
Curiosity-Driven Learning made easy Part I
In the recent years, we’ve seen a lot of innovations in Deep Reinforcement Learning. From DeepMind and the Deep Q learning architecture in 2014 to OpenAI playing Dota2 with OpenAI five in 2018, we live in an exciting and promising moment.
And today we’ll learn about Curiosity-Driven Learning, one of the most exciting and promising strategy in Deep Reinforcement Learning.
Reinforcement Learning is based on the reward hypothesis, which is the idea that each goal can be described as the maximization of the rewards. However, the current problem of extrinsic rewards (aka rewards given by the environment) is that this function is hard coded by a human, which is not scalable.
The idea of Curiosity-Driven learning, is to build a reward function that is intrinsic to the agent (generated by the agent itself). It means that the agent will be a self-learner since he will be the student but also the feedback master.


They discovered that curiosity driven learning agents perform as good as if they had extrinsic rewards, and were able to generalize better with unexplored environments.
In this first article we’ll talk about the theory and explain how works Curiosity Driven Learning in theory.
Then, in a second article, we’ll implement a Curiosity driven PPO agent playing Super Mario Bros.
Sounds fun? Let’s dive on in !
Two main problems in Reinforcement Learning
First, the problem of sparse rewards, which is the time difference between an action and its feedback (its reward). An agent learns fast if each of its action has a reward, so that he gets a rapid feedback.
For instance, if you play Space Invaders, you shoot and kill an enemy, you get a reward. Consequently you’ll understand that this action at that state was good.


However, in complex games such as real time strategy games, you will not have a direct reward for each of your actions. Therefore, a bad decision will not have a feedback until hours later.
For example, if we take Age Of Empires II, we can see on the first image that agent decided to build one barrack and focus on collecting resources. Thus in the second picture (some hours after) the enemies destroyed our barrack consequently we have ton of resources but we can’t create an army so we’re dead.


The second big problem is that extrinsic rewards are not scalable. Since in each environment, a human implemented a reward function. But how we can scale that in big and complex environments?
The solution is to develop a reward function that is intrinsic to the agent (generated by the agent itself). This reward function will be called curiosity.
A new reward function: curiosity
Curiosity is an intrinsic reward that is equal to the error of our agent to predict the consequence of its own actions given its current state (aka to predict the next state given current state and action taken).
Why? Because the idea of curiosity is to encourage our agent to perform actions that reduce the uncertainty in the agent’s ability to predict the consequence of its own action (uncertainty will be higher in areas where the agent has spent less time, or in areas with complex dynamics).
Consequently measuring error requires building a model of environmental dynamics that predicts the next state given the current state and the action a.
The question that we can ask here is how we can calculate this error?
To calculate curiosity, we will use a module introduced in the first paper called Intrinsic Curiosity module.
Introducing the Intrinsic Curiosity Module
The need of a good feature space
Before diving into the description of the module, we must ask ourselves how our agent can predict the next state given our current state and our action?
We know that we can define the curiosity as the error between the predicted new state (st+1) given our state st and action at and the real new state.
But, remember that most of the time, our state is a stack of 4 frames (pixels). It means that we need to find a way to predict the next stack of frames which is really hard for two reasons:
First of all, it’s hard to predict the pixels directly, imagine you’re in Doom you move left, you need to predict 248*248 = 61504 pixels!
Second, the researchers think that’s not the right thing to do and take a good example to prove it.
Imagine you need to study the movement of the tree leaves in a breeze. First of all, it’s already hard to model breeze, consequently it is much harder to predict the pixel location of each leaves at each time step.
The problem, is that because you’ll always have a big pixel prediction error, the agent will always be curious even if the movement of the leaves is not the consequence of the agent actions therefore its continued curiosity is undesirable.

