
用Python開始機器學習(6:樸素貝葉斯分類器)
樸素貝葉斯分類器是一個以貝葉斯定理為基礎,廣泛應用於情感分類領域的優美分類器。本文我們嘗試使用該分類器來解決上一篇文章中影評態度分類。
1、貝葉斯定理
假設對於某個資料集,隨機變數C表示樣本為C類的概率,F1表示測試樣本某特徵出現的概率,套用基本貝葉斯公式,則如下所示:
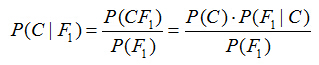
上式表示對於某個樣本,特徵F1出現時,該樣本被分為C類的條件概率。那麼如何用上式來對測試樣本分類呢?
舉例來說,有個測試樣本,其特徵F1出現了(F1=1),那麼就計算P(C=0|F1=1)和P(C=1|F1=1)的概率值。前者大,則該樣本被認為是0類;後者大,則分為1類。
對該公示,有幾個概念需要熟知:
先驗概率(Prior)。P(C)是C的先驗概率,可以從已有的訓練集中計算分為C類的樣本佔所有樣本的比重得出。
證據(Evidence)。即上式P(F1),表示對於某測試樣本,特徵F1出現的概率。同樣可以從訓練集中F1特徵對應樣本所佔總樣本的比例得出。
似然(likelihood)。即上式P(F1|C),表示如果知道一個樣本分為C類,那麼他的特徵為F1的概率是多少。
對於多個特徵而言,貝葉斯公式可以擴充套件如下:
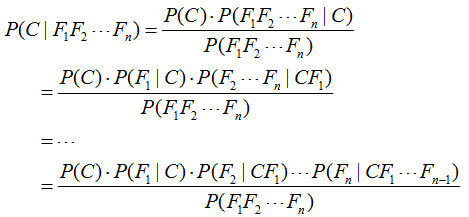
分子中存在一大串似然值。當特徵很多的時候,這些似然值的計算是極其痛苦的。現在該怎麼辦?
2、樸素的概念
為了簡化計算,樸素貝葉斯演算法做了一假設:“樸素的認為各個特徵相互獨立”。這麼一來,上式的分子就簡化成了:
P(C)*P(F1|C)*P(F2|C)...P(Fn|C)。
這樣簡化過後,計算起來就方便多了。
這個假設是認為各個特徵之間是獨立的,看上去確實是個很不科學的假設。因為很多情況下,各個特徵之間是緊密聯絡的。然而在樸素貝葉斯的大量應用實踐實際表明其工作的相當好。
其次,由於樸素貝葉斯的工作原理是計算P(C=0|F1...Fn)和P(C=1|F1...Fn),並取最大值的那個作為其分類。而二者的分母是一模一樣的。因此,我們又可以省略分母計算,從而進一步簡化計算過程。
另外,貝葉斯公式推導能夠成立有個重要前期,就是各個證據(evidence)不能為0。也即對於任意特徵Fx,P(Fx)不能為0。而顯示某些特徵未出現在測試集中的情況是可以發生的。因此實現上通常要做一些小的處理,例如把所有計數進行+1(加法平滑(additive smoothing
例如,在所有6個分為C=1的影評樣本中,某個特徵F1=1不存在,則P(F1=1|C=1) = 0/6,P(F1=0|C=1) = 6/6。
經過加法平滑後,P(F1=1|C=1) = (0+1)/(6+2)=1/8,P(F1=0|C=1) = (6+1)/(6+2)=7/8。
注意分母的+2,這種特殊處理使得2個互斥事件的概率和恆為1。
最後,我們知道,當特徵很多的時候,大量小數值的小數乘法會有溢位風險。因此,通常的實現都是將其轉換為log:
log[P(C)*P(F1|C)*P(F2|C)...P(Fn|C)] = log[P(C)]+log[P(F1|C)] + ... +log[P(Fn|C)]
將乘法轉換為加法,就徹底避免了乘法溢位風險。
為確保掌握樸素貝葉斯分類原理,我們先使用上一篇文章最後的文字向量化結果做一個例子:
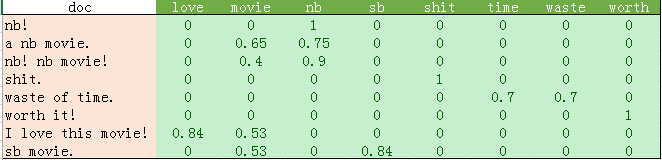
上述訓練集中共8個樣本,其中C=0的3個,C=1的5個。現在,假設給你一個測試樣本"nb movie",使用加一平滑進行樸素貝葉斯的分類過程如下:
P(C=0)=3/8, P(C=1)=5/8。特徵F1="nb", F2="movie"。
分為C=0的概率:P(F1=1, F2=1|C=0) = P(C=0)*P(F1=1|C=0)*P(F2=1|C=0) = 3/8 * (0+1)/(3+2) * (1+1)/(3+2) = 3/8 * 1/5 * 2/5 = 0.03。
分為C=1的概率:P(F1=1, F2=1|C=1) = P(C=1)*P(F1=1|C=1)*P(F2=1|C=1) = 5/8 * (3+1)/(5+2) * (3+1)/(5+2) = 5/8 * 4/7 * 4/7 = 0.20。
分為C=1的概率更大。因此將該樣本分為C=1類。
