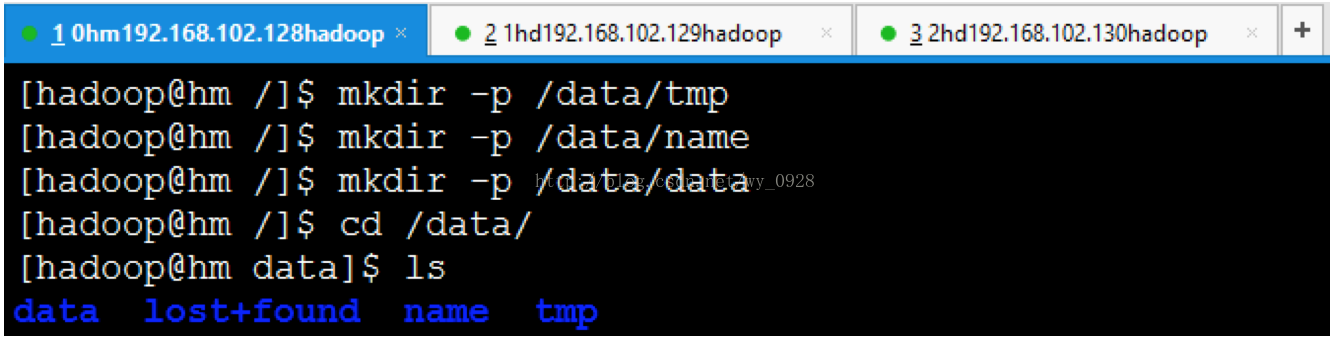
(1)在叢集中的所有節點上建立相應的檔案目錄
a)建立tmp檔案,mkdir -p /data/tmp
b)建立name檔案,mkdir -p /data/name
c)建立data檔案,mkdir -p /data/data
d)進入data目錄,cd /data
e)檢視data資料夾下的檔案,ls
(2)在主節點上修改配置檔案
a)進入根目錄cd /
b)進入hadoop配置檔案所在目錄cd /hadoop/hadoop-2.7.3/etc/hadoop/

c)修改hadoop-env.sh檔案vi hadoop-env.sh