So instead of making prediction in the raw sensory space (pixels), we need to transform the raw sensory input (array of pixels) into a feature space with only relevant information.
We need to define what rules must respect a good feature space, there are 3:
- Needs to model things that can be controlled by the agent.
- Needs also to model things that can’t be controlled by the agent but that can affect an agent.
- Needs to not model (and consequently be unaffected) by things that are not in agent’s control and have no effect on him.
Let’s take this example, your agent is a car, if we want to create a good feature representation we need to model:

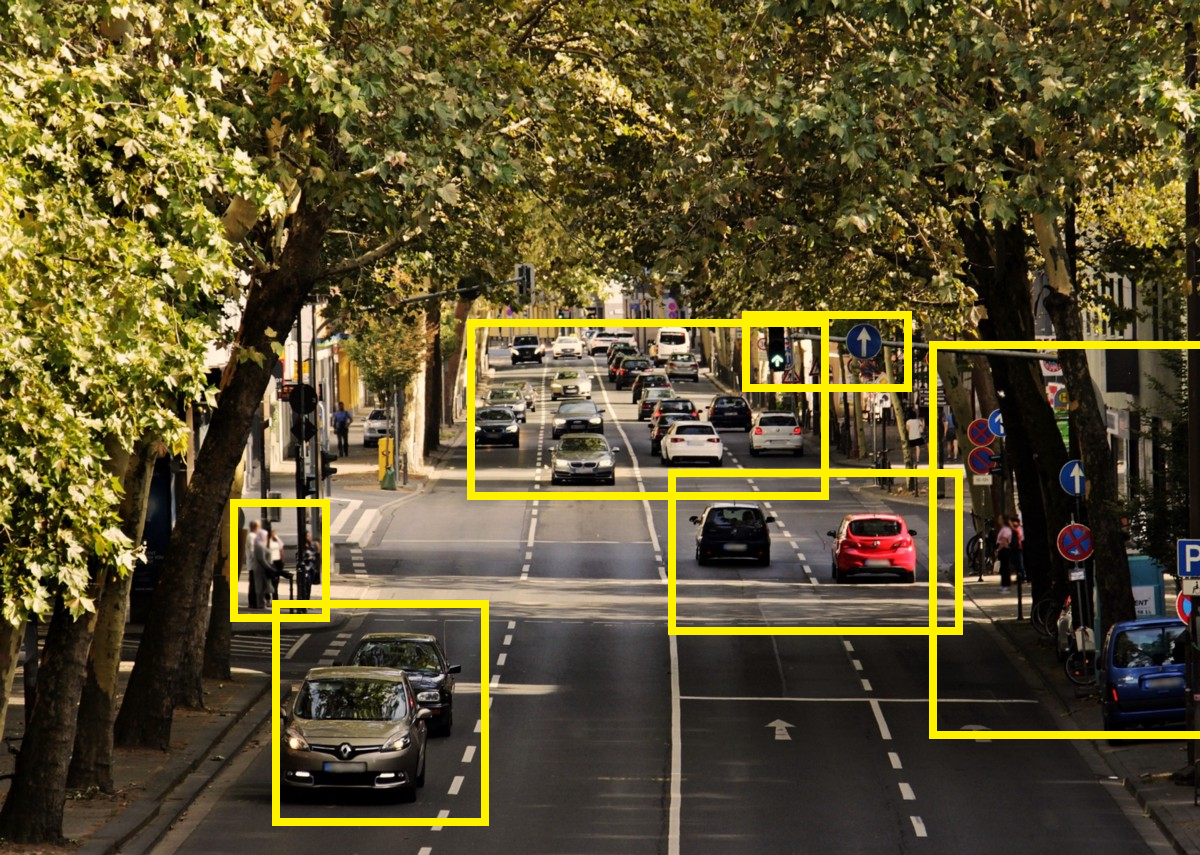
Our car (controlled by our agent), the other cars (we can’t control it but that can affect the agent) but we don’t need to model the leaves (not affect the agent and we can’t control it). This way we will have a feature representation with less noise.
The desired embedding space should:
- Be compact in terms of dimensional (remove irrelevant parts of the observation space).
- Preserve sufficient information about the observation.
- Stable: because non-stationary rewards make it difficult for reinforcement agents to learn.
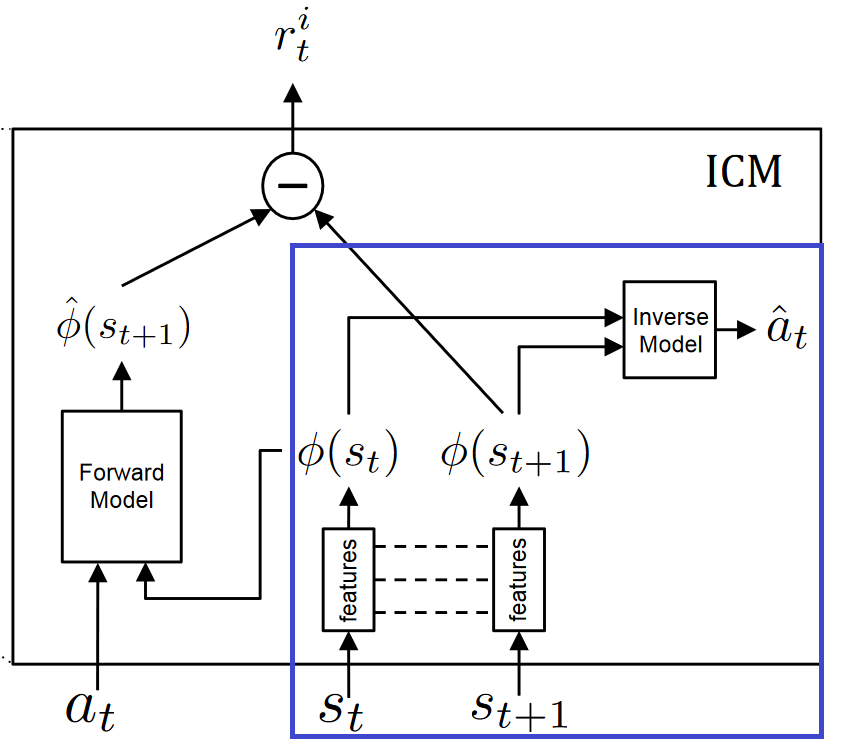
Intrinsic Curiosity Module (ICM)

