Data Science: A Piece Of Cake
Data and Data Preprocessing
So, the first of these steps is to gather the data and process it. Just like you would buy the ingredients.
You also need to make sure that the data is relevant to the problem that you’re about to solve. How much data you require, and in what form (or format) do you need it. Do you want sugar cubes, or ground sugar? Real world datasets are usually in tabular form like .xls, .csv, or .json (just to name a few).
There’s a vast number of different algorithms available to help you with data cleaning, and pre-processing. The data you train your model with drastically affects its performance. Just like the recipe determines the cake’s taste.
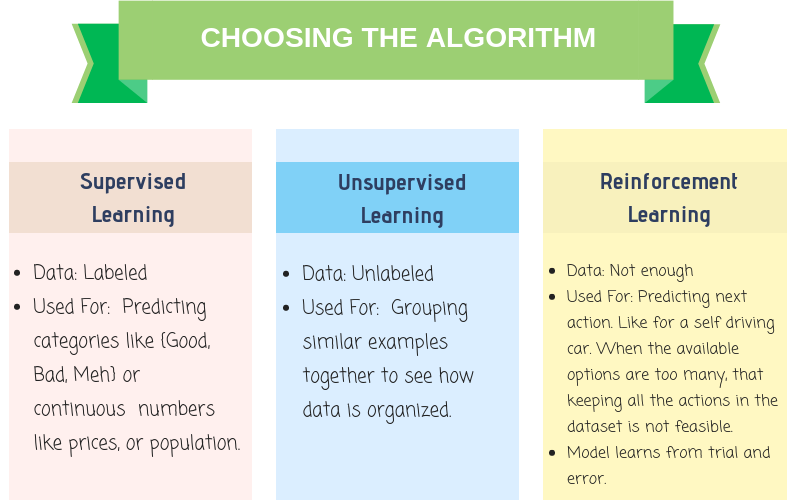
Types of Datasets
A dataset is the collection of all the examples in a proper format. It can either be a labeled
Labeled dataset is when you have the feature values, along with its outcome. Whereas in an unlabeled dataset you only have the feature values.
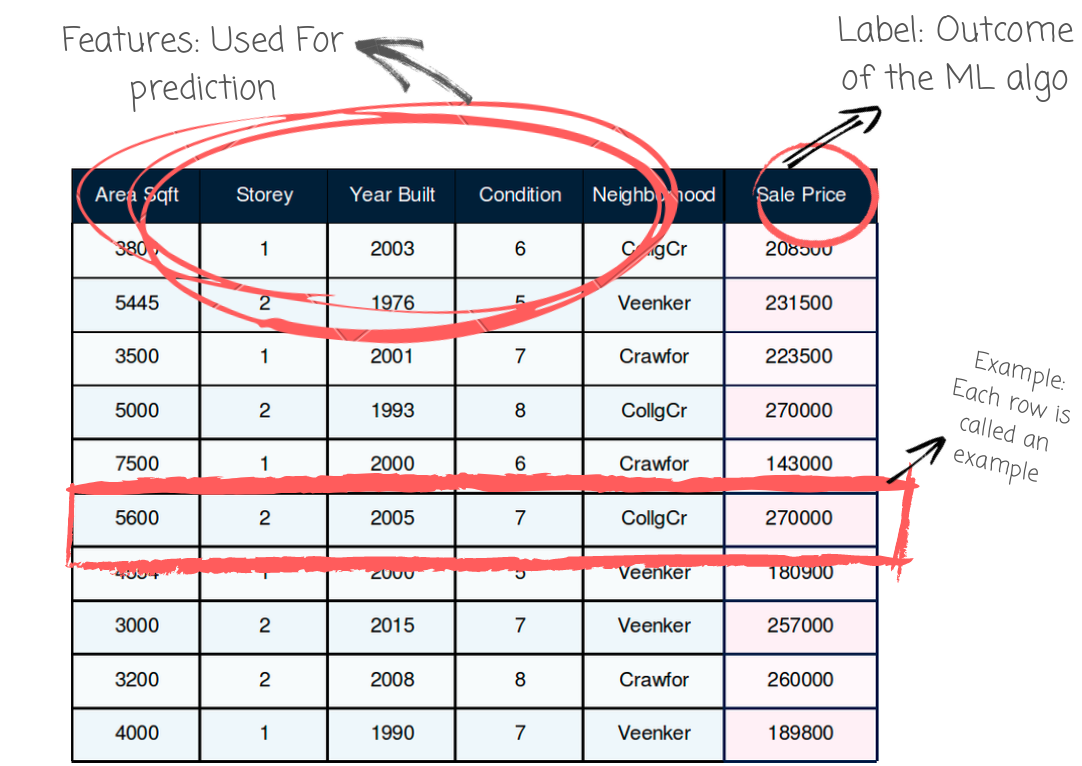
Features are the different ingredients like: milk, butter, sugar and eggs can be four different features. The outcome of these features is a cake. It’s the features that help you get to the outcome.
This is what a real dataset looks like:

Choosing a Machine Learning Algorithm
Once you have your dataset ready, it’s now time to use a machine learning algorithm. This is where you put the cake batter into the oven.
Your dataset, and the labels help you determine which kind of algorithm to use. Just like if you wanted to make some ice-cream instead, you wouldn’t need an oven but a refrigerator. Your ingredients and recipe would also change.