(注意:實際計算中還要考慮上表中各個值的TF-IDF,具體計算方式取決於使用哪一類貝葉斯分類器。分類器種類見本文最後說明)
3、測試資料
每一個特徵值就是一個單詞的TF-IDF。當然,也可以簡單的使用單詞出現的次數。
使用這個比較大的資料集,可以做一點點資料預處理的優化來避免每次都去硬碟讀取檔案。第一次執行時,把讀入的資料儲存起來,以後就不用每次再去讀取了。
#儲存
movie_reviews = load_files('endata')
sp.save('movie_data.npy', movie_data)
sp.save('movie_target.npy', movie_target)
#讀取
movie_data = sp.load('movie_data.npy')
movie_target = sp.load('movie_target.npy')4、程式碼與分析
Python程式碼如下:
# -*- coding: utf-8 -*-
from matplotlib import pyplot
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
'''
movie_reviews = load_files('data')
#儲存
sp.save('movie_data.npy', movie_reviews.data)
sp.save('movie_target.npy', movie_reviews.target)
'''
#讀取
movie_data = sp.load('movie_data.npy')
movie_target = sp.load('movie_target.npy')
x = movie_data
y = movie_target
#BOOL型特徵下的向量空間模型,注意,測試樣本呼叫的是transform介面
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
#載入資料集,切分資料集80%訓練,20%測試
x_train, x_test, y_train, y_test\
= train_test_split(movie_data, movie_target, test_size = 0.2)
x_train = count_vec.fit_transform(x_train)
x_test = count_vec.transform(x_test)
#呼叫MultinomialNB分類器
clf = MultinomialNB().fit(x_train, y_train)
doc_class_predicted = clf.predict(x_test)
#print(doc_class_predicted)
#print(y)
print(np.mean(doc_class_predicted == y_test))
#準確率與召回率
precision, recall, thresholds = precision_recall_curve(y_test, clf.predict(x_test))
answer = clf.predict_proba(x_test)[:,1]
report = answer > 0.5
print(classification_report(y_test, report, target_names = ['neg', 'pos']))0.821428571429
precision recall f1-score support
neg 0.78 0.87 0.83 135
pos 0.87 0.77 0.82 145
avg / total 0.83 0.82 0.82 280
如果進行多次交叉檢驗,可以發現樸素貝葉斯分類器在這個資料集上能夠達到80%以上的準確率。如果你親自測試一下,會發現KNN分類器在該資料集上只能達到60%的準確率,相信你對樸素貝葉斯分類器應該能夠刮目相看了。而且要知道,情感分類這種帶有主觀色彩的分類準則,連人類都無法達到100%準確。
要注意的是,我們選用的樸素貝葉斯分類器類別:MultinomialNB,這個分類器以出現次數作為特徵值,我們使用的TF-IDF也能符合這類分佈。
其他的樸素貝葉斯分類器如GaussianNB適用於高斯分佈(正態分佈)的特徵,而BernoulliNB適用於伯努利分佈(二值分佈)的特徵。