
hadoop之HDFS、yarn、MapReduce執行原理分析
1、HDFS分散式儲存
namenode:統一管理檔案的元資料資訊
fsImage:儲存了檔案的基本資訊,如檔案路徑,檔案副本集個數,檔案塊的資訊,檔案所在的主機資訊。
editslog:存了客戶端對hdfs中各種寫操作的日誌(指令);
secondaryNamenode:協助namenode完成fsimage和editlog的合併(定期合併)。
合併週期:1、每隔1小時合併一次 2、當editlog檔案大小超過64M,立刻合併
datanode:負責儲存真實的資料。
block:儲存資料的基本單位,預設128M。

2、yarn框架

yarn的工作流程
當用戶向YARN中提交一個應用程式後,YARN將分兩個階段執行該應用程式:
第一個階段是啟動ApplicationMaster;
第二個階段是由ApplicationMaster建立應用程式,為它申請資源,並監控它的整個執行過程,直到執行完成。
具體流程如下:
步驟1 使用者向YARN中提交應用程式,其中包括ApplicationMaster程式、啟動ApplicationMaster的命令、使用者程式等。
步驟2ResourceManager為該應用程式分配第一個Container,並與對應的Node-Manager通訊,要求它在這個Container中啟動應用程式的ApplicationMaster。
步驟3ApplicationMaster首先向ResourceManager註冊,這樣使用者可以直接通過ResourceManager檢視應用程式的執行狀態,然後它將為各個任務申請資源,並監控它的執行狀態,直到執行結束,即重複步驟4~7。
步驟4ApplicationMaster採用輪詢的方式通過RPC協議向ResourceManager申請和領取資源。
步驟5 一旦ApplicationMaster
步驟6NodeManager為任務設定好執行環境(包括環境變數、JAR包、二進位制程式等)後,將任務啟動命令寫到一個指令碼中,並通過執行該指令碼啟動任務。
步驟7 各個任務通過某個RPC協議向ApplicationMaster彙報自己的狀態和進度,以讓ApplicationMaster隨時掌握各個任務的執行狀態,從而可以在任務失敗時重新啟動任務。
在應用程式執行過程中,使用者可隨時通過RPC向ApplicationMaster查詢應用程式的當前執行狀態。
步驟8 應用程式執行完成後,ApplicationMaster向ResourceManager登出並關閉自己。
3、mapreduce中wordcount原理圖
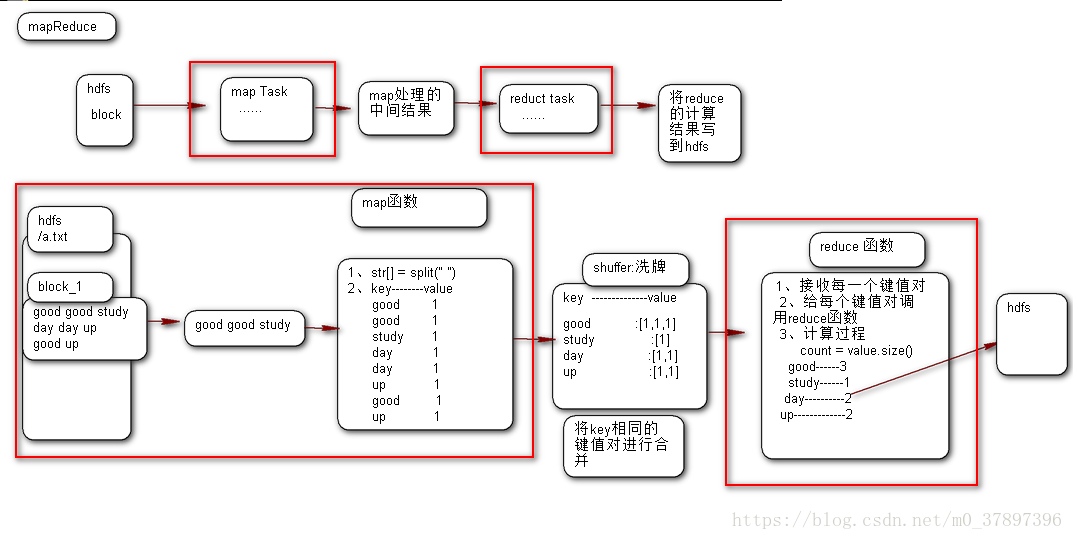
把一堆雜亂無章的資料按照某種特徵歸納起來,然後處理並得到最後的結果。Map面對的是雜亂無章的互不相關的資料,它解析每個資料,從中提取出key和value,也就是提取了資料的特徵。經過MapReduce的Shuffle階段之後,在Reduce階段看到的都是已經歸納好的資料了,在此基礎上我們可以做進一步的處理以便得到結果
mapreduce開發主要是開發map、reduce函式。