
Introduction to data cleaning using Pandas
Introduction to data cleaning using Pandas
I’ve been using Excel for data cleaning until I discovered how powerful pandas are for data analysis and data cleaning. In this article I want to go over basics of how to use pandas for cleaning data in excel files.
Importing data and taking a look
As a first step, lets look at the raw data we have, to understand what needs to be done as part of cleaning. I’m skipping installation of python and Jupyter notebook in this article. If you are completely new to python and want to install Jupyter, here are some links to guide you through the procees-
I have the Anaconda Navigator installed on my Mac. Follow along this link to install the software- https://docs.anaconda.com/anaconda/install/
Once you have Anaconda installed, click on the jupyter notebook


If you are opening up jupyter for the first time, command prompt should provide you with a local host url. Enter this url in your browser window and the jupyter notebook should open up.
To follow along , download the Austin_Animal_Center_Intakes.csv file here. Save the file to your local and run this piece of code in jupyter.
Importing the file into pandas
import pandas as pd
import numpy as np
import os
filepath = “/Users/ayyagamv/Desktop/Tableau/Assignments/Capstone”
filename = “Austin_Animal_Center_Intakes.csv”
filePathFileName = filepath + “/” + filename
outputFile=os.path.join(“/Users/ayyagamv/Desktop/Tableau/Assignments/Capstone/Austin_Animal_Center_Intakes_cleaned.csv”)
df = pd.read_csv(filePathFileName)

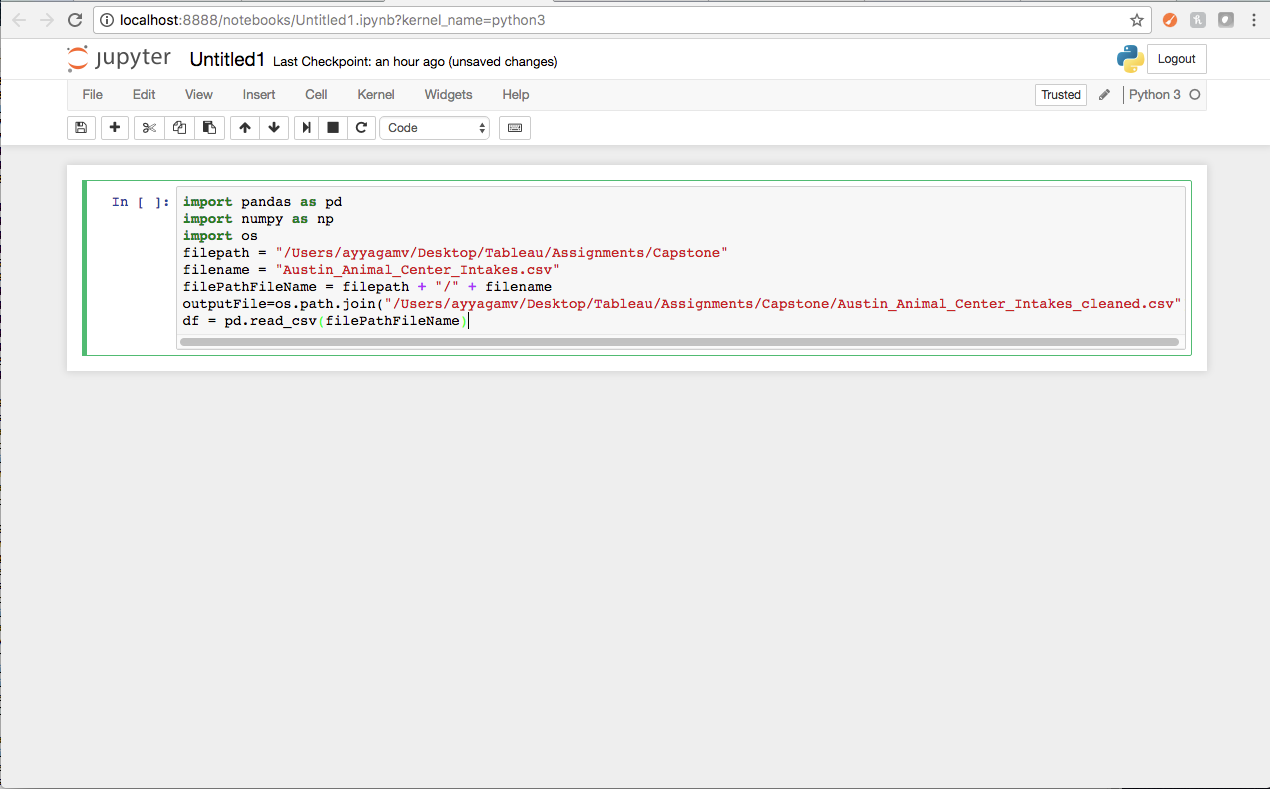
Here we import pandas using the alias ‘pd’, then we read in our data.
