
Marginally Interesting: Why you don't want real
In case you haven’t noticed yet, real-time is pretty big topic in big data right now. The Wikipedia article on big data goes as far as saying that
"Real or near-real time information delivery is one of the defining characteristics of big data analytics."
There article like this one by the Australian Sydney Morning Herald naming real-time as one of the top 6 issues in big data. At this year’s BerlinBuzzword conference there were at least four talks talking about real-time.
Now if you look at what people are mostly doing, you see that they are
massively scaling out MapReduce or stream processing approaches (as in
Now as I have stated before, I don’t believe that scaling can be the ultimate answer, but we also need better algorithms.
At TWIMPACT, we’ve explored that approach using so-called heavy hitter algorithms from the area of stream mining and found these extremely valuable. Probably their most important property is that they allow you to trade in exactness for speed. This allows you to get started very quickly without having to invest in a data center first just to match the volume of events you have (or do things like deliberately down-sampling which again introduces all kinds of approximation errors).
However, whenever we’re talking to people about our approach this is always a hard point to sell. Typical questions were “How can we guarantee that the approximation error is in check?” Or “Isn’t big data about having all the data and being able to process it all?”
So here is my top 4 list of reasons why you don’t want exact real-time:
Reason 1: Results are changing all the time anyway
First of all, if you have high volume data streams, your statistics will constantly change. So even if you compute exact statistics, the moment you show the result, the true value will already have changed.
Reason 2: You can’t have real-time, exactness, and big data
Next, real-time big data is very expensive. As explained very well on slide 24 of this talk by Tom Wilkie, CTO of Acunu, there is something like a “real-time big data triangle of constraints”
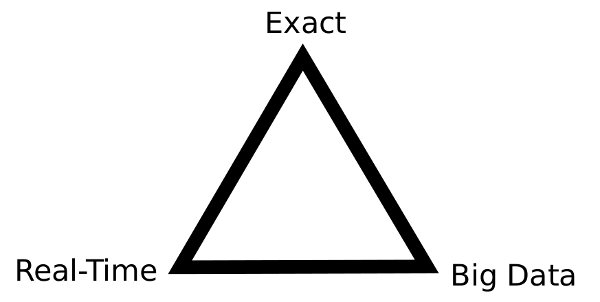
You can have only two: Real-time and Exactness (but no Big Data), Real-Time and Big Data (but no Exactness), or Big Data and Exactness (but not Real-Time). That is, unless you’re willing to pay a lot of money.
Reason 3: Exactness is not necessary
Unless you do billing, exact statistics seldom matter. Typical applications for real-time big data analysis like event processing for monitoring are about getting a quick picture of “what’s happening”. But that means you’re only interested in the top most active items in your stream. So it’s the ranking that counts and that won’t be affected by a small amount of exactness.
Of course, this also depends on the distribution of your data. The worst case for stream mining is data which is uniformly distributed (in the sense that all the events occur with equal probability). But for real world data, this is hardly ever the case. Instead, you have a few “hot” items and a long tail of mostly inactive items which is often of little interest to you.
Reason 4: You already have an exact batch processing system in place
Often, you already have a standard data warehouse which can give you exact numbers if you need them, but you start to get interested in a more real-time view. In that case it doesn’t really make sense to spend a fortune on an infrastructure to give you exact results in real-time just to get an idea of what’s happening.
Put differently, real-time analyses and standard batch-oriented analyses have quite different roles in your business. Batch-oriented number crunching is done once a month to do the accounting while real-time is used for monitoring. And for that you don’t need exact numbers as much as you do for accounting.
Posted by Mikio L. Braun at 2012-08-30 13:16:00 +0200
blog comments powered by Disqus