這裡JAVA_HOME的地址是之前配置JDK那裡的地址
d)修改core-site.xml檔案vi core-site.xml
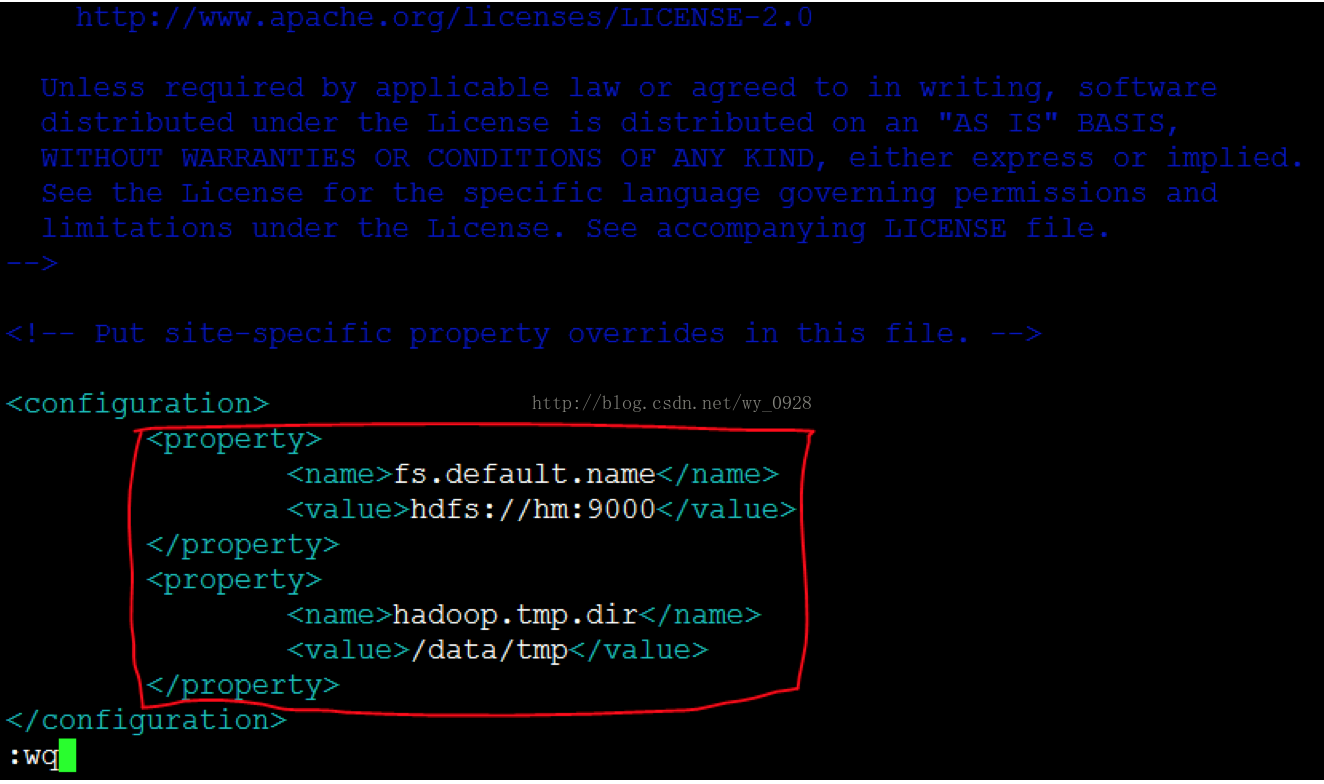
注意主機名hm和路徑是之前設定好的,不要配錯了
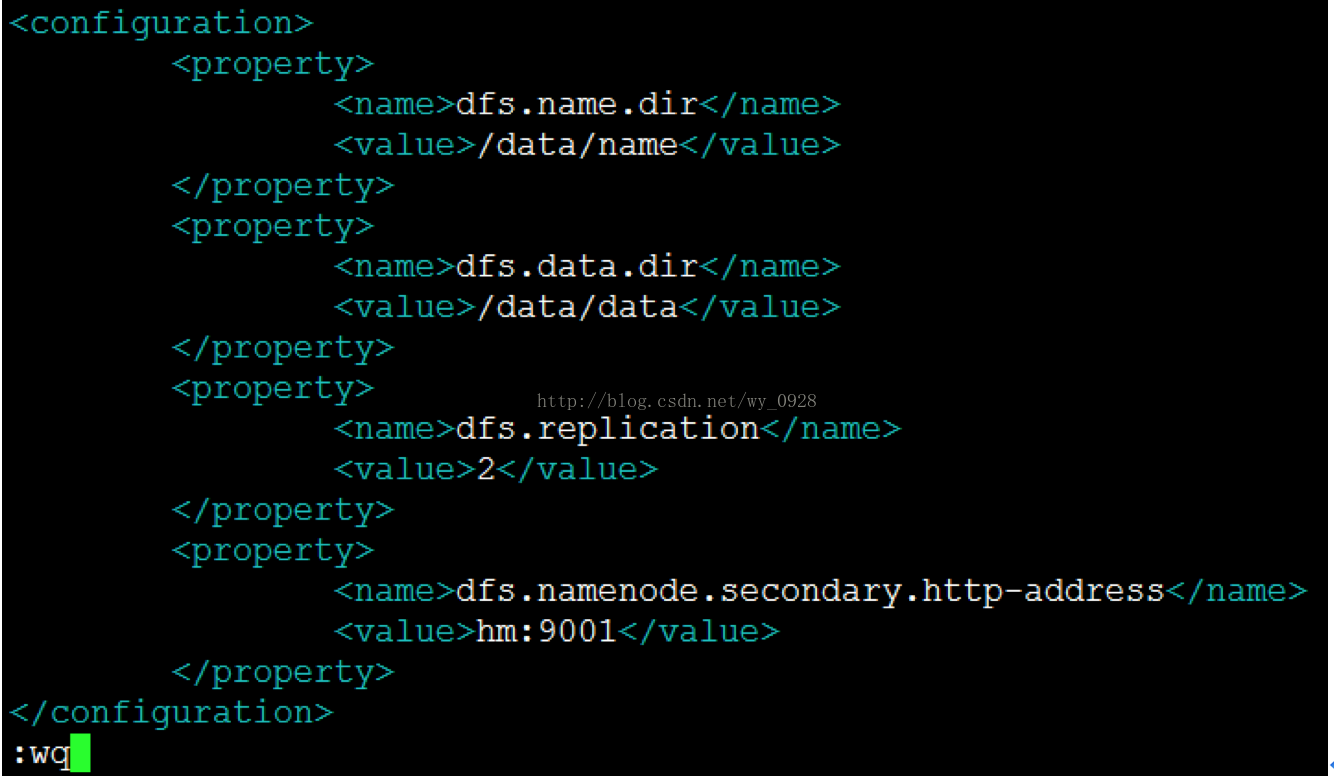
e)修改hdfs-site.xml檔案vi hdfs-site.xml
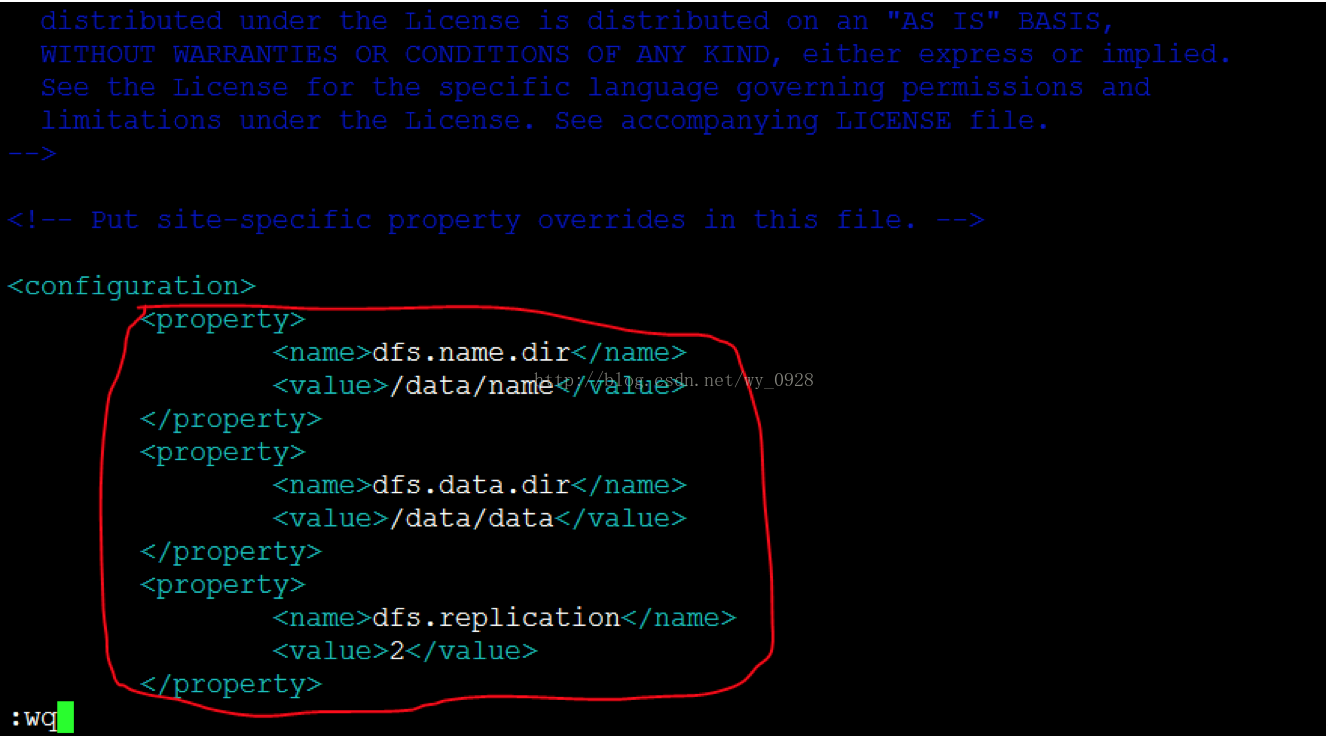
注意這裡的路徑是之前設定好的,不要配錯了,另外有幾臺從節點就寫幾,我這裡寫2