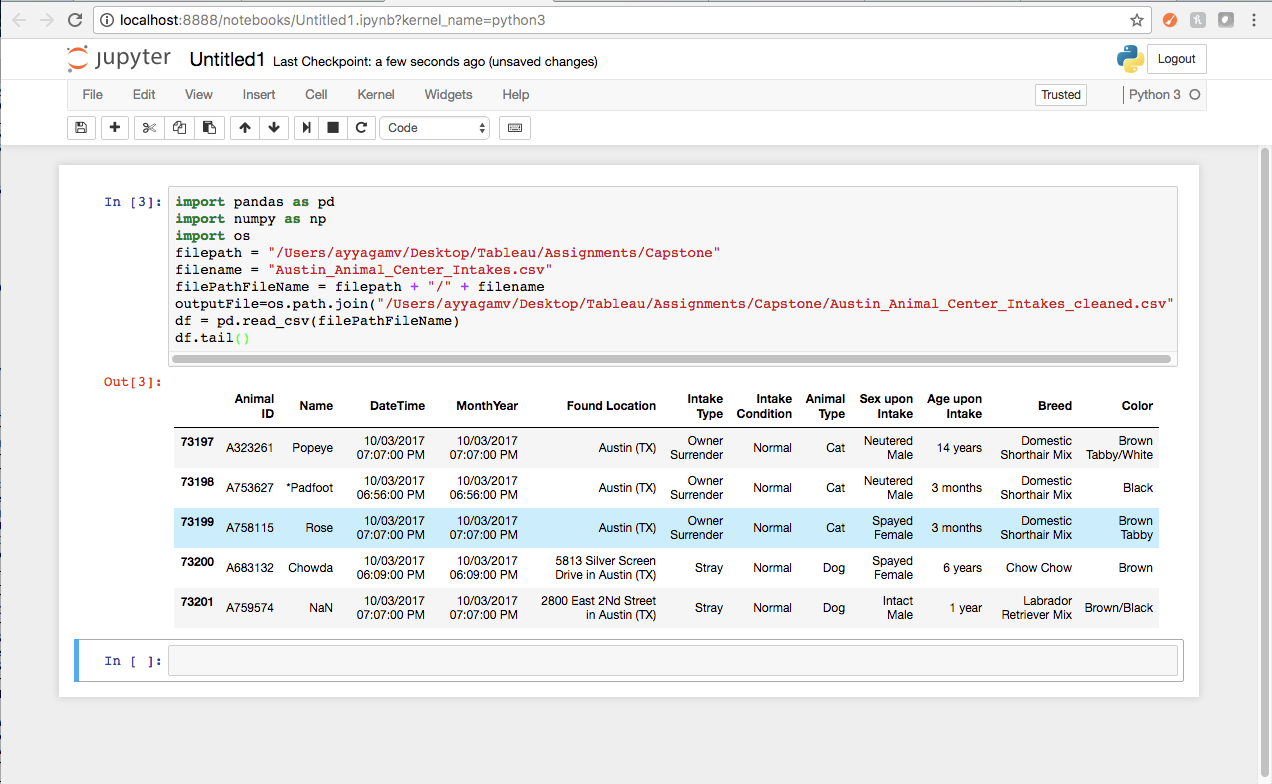
df.head() - shows us the first 5 rows and headers - it gives us an idea what to expect. df.tail() - shows us the last 5 rows. Lets try df.head.
