
使用mapreduce用貝葉斯分類器訓練
繼上一篇配置好hadoop和eclipse環境之後。我開始做我的實驗。
實驗內容:通過貝葉斯公式對檔案分類到某個資料夾中。
實驗專案連結:
https://download.csdn.net/download/weixin_42615157/10883188
實驗原理:貝葉斯分類器,通過其名字我們就可以知道,是以貝葉斯公式為基礎。
公式如下:
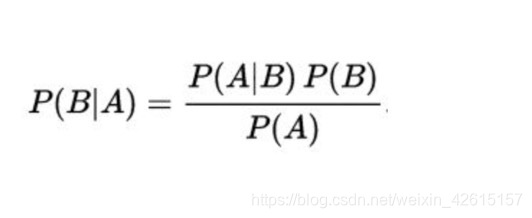
這裡P(B|A)我們稱作後驗概率,P(B)我們稱作先驗概率。在本實驗中我們需要去預測某個檔案屬於哪個資料夾的類的概率。因為檔案中包括很多單詞,我們是通過對已知單詞求其後驗概率然後來對檔案進行預測,即A為單詞,B代表類。我們需要求P(B|A)。一般情況下P(A|B),P(A),P(B)都比較容易得出。我們實驗資料取的是AUSTER和CANA兩個類(具體如下圖顯示)。所以我們需要計算屬於哪個類的概率為多大,如果屬於A的概率大於屬於B的概率,就判斷這個單詞屬於A類。為了計算P(B|A),我們需要分別計算P(A),P(A|B) P(B)。P(A)代表某個單詞的概率,計算方式是所有檔案中這個單詞的數量/所有檔案所有單詞的總數量,所以要統計所有單詞的個數。P(B)代表某個類的概率,也叫做先驗概率。其計算方式是一個類中所有檔案的總數除以所有類檔案的總數。P(A|B)又稱條件概率,其計算方式是一個類中該單詞數量除以該類的單詞總數。這樣我們可以計算出預測文件中某個單詞屬於某個類,設定兩個引數B1,B2來計數,如果預測的單詞是第一類則B1++,如果是第二類則B2++。如果預測文件所有單詞計算完,B1>=B2;則該檔案是第一類,否則是第二類。
資料夾內容

檔案內容:
我們所學mapreduce知識,mapreduce關鍵步驟分成map,shuffle,reduce,三個步驟。Map主要是對所操作物件進行計數,shuffle將map的結果進行整合,reduce對shuffle的結果進行刪減,統計起來。按照上述的操作,我們用mapreduce演算法,採用貝葉斯分類器的原理,對資料進行了訓練。訓練出的模型,我們用於預測。本文資料採用已經下載好的資料檔案中/NBCorpus/country/AUSTR和/NBCorpus/country/CANA兩個資料夾的資料。由於訓練資料給的是一個資料夾且下面資料夾很多,為了方便處理資料和要取一定比例的資料作為測試資料(這裡取百分之二十作為測試資料),我們對原始的資料進行了預處理,在上述所給的資料夾中隨機取了百分之八十的資料當作訓練資料,剩餘的百分之二十的資料當作了測試資料。並分別把他們合併到一個大檔案中。然後對這個大檔案進行處理訓練。對這個大的檔案進行map,reduce操作。為了完成訓練,我們一共使用了五個map,reduce函式進行計算引數。第一個map函式CalcAllWordInTrainData.java,這裡我們統計訓練資料中所有的單詞數,第二個map函式CalcDocNumInClass.java這裡我們統計一個類中間的檔案數,第三個map函式CalcEachWordNumInClass.java這裡我們用來統計一個類中間的每個單詞的數。第四個map函式CalcWordNumInClass.java這裡用來計算一個類中所有單詞的數量。第五個map函式在NaiveBayes.java用來計算該檔案屬於哪個類。
這個檔案屬於哪個類的概率越大,就劃分到哪個類中間。然後把測試資料丟到剛剛訓練好的模型中進行判斷。
程式碼使用流程:
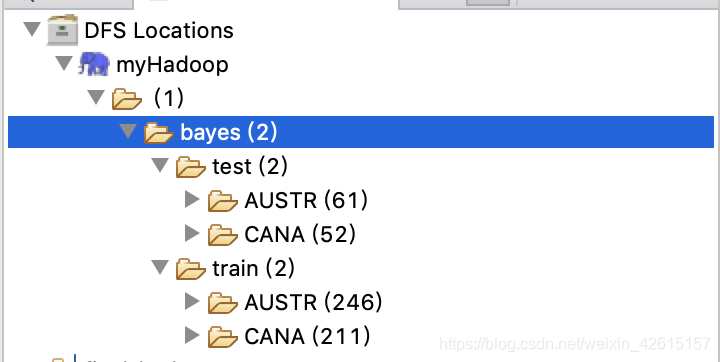
資料夾中有一個GetTestData.java這個在本地跑就可以得到百分之八十的訓練資料(資料直接覆蓋在原來的/NBCorpus/Country/CANA和/NBCorpus/Country/AUSTR),百分之二十的測試資料(在/NBCorpus/Test/AUSTR和/NBCorpus/Test/CANA)下。然後將該資料上傳到HDFS上面。如圖:
然後使用main函式進行測試,計算相關map函式和計算機後驗概率,最後執行Calc_P_R_F1.java執行計算機結果。
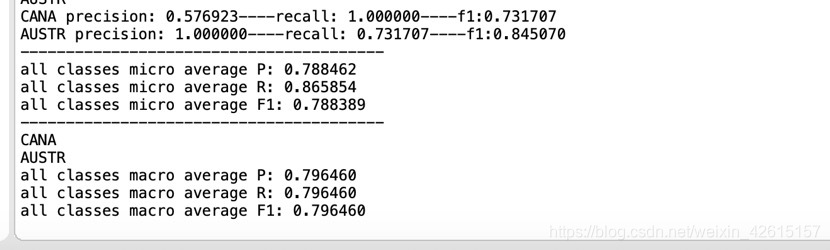
執行結果全在output檔案中:
這是我的結果
注意使用的時候要修改路徑,路徑全保留在utils檔案中。
祝大家好運!