f)修改mapred-site.xml.template檔案vi mapred-site.xml.template
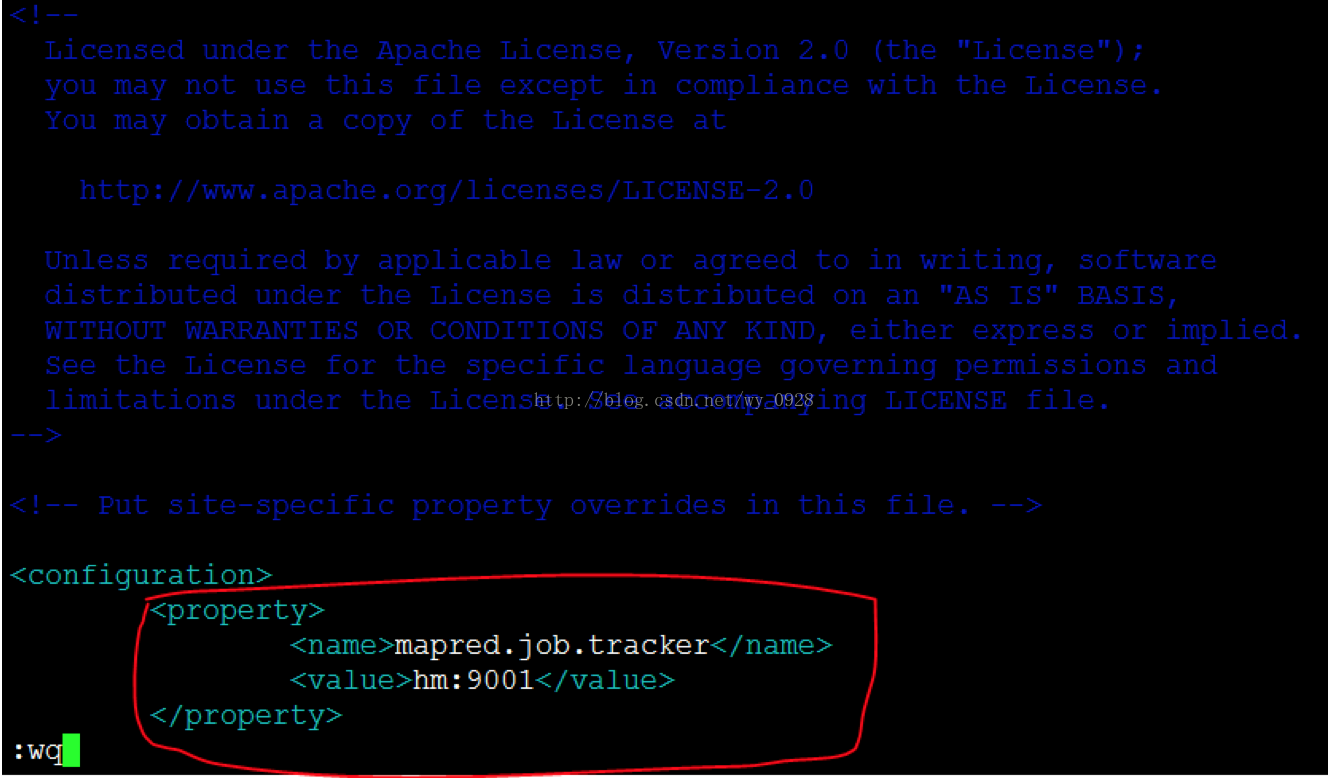
注意主節點名hm是之前設定好的,不要配錯了
g)複製檔案,將mapred-site.xml.template複製一份並重新命名為mapred-site.xml存放在當前路徑:

同理將mapred-queues.xml.template複製一份並重新命名為mapred-queues.xml存放在當前路徑:

注:hadoop1.x版本直接有這兩個檔案,而hadoop2.x版本需要複製重新命名一下