df.head()-Output

df.tail()-Output

df.columns -Output
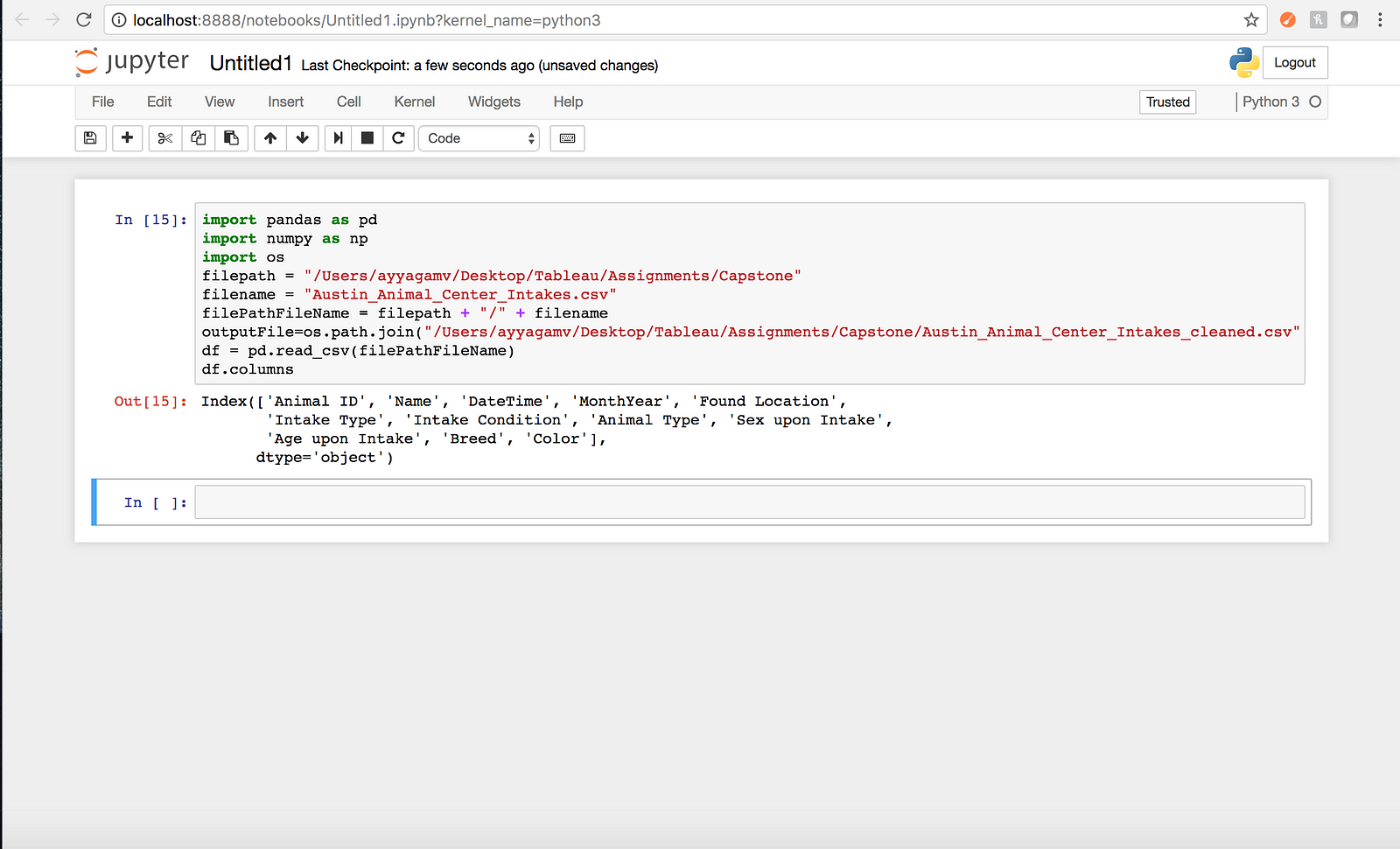
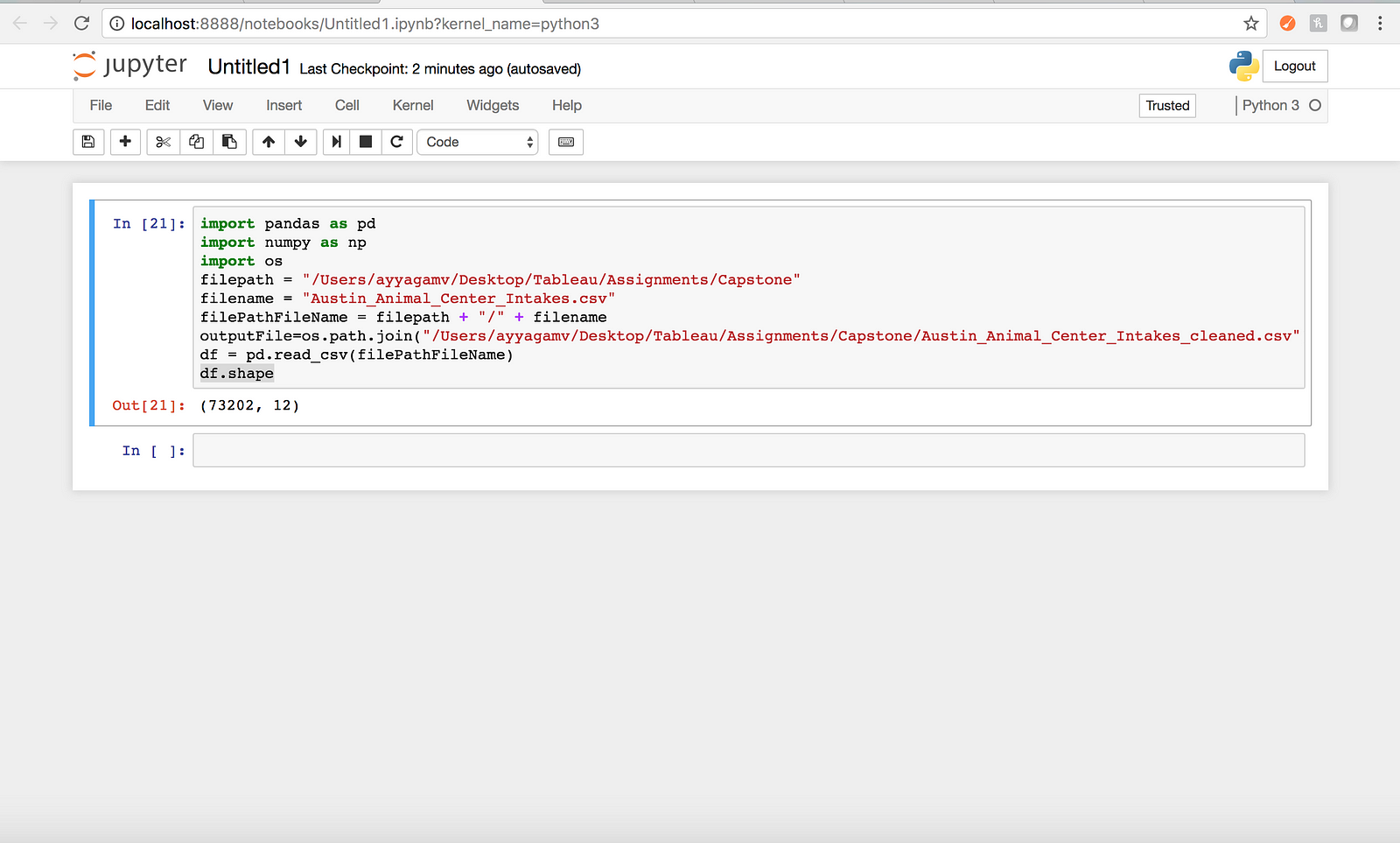
df.shape- Output