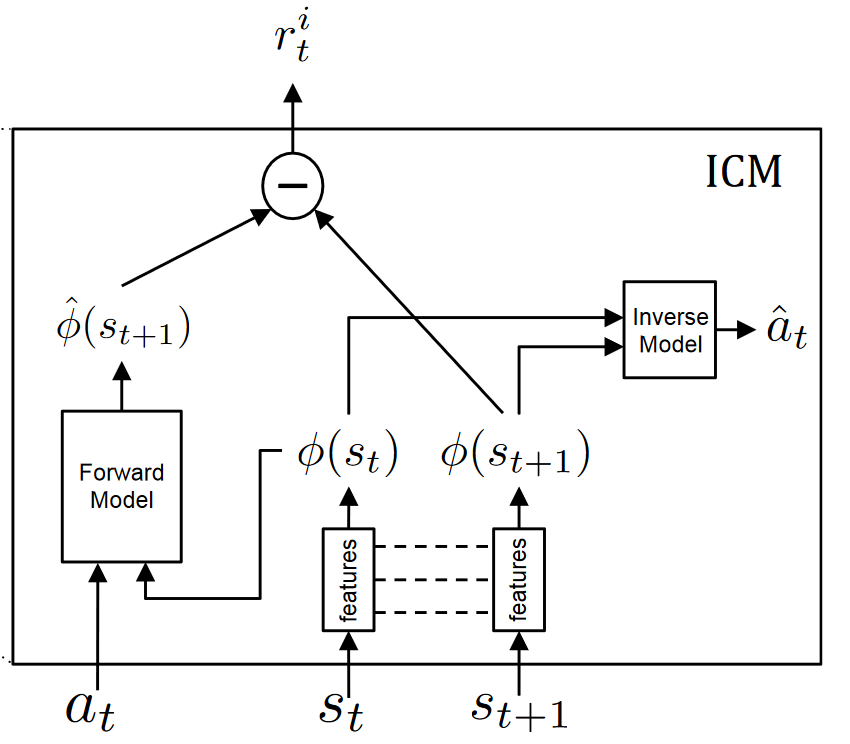
The Intrinsic Curiosity Module is the system that helps us to generate curiosity. It is composed of two neural networks.