h)繼續修改hdfs-site.xml檔案
因為hadoop2.x刪除了1.x版本的masters檔案,因此將master在hdfs-site.xml裡面
i)修改slaves檔案vi slaves
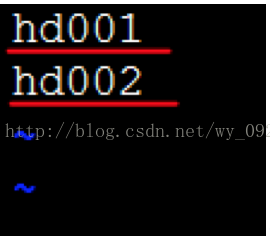
這裡寫入所有從節點的主機名
(3)同步時鐘
ntpdate
(4)分發hadoop軟體包到從節點上
注意這步是hadoop使用者在/hadoop目錄下操作,時間較長,請耐心等待
scp -r hadoop-2.7.3hd001:/hadoop/
scp -rhadoop-2.7.3 hd002:/hadoop/
12.格式化HDFS
(1)在hadoop使用者下進入主節點的/hadoop/hadoop2.7.3目錄
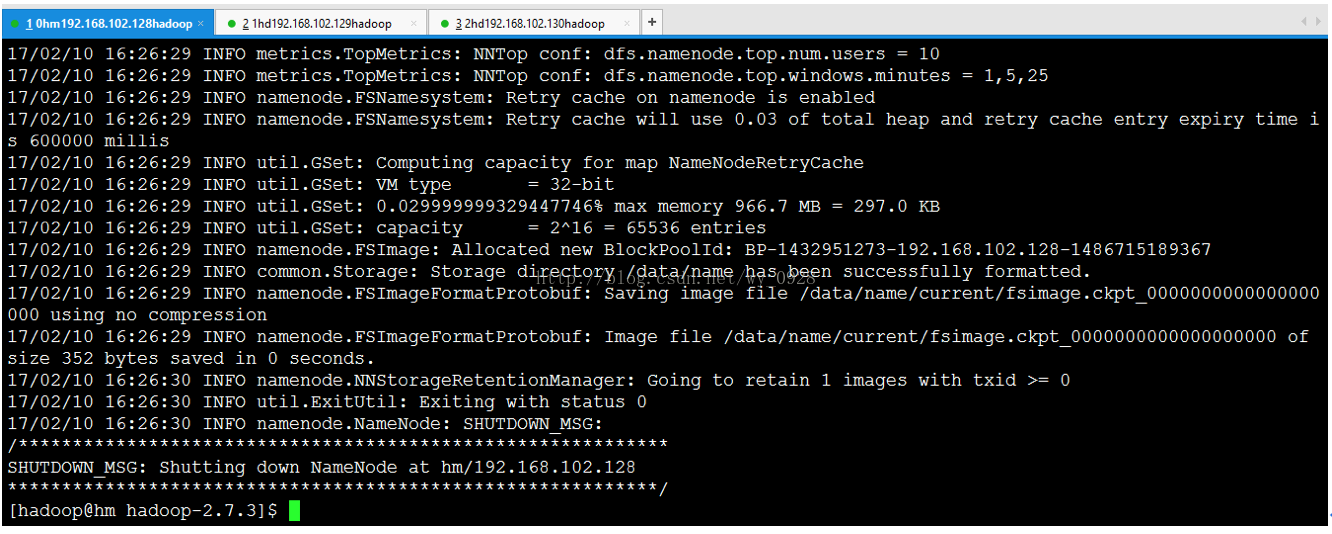
(2)格式化hdfs
bin/hadoop namenode -format

如果有提示,輸入大寫的Y,小寫的報錯,沒有就算了
格式化出錯的解決方法
a、檢視埠9000的資訊(需要在root使用者下檢視)
netstat -anp|grep 9000
b、格式化只能1次,如果後面再次格式化則會導致不成功,需要將所有節點上根目錄下data目錄下的data、name、tmp檔案刪除,再新建data、name、tmp空的資料夾。