df.isnull()- Output

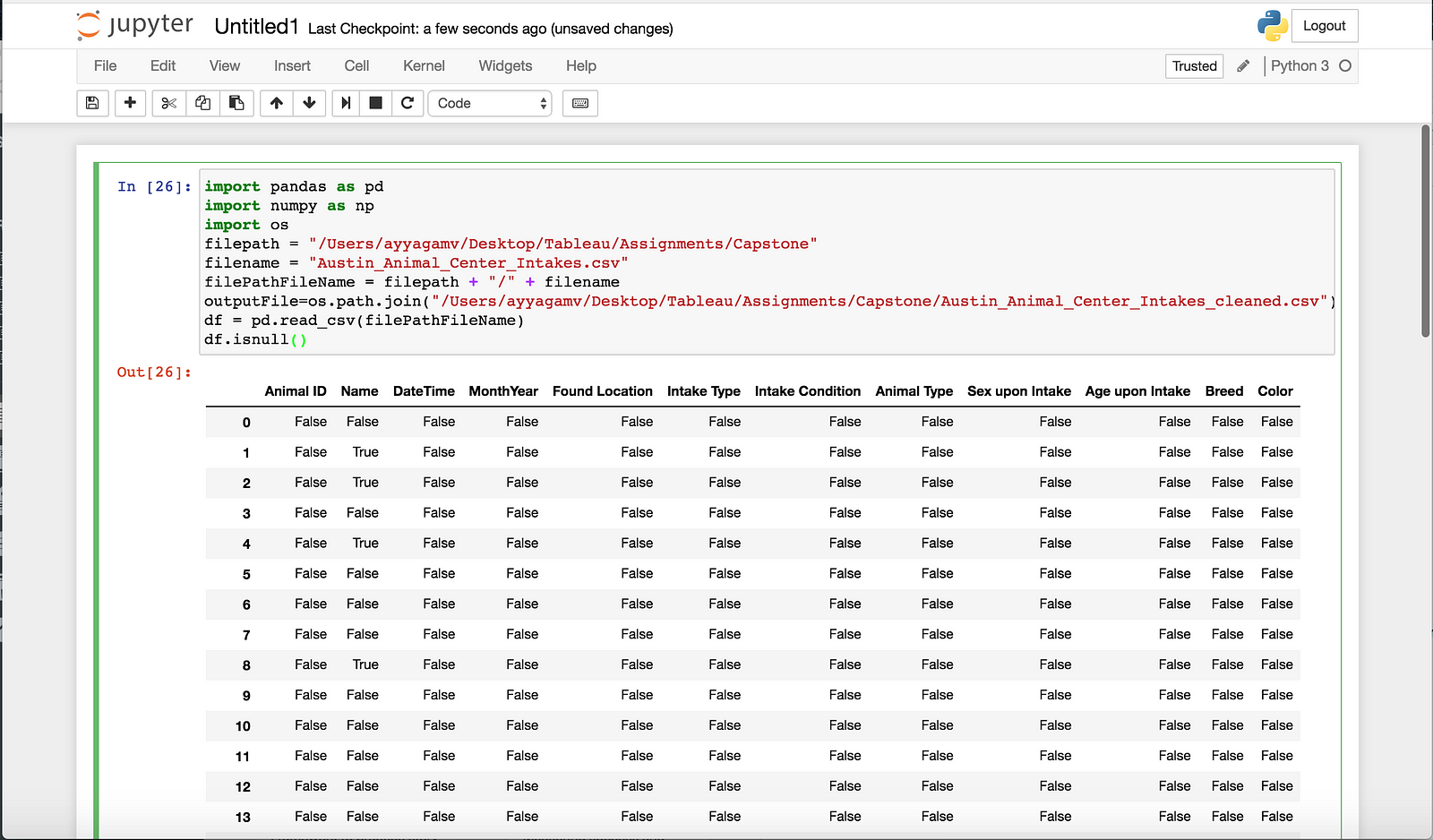
Looking at the first and last 5 rows, I can see that some cells in the Name column are blank, panda displays this as NaN. The second obvious issue I see is that some cells in the name field have an asterisk*. We would ideally want to remove the asterisk.