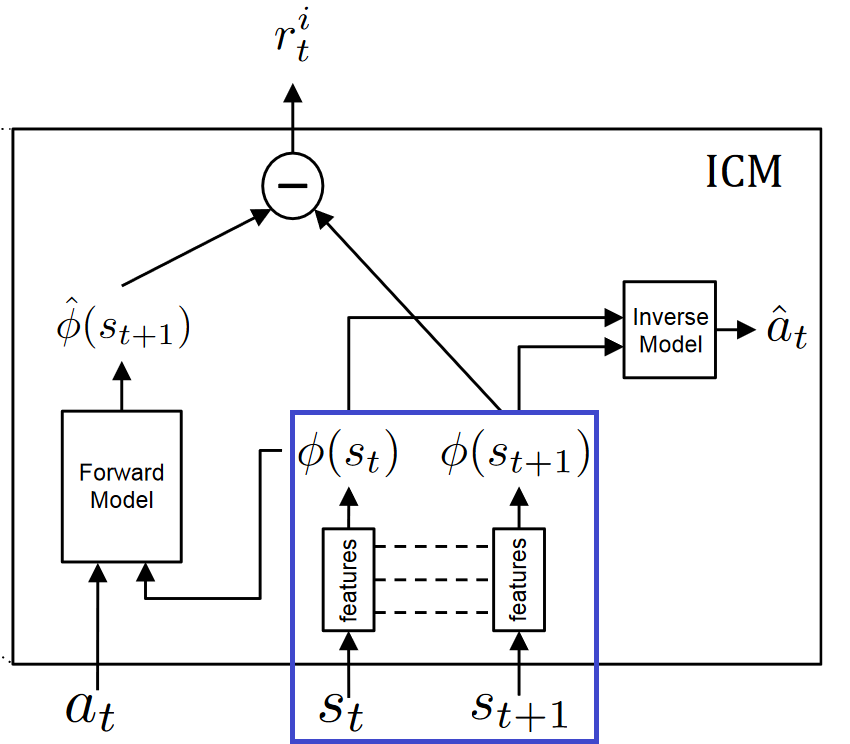
Remember, we want to only predict changes in the environment that could possibly be due to the actions of our agent or affect the agent and ignore the rest. It means, we need instead of making predictions from a raw sensory space (pixels), transform the sensory input into a feature vector where only the information relevant to the action performed by the agent is represented.
To learn this feature space: we use self-supervision, training a neural network on a proxy inverse dynamics task of predicting the agent action (ât) given its current and next states (st and st+1).
Since the neural network is only required to predict the action, it has no incentive to represent within its feature embedding space, the factors of variation in the environment that does not affect the agent itself.