13.啟動hadoop 系統
(1)用hadoop使用者登入主節點,進入/hadoop/hadoop2.7.3目錄
(2)啟動hadoop系統
bin/start-all.sh或sbin/start-all.sh
(關閉叢集sbin/stop-all.sh)
版本不同,apache的2.x版本啟動指令碼是在sbin資料夾內。

輸入yes
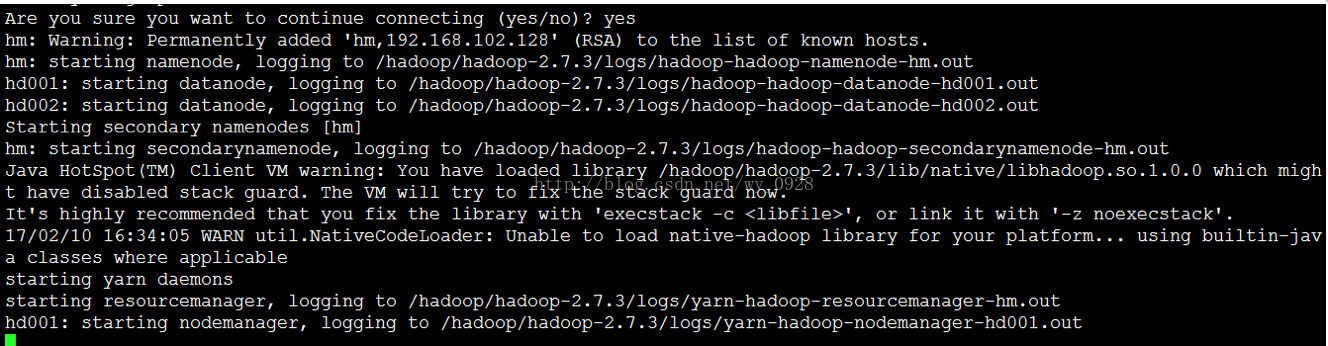
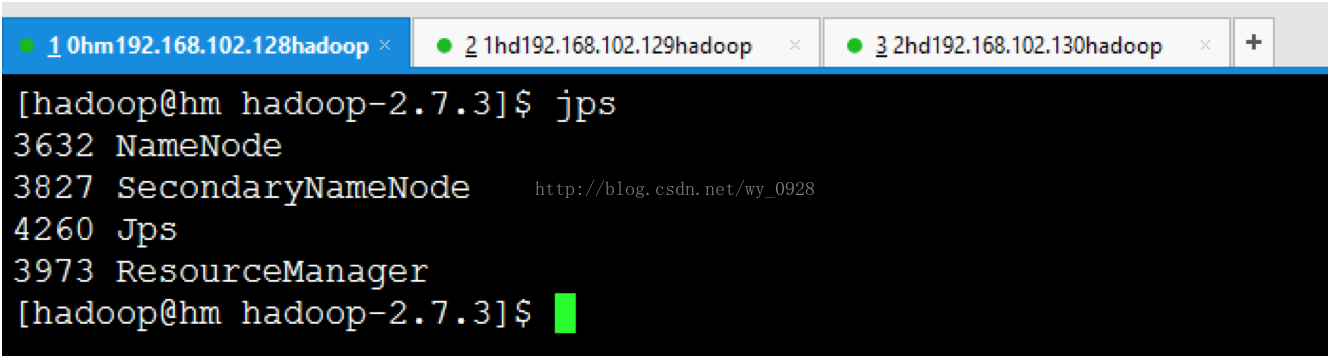
(3)檢查hadoop的相關程序是否啟動成功