Lets replace the cells without any data in the Name column with the value ‘None’ using this line
df = df.astype(object).where(pd.notnull(df),None)

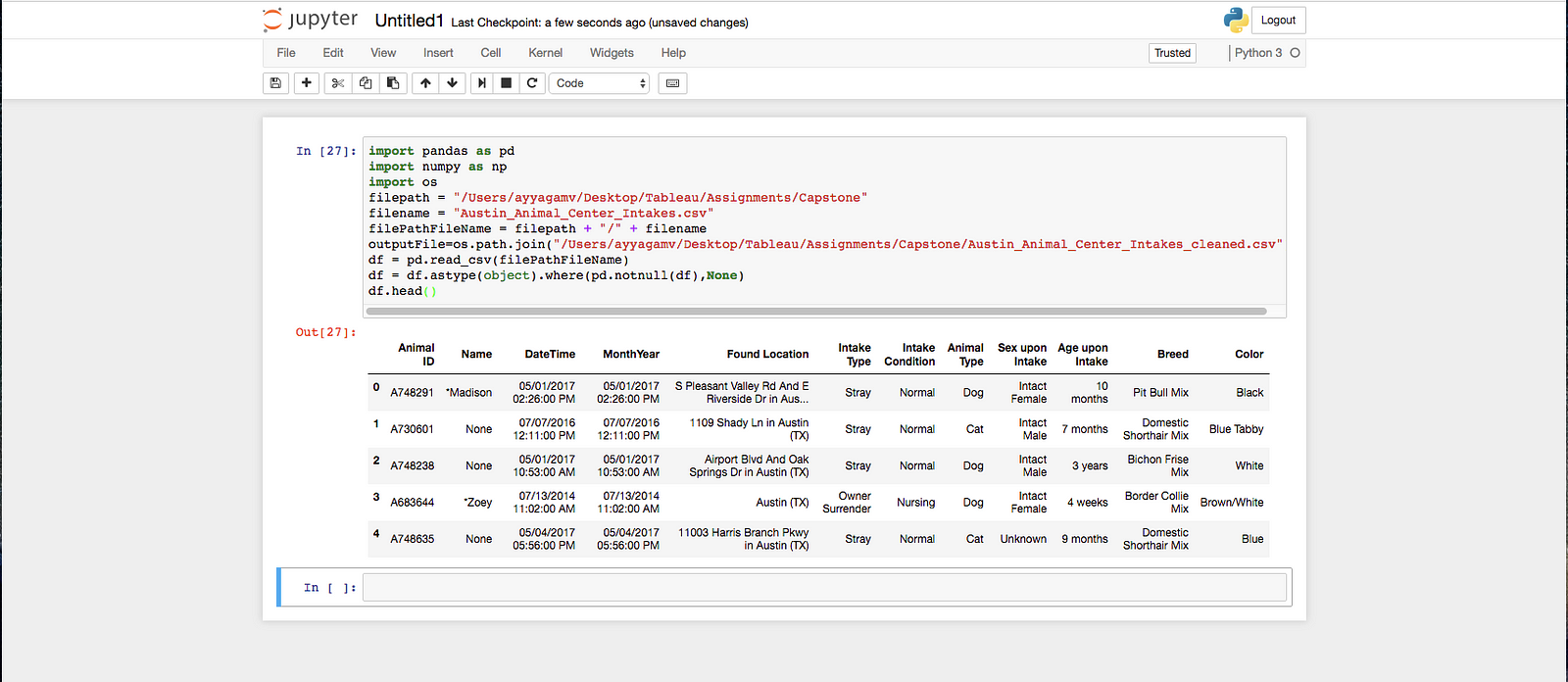
Onto the next issue with data. I want to remove the asterisk in the Name column. It can be done with this line
