HDFS、YARN和MapReduce簡介
Hadoop
Hadoop是一個Apache旗下的分散式系統基礎架構。
Hadoop1由HDFS和MapReduce構成;Hadoop2框架核心設計有HDFS、MapReduce、YARN。
Hadoop2主要改進了以下四部分:YARN、NameNode HA、HDFS federation、Hadoop RPC序列化擴充套件性。詳細解釋如下:
YARN是Hadoop2中的資源管理系統,它可以使Hadoop2可以執行更多的處理框架;
NameNode HA提高了Hadoop的可靠性,當action NameNode宕機時,可立即切換到standby NameNode提供服務;
HDFS federation讓多個NameNode共同管理DataNode,增加了Hadoop的叢集規模;
Hadoop RPC序列化擴充套件性的提高,是指將資料型別獨立可插拔。
HDFS
HDFS是一個分散式檔案系統,具有高容錯性,提供高吞吐率的資料訪問,能夠有效處理海量資料集。
它支援超大檔案,能夠檢測並應對硬體故障,採用流式資料訪問,並使用了簡化了的一致性模型。但它不適合低延遲環境,大量小檔案的讀寫,並且不支援多使用者寫入以及隨機修改檔案。
HDFS由NameNode和DataNode構成;NameNode儲存HDFS的名字空間,任何修改操作都記錄在NameNode中;DataNode把每個HDFS資料塊(HDFS處理單元,預設128MB)儲存在本地檔案系統的單獨檔案中,以此來儲存HDFS資料。
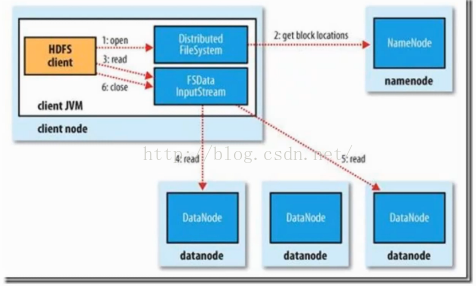
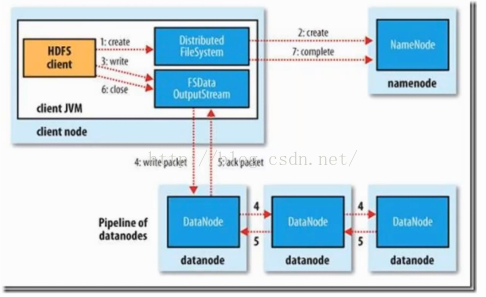