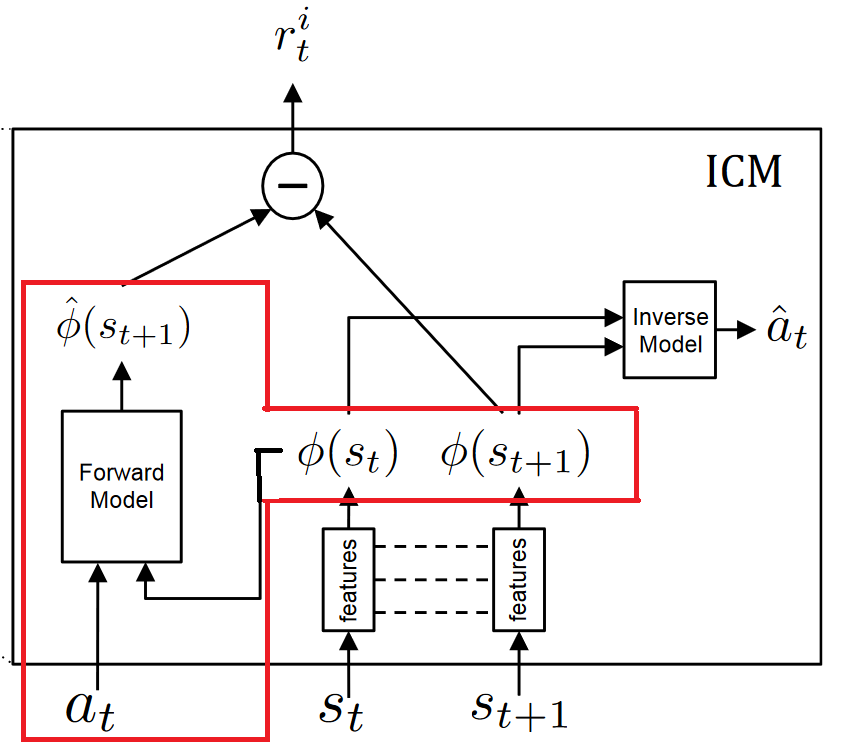
Then we use this feature space to train a forward dynamics model that predicts the future representation of the next state phi(st+1), given the feature representation of the current state phi(st) and the action at.
And we provide the prediction error of the forward dynamics model to the agent as an intrinsic reward to encourage its curiosity.
Curiosity = predicted_phi(st+1) — phi(st+1)
So, we have two models in ICM:
- Inverse Model (Blue): Encode the states st and st+1 into the feature vectors phi(st) and phi(st+1) that are trained to predict action ât.


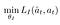
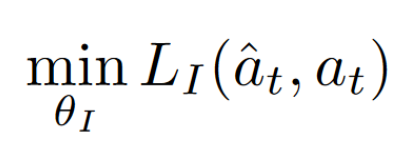
- Forward Model (Red): Takes as input phi(st) and at and predict the feature representation phi(st+1) of st+1.

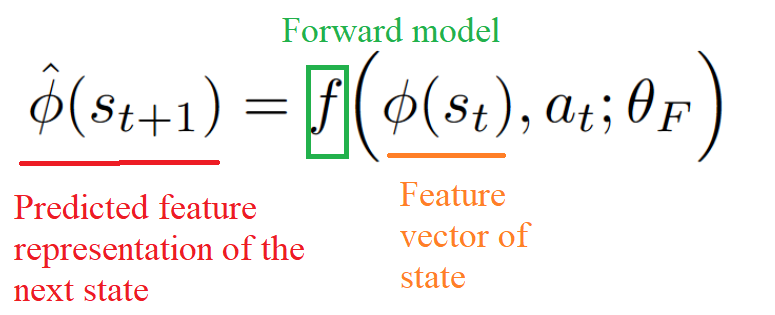
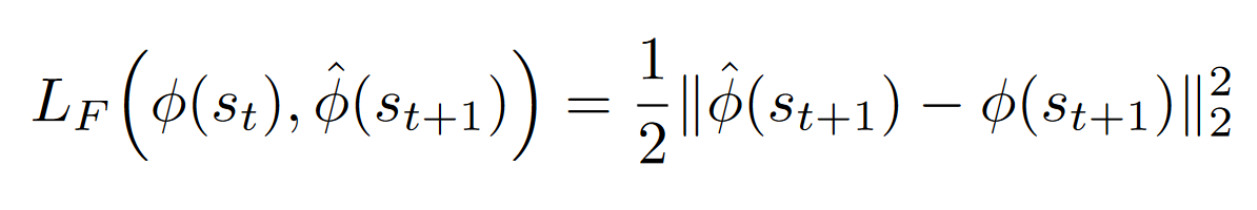
Then mathematically speaking, curiosity will be the difference between our predicted feature vector of the next state and the real feature vector of the next state.


Finally the overall optimization problem of this module is a composition of Inverse Loss, Forward Loss.