df[‘Name’]=df[‘Name’].apply(lambda x:str(x).replace(‘*’,’’))
Lets take a look now at what we have

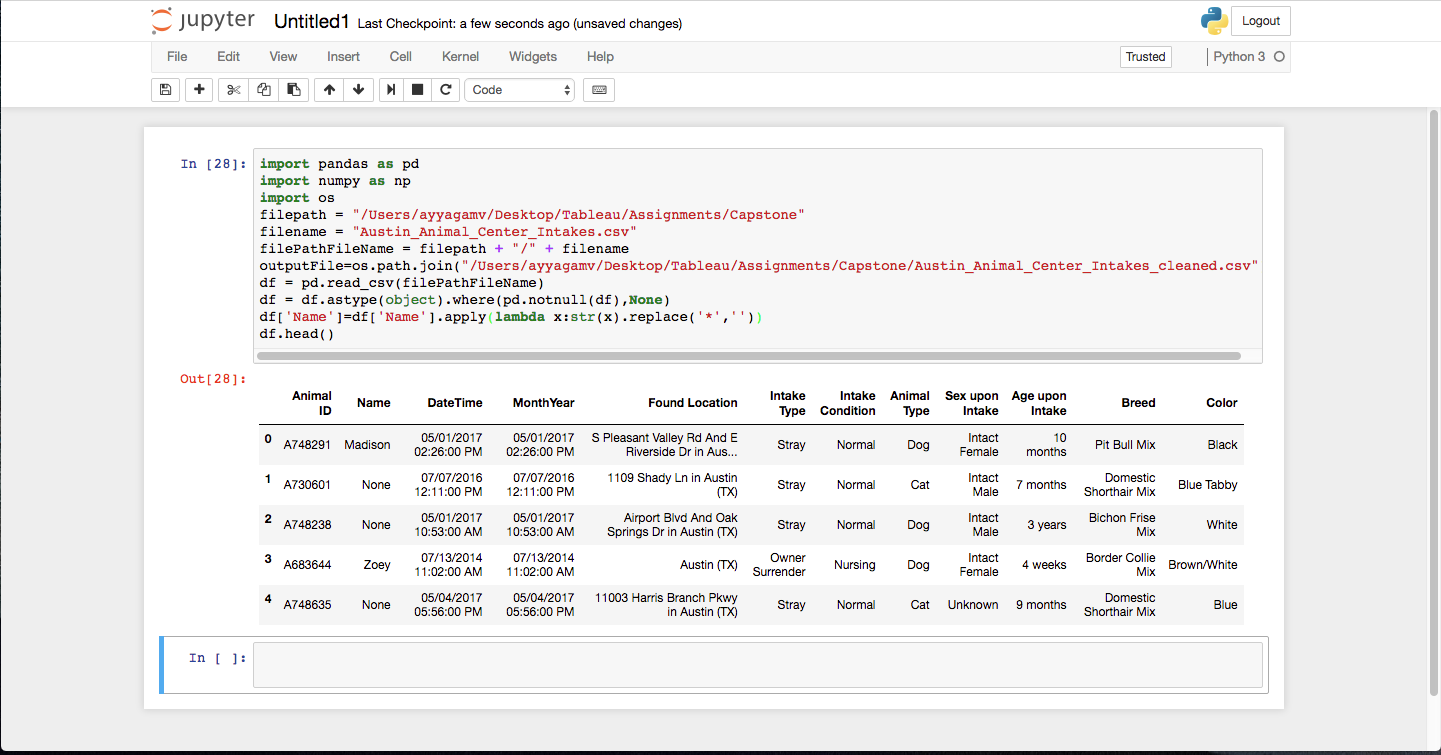
I can also see that the MonthYear column has time which is not required in that column. Lets ged rid of that.
Firs step is to convert the data frame object to date.time format and then replace the date time with just date. This can be done with just 2 lines of code.
df[‘MonthYear’] = pd.to_datetime(df[‘MonthYear’])
df[‘MonthYear’] = df[‘MonthYear’].apply(lambda x: x.date())

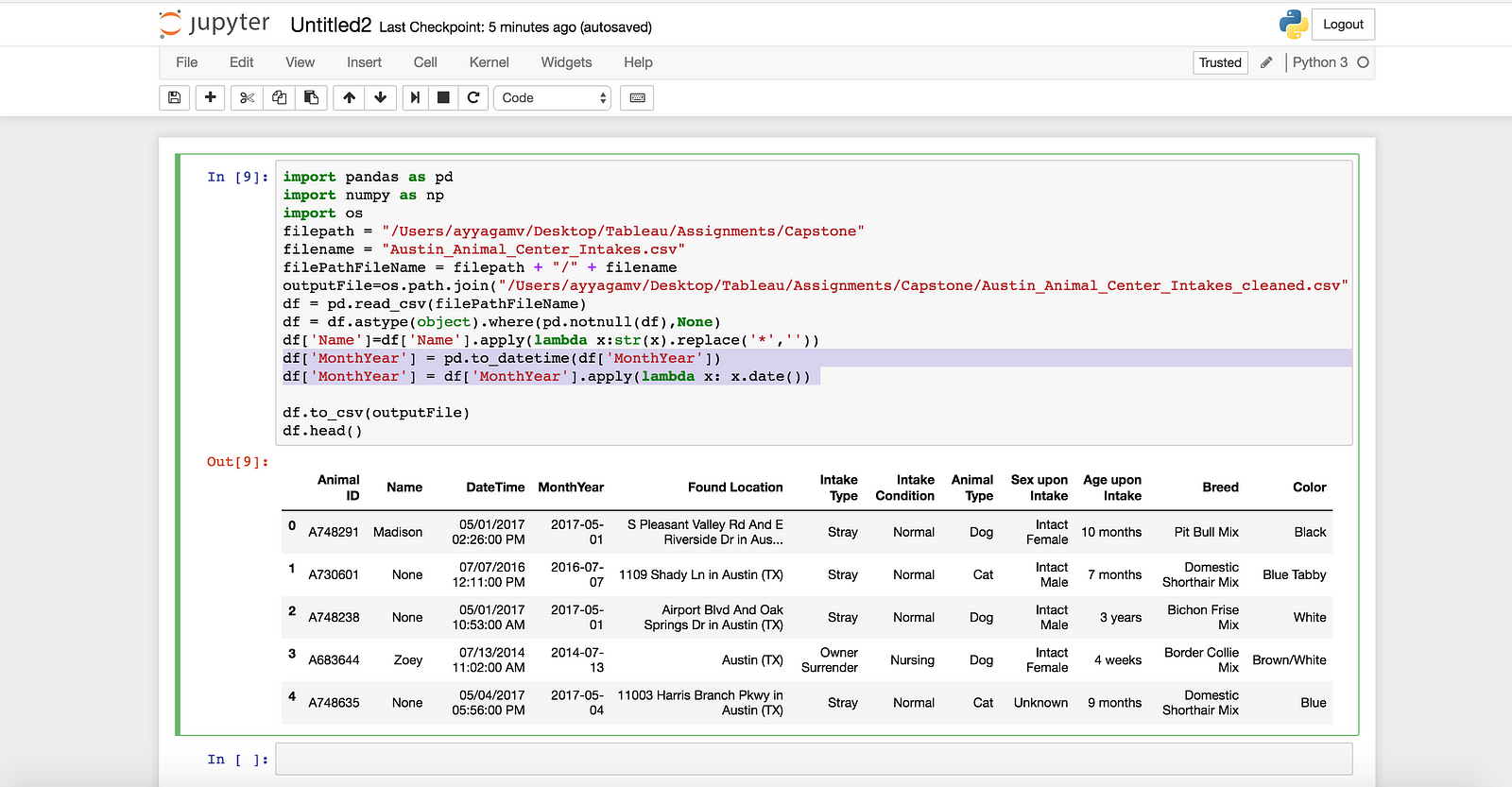
Finally, write the output to an other file and specify the location of the file.
outputFile=os.path.join(“/Users/ayyagamv/Desktop/Tableau/Assignments/Capstone/Austin_Animal_Center_Intakes_cleaned.csv”)
df.to_csv(outputFile)
This was a brief introduction to data cleaning using pandas. The data is now at a point where it can be imported into Tableau for further analysis.