a)主節點jps
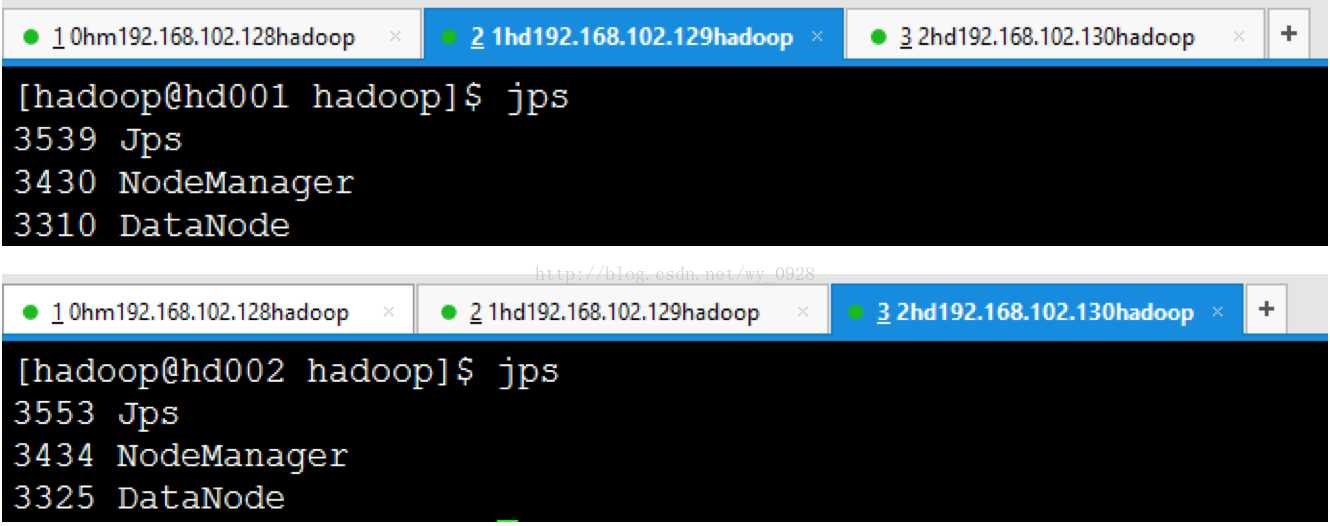
b)所有從節點jps
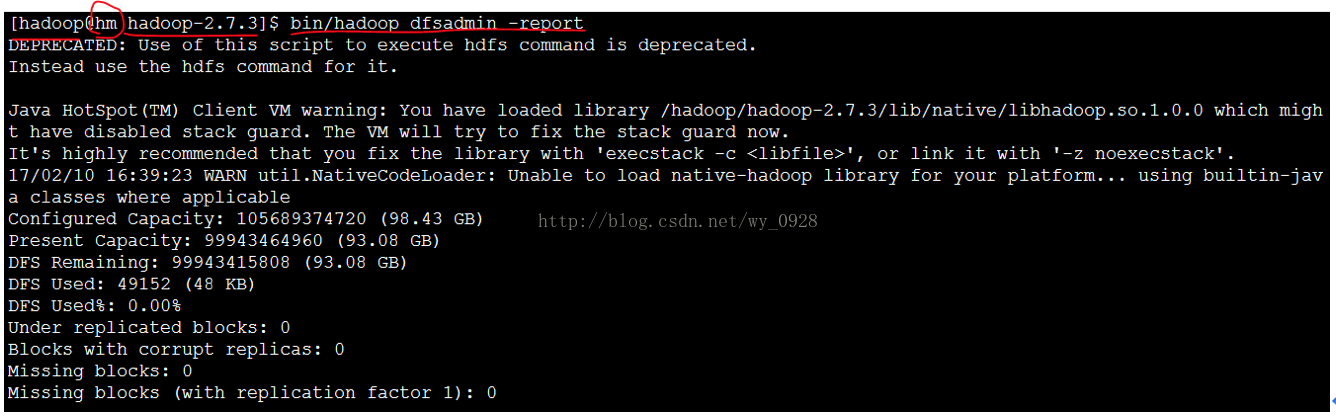
(4)檢查叢集狀態
a)在hadoop使用者下進入主節點的/hadoop/hadoop2.7.3目錄
b)輸入bin/hadoop dfsadmin -report命令
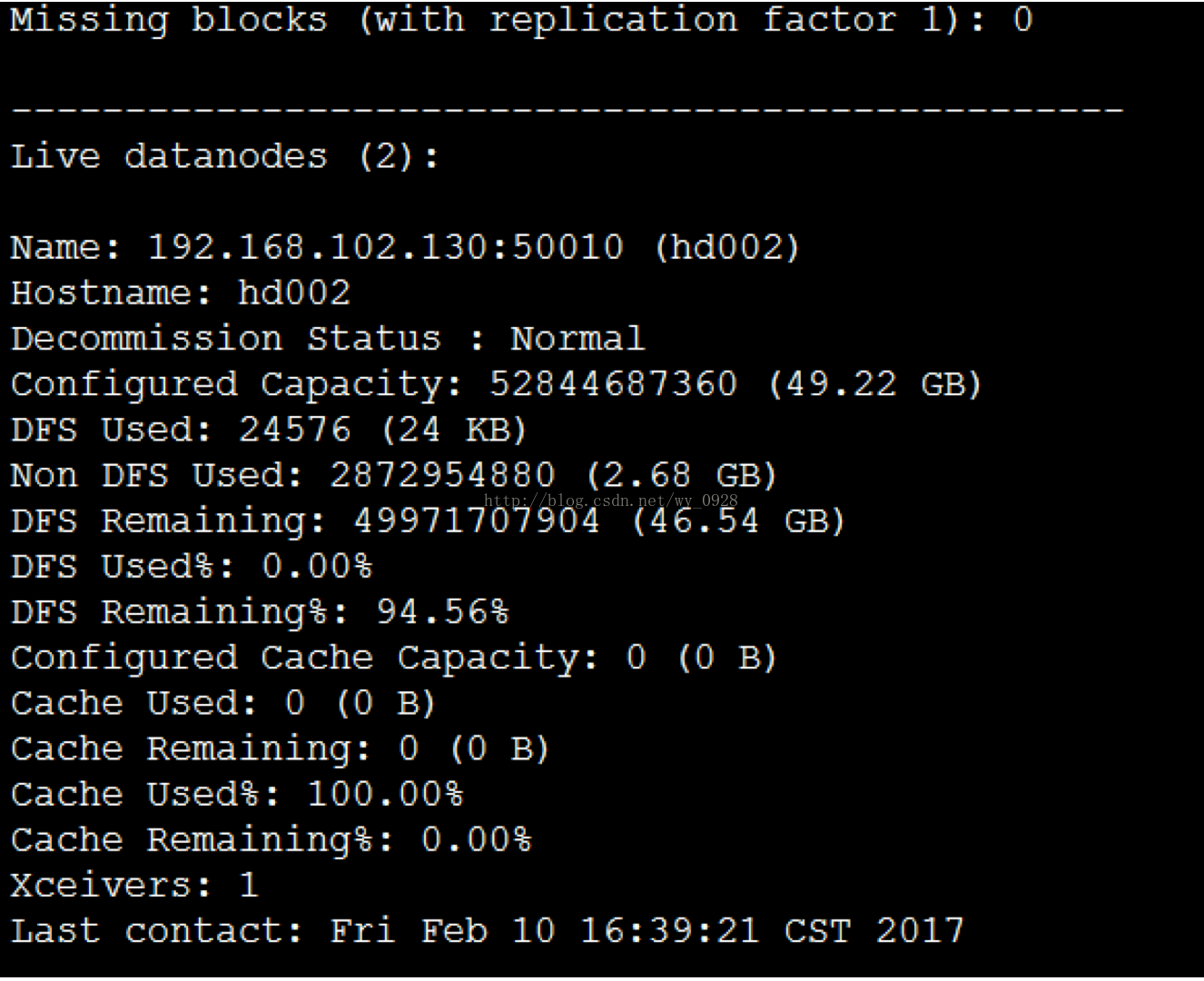
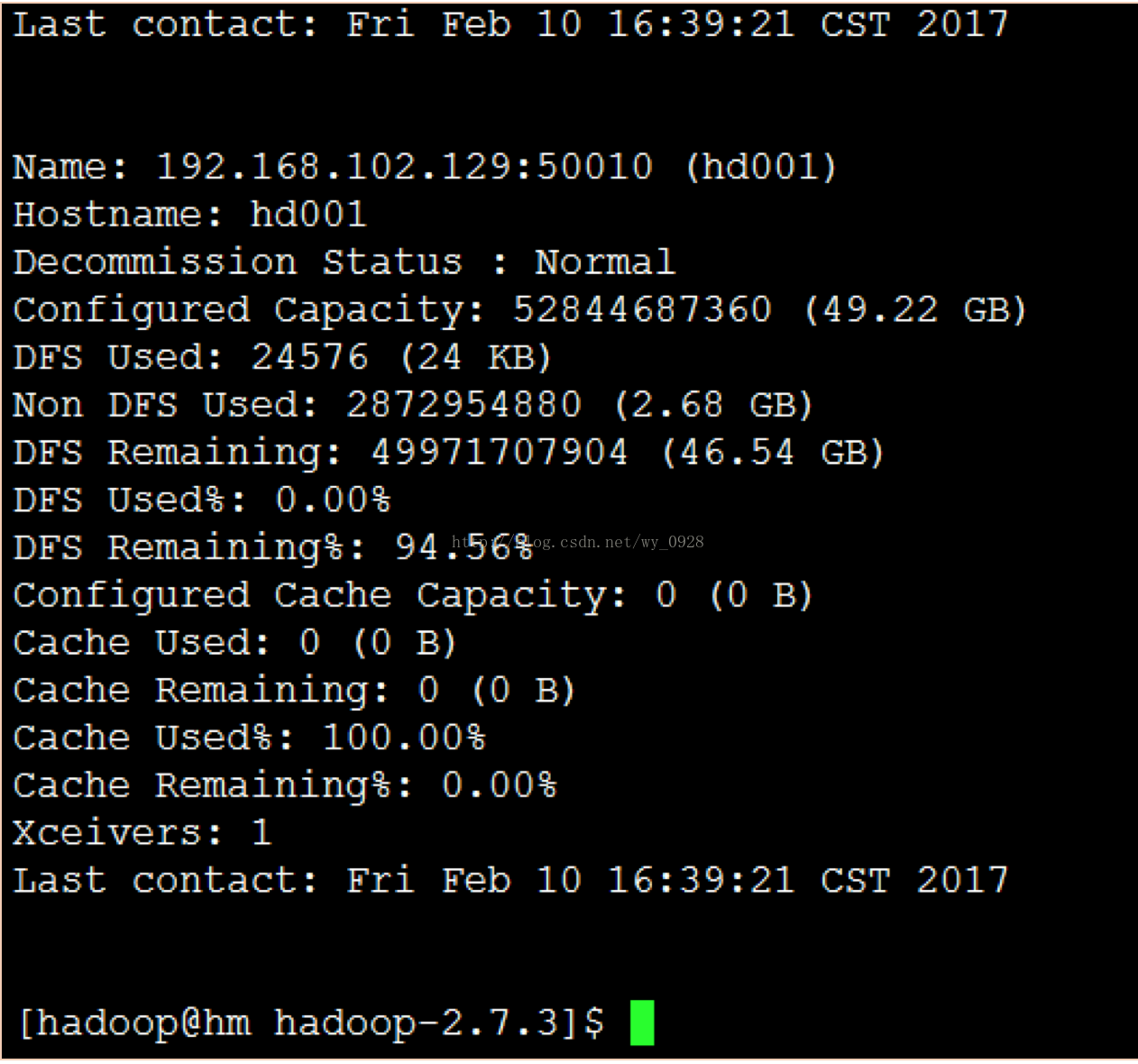
(5)檢視監控介面
a)在瀏覽器位址列輸入192.168.102.128:8088回車
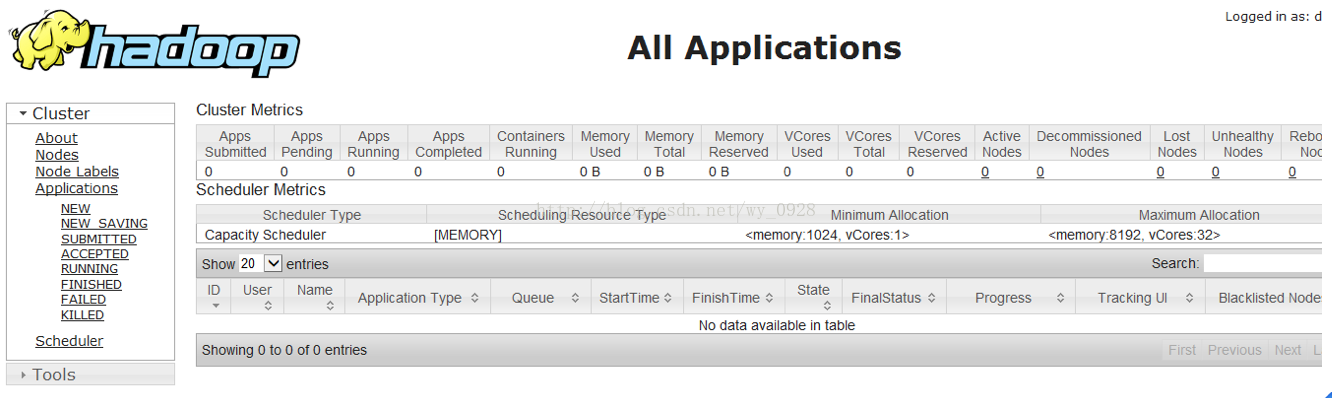
hadoop1.x埠是50030,後來2.x改為8088了。
【後記】
1.開啟hadoop叢集方法
所有虛擬機器開機-Xshell遠端登入所有虛擬機器(建議用hadoop使用者)-在主節點用hadoop使用者進入/hadoop2.7.3目錄,輸入/sbin/start-all.sh回車。
2.關閉hadoop叢集方法
在主節點用hadoop使用者進入/hadoop2.7.3目錄,輸入sbin/stop-all.sh回車。
3.網頁監控
192.168.102.128:8088