HDFS的讀寫流程如下圖所示:
MapReduce
MapReduce是面向大型資料處理的平行計算模型和方法。
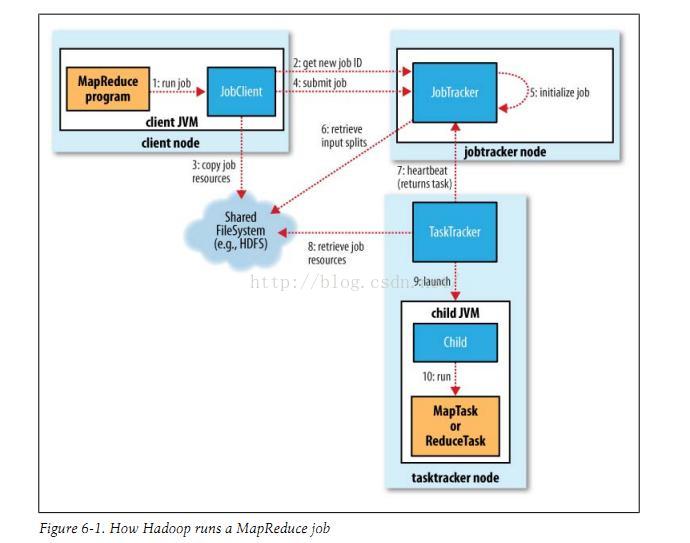
其工作流程如下:
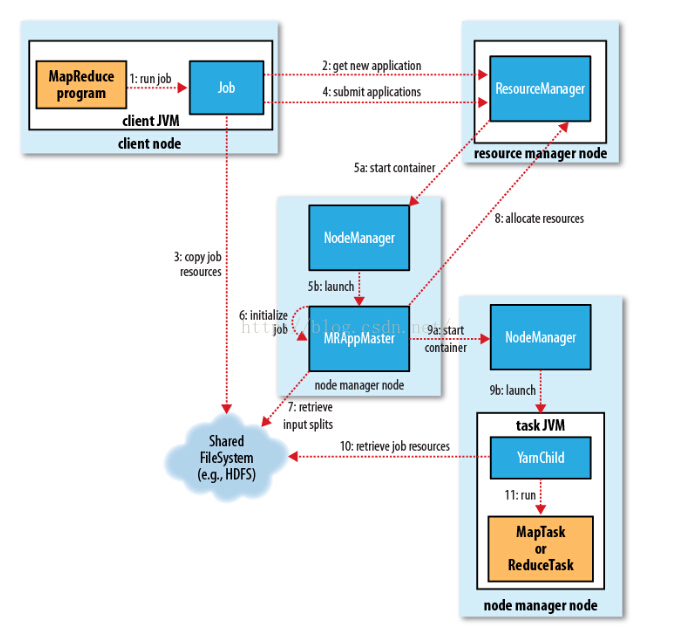
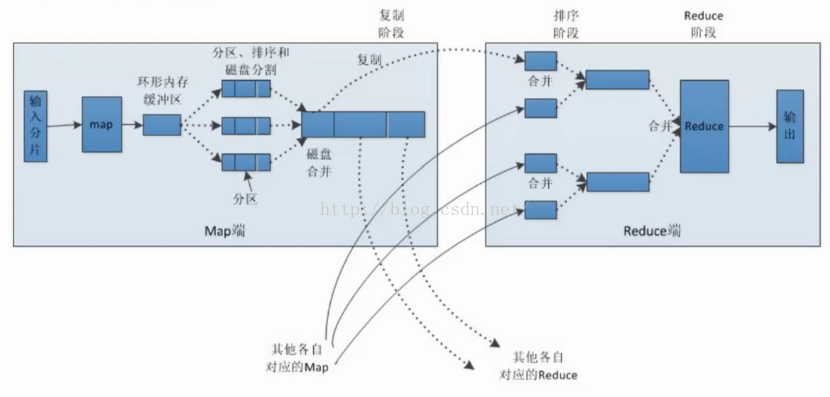
MapReduce的map端輸出作為輸入傳遞給reduce端,並按鍵排序的過程稱為shuffle,其過程如圖:
Hadoop1中的MapReduce有以下四大缺點:
JobTracker同時負責資源管理和作業控制,導致其擴充套件性差;
MapReduce採用Master/Slave結構存在的單點故障問題會使整個叢集不可用,所以它可靠性差;
MapReduce資源分配基於槽位,兩種Map槽位和Reduce槽位工作時間不同卻不可共享資源,降低了資源的利用率;
它無法支援多種計算框架,只能使用基於磁碟的離線計算,不支援記憶體計算、流式計算和迭代式計算。
YARN
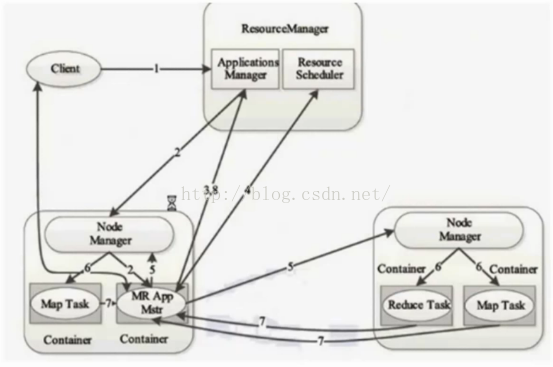
YARN是Hadoop2中的通用資源管理系統,為上層應用提供統一資源管理排程,改正了Hadoop1中MapReduce的缺點,其結構如下:

YARN的元件有ResourceManager、ApplicationMaster、NodeManager和Container,其採用的仍然是Master/Slave結構(ResourceManager是Master,NodeManager是Slave)。
其工作流程圖如下: