
Druid @ Airbnb Data Platform
Airbnb serves millions of guests and hosts in our community. Every second, their activities on Airbnb.com, such as searching, booking, and messaging, generate a huge amount of data we anonymize and use to improve the community’s experience on our platform.
The Data Platform Team at Airbnb strives to leverage this data to improve our customers’ experiences and optimize Airbnb’s business. Our mission is to provide infrastructure to collect, organize, and process this deluge of data (all in privacy-safe ways), and empower various organizations across Airbnb to derive necessary analytics and make data-informed decisions from it.
The primary way high-level analytics is exposed and shared within the company is through various dashboards. A lot of people use these dashboards every day to make various decisions. Dashboards also allow real-time tracking and monitoring of various aspects of our business and systems. As a result, the timeliness of these dashboards is critical to the daily operation of Airbnb. However, we are faced with three challenges:
First, it would take a long time to aggregate data in the warehouse and generate the necessary data for these dashboards using systems like Hive and Presto at query time. Hive/Presto have to read all the data and aggregate them on demand, resulting in all necessary computation getting invoked at query time. Even if those engines are used to pre-compute the aggregation and store them, the storage format is not optimized for repeated slicing and dicing of data that analytics queries demand.
Second, the system needs to be reliable and scalable. It is powering core analytics use cases at Airbnb, hence any downtime will have severe impact on the business and its employees. Also, the volume of data, queries, and users continue to grow and our analytics system should be able to cope with increasing demand.
Third, we need a system that integrates well with our data infrastructure that is based on open source frameworks. For example, most of our datasets are stored in Hadoop, and we use Kafka and Spark Streaming to process our data streams.
This is where Druid comes in.
Advantages of Druid

Fast query time
With predefined data-sources and pre-computed aggregations, Druid offers sub-second query latency. The dashboards built on top of Druid can be noticeably faster than those built on others systems. Compared to Hive and Presto, Druid can be an order of magnitude faster.
Architecture that Offers Reliability and Scalability
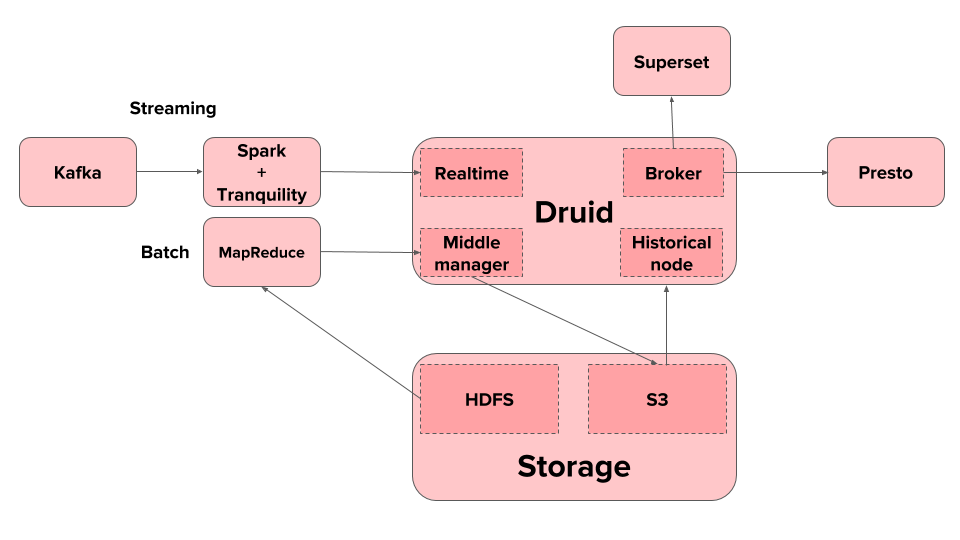
Druid architecture is well separated out into different components for ingestion, serving, and overall coordination. We have found this componentized architecture to be reliable and stable for our workload, and it has allowed us to scale the system easily as needed.
Druid’s architecture of separating data storage into deep storage for long term storage of data while caching the data temporarily in the historical node has worked well for us. Keeping the analytical data permanently in S3 gives us disaster recovery for free and allows us to easily manage upgrade and upkeep of cluster hardware (e.g. easily switch node types to take advantage of the latest hardware).
Integration with Open Source Frameworks
Druid also integrates smoothly with the open source data infrastructure that’s primarily based on Hadoop and Kafka:
- Druid’s API allows us to easily ingest data from Hadoop for batch analytics
- Druid enables real-time analytics via stream processing engines. Druid provides a streaming client API, Tranquility, that is integrated with streaming engines such Samza or Storm and can be integrated with any other JVM based streaming engine. At Airbnb, streaming ingestion of data into Druid for real time analytics is implemented through Spark Streaming jobs employing the Tranquility client.
- Druid is well integrated with Apache Superset, an open source data visualization system developed and open sourced by Airbnb. Superset serves as the interface for users to compose and execute analytics queries on Druid and visualize the results.
How Airbnb Uses Druid: Dual Cluster Configuration
At Airbnb, two Druid clusters are running in production. Two separate clusters allow dedicated support for different uses, even though a single Druid cluster can handle more data sources than what we need. In total we have 4 Brokers, 2 Overlords, 2 Coordinators, 8 Middle Managers, and 40 Historical nodes. In addition, our clusters are supported by one MySQL server and one ZooKeeper cluster with 5 nodes. Druid clusters are relatively small and low cost comparing with other service clusters like HDFS and Presto.
Of the two Druid clusters, one is dedicated to centralized critical metrics services. With the goal of serving all the dashboards at Airbnb, users can easily define their metrics through simple YAML files. Users can view their dashboards and metrics on Superset without knowing anything about Druid.
All the batch jobs are scheduled with Airflow, ingesting data from our Hadoop cluster.
All the real-time and other data sources for self-service users are handled by the other Druid cluster. Real-time data is ingested through Spark Streaming + Tranquility client setup.
Improving Druid Usage at Airbnb
While Druid provides many powerful widely applicable features that satisfy most businesses, we did implement features within or on top of Druid to better serve our special use cases.
A Framework for Instantly Answering Ad-hoc Analytics Queries
Airbnb has a large number of data scientists embedded in different business teams. Each of them may have ad-hoc questions about the business that need insight derived from the data, which often requires arbitrary ways to aggregate data.
To meet this need, we have built a self-service system on top of Druid that allows individual teams to easily define how the data their application or service produces should be aggregated and exposed as a Druid data source. Data scientists and analysts can then query Druid to answer ad-hoc questions.
Users define their data source with configuration as simple as below. Real-time data from Kafka and batch data from HDFS/S3 will be ingested according to the config file.

Druid aggregates its real-time data over windows of 5 minutes, plus 1-minute latency from pipelines.
The real-time streaming from Druid empowers us to enable a number of sophisticated functionalities for our users. One of the interesting use cases for real-time ingestion is anomaly detection. With real-time data ingested and aggregated quickly in Druid, we can detect anything in production that does not conform to an expected pattern very quickly.
Integration with Presto
Druid has a mature query mechanism with JSON over HTTP RESTful API, in addition to SQL query support with recent versions. However, one of the limitations of Druid is that it does not yet allow cross data source queries (simplistically speaking, a join query). All the aggregate queries are limited to a single data-source. In Airbnb however, we do have scenarios where multiple data-sources with overlapping dimensions need to joined together for certain queries. The alternative is to keep all the data in one single data-source, which is not optimal in our scenario for various reasons including cadence of data generation, source of data being different (e.g. different services produce the data) and so on. However, the need for cross data source query is real and has recently become a hard requirement.
To cater to these scenarios, we have developed an in-house solution that is based on Presto. Specifically, we introduced a Presto connector for Druid that can push down queries to Druid by individual data sources, and can retrieve and join the data to complete the execution of the cross data-sources query. The details of the implementation are still evolving and is out of scope for this article. We will provide more details in a separate post in the future.
Improve backfill performance
The secret to why Druid queries are much faster than other systems is that there is a cost imposed on ingestion . Every data segment needs to be ingested from MapReduce jobs first before it is available for queries. This works great in a write-once-read-multiple-times model, and the framework only needs to ingest new data on a daily basis.
However, problems arise when an owner of a data source wants to redesign it and regenerate historical data. It means data over past years needs to be re-ingested into Druid to replace the old ones. This requires a very large ingestion job with a long running MapReduce task, making it expensive especially when error happens in the middle of re-ingestion.
One potential solution is to split the large ingestion into several requests in order to achieve better reliability. However, query results will be inconsistent as it will be computed from a mix of existing old as well as newly ingested data. Backfill jobs are actually more frequent than we expected as user requirements and ingestion framework functionalities evolve, making its performance a pain point that begs improvement.
To solve this, we have designed a solution that basically keeps all the newly ingested segments inactive until explicit activation. This enables the ingestion framework to split the source of data into smaller intervals with acceptable sizes. The framework then ingests these intervals in parallel (as parallel as Yarn cluster resources allow). Since the newly ingested data is still inactive, the segments are hidden in the background and there’s no mix of different versions of data when computing results for queries being executed while backfill ingestion is still in progress. When we activate the latest version of segments for the data source, it will be refreshed with the new version without downtime. Split and refresh greatly improved backfill performance and has made backfills that used to run longer than a day finish in one hour now.
Monitoring and operation
We monitor Druid continuously for reliable service and best performance. Druid is robust and resilient to node failures. Most nodes failures are transparent and unnoticeable to users. Even if a role that is a single point of failure (like Coordinator, Overlord, or even ZooKeeper) fails, Druid cluster is still able to provide query service to users. However, to honor our SLA with users, any service outage should be caught in time or even before failure happens.
Like other clusters, we monitor every machine in the Druid cluster by collecting machine statistics and raising an alert if any instance reaches its capacity or goes into bad state. To monitor overall cluster availability, we ingest one piece of canary data into Druid every 30 minutes, and check if the query result from each Broker node matches the latest ingested data every 5 minutes. Any degradation in service, including query, ingestion, or downstream HDFS instability, can be detected within the SLA.
Druid has been running at Airbnb for years and it is one of the systems with the lowest maintenance cost. Druid’s multi-role design makes operations easy and reliable. Cluster administrators can adjust cluster configuration and add/remove nodes based on the monitoring metrics. As data grows in our Druid cluster, we can continue adding historical node capacity to cache and serve the larger amount of data easily. If the real-time ingestion workload shows an uptick, we can easily add middle manager nodes accordingly. Similarly, if more capacity is needed to handle queries, we can increase the broker node count. Thanks to Druid’s decoupled architecture, we were able to perform a large operation that migrated all data in deep storage from HDFS to S3 with a newly rebuilt cluster, with only minutes downtime.
Challenges and future improvements
While Druid has served us well in our data platform architecture, there are new challenges as our usage of Druid grows within the company.
One of the issues we deal with is the growth in the number of segment files that are produced every day that need to be loaded into the cluster. Segment files are the basic storage unit of Druid data, that contain the pre-aggregated data ready for serving. At Airbnb, we are encountering a few scenarios where a large number of our data sources sometime need to be recomputed entirely, resulting in a large number of segment files that need to be loaded at once onto the cluster. Currently, ingested segments are loaded by coordinators sequentially in a single thread, centrally. As more and more segments are produced, the coordinator is unable to keep up and we see increasing delay between the time an ingestion job completes and the time the data becomes available for querying (after being loaded by the coordinator). Sometimes the delay can be hours long.
The usual solution is to attempt to increase the target segment size and thus reduce segment count. However, in our usage, the input volume of data to produce a larger segment (by a Hadoop worker running ingestion task) is so high that the Hadoop job would run for too long crunching that data, and many times would fail due to various reasons.
We are currently exploring various solutions, including compacting segments right after ingestion and before they are handed off to the coordinator, and different configurations to increase the segment size without jeopardizing the ingestion job stability when possible.
Conclusion
Druid is a big data analytics engine designed for scalability, maintainability, and performance. Its well factored architecture allows easy management and scaling of Druid deployment, and its optimized storage format enables low latency analytics queries. We have successfully deployed Druid at Airbnb for our use cases and see continued growth in its footprint as our user base and use cases grow.