
Faster-RCNN的關鍵點總結
“ 要得到,你必須要付出,要付出,你還要學會堅持。如果你真的覺得很難,那你就放棄,但放棄你就不要抱怨。”
2018年8月31日12:00:00
8月的最後一天了~
真的好累
堅持,再堅持。
一想到上了這麼多年學就是為了現在,就~
好吧,不廢話了
把自己最近總結的關鍵點記錄下來:

先解釋下吧(自己總結的):
Faster-RCNN是2015年提出的第一個真正意義上的端到端的深度學習檢測演算法,其最大的創新之處就在於通過新增RPN網路,基於Anchor機制來生成候選框,(代替selective search),最終將特徵提取、候選框選取、邊框迴歸和分類都整合到一個網路中,從而有效的提高檢測精度和檢測效率。具體的流程就是將輸入影象縮放以後進入到卷積層提取特徵得到feature map,然後特徵圖送入RPN網路生成一系列object可能的候選框,接下來將原始的feature maps和RPN輸出的所有候選框(ROI矩陣(N*5))輸入到ROI pooling層,提取收集proposal,並計算出固定大小7×7的proposal feature maps,送入全連線層進行目標分類與座標迴歸。
好像只要知道Faster-RCNN的,都知道其創新之處在於RPN網路,但是卻有很少真正懂ROI Pooling的,其實Faster-RCNN最關鍵的就是這兩部分,下面分別來說:
Region Proposal Networks(RPN):
RPN:RPN的核心思想就是使用”滑動視窗+anchor機制”來生成候選框。具體方法是在前面卷積層卷積得到的40*60的特徵圖(256)上,利用滑動視窗的方式(也就是3×3卷積核),在每個滑動視窗中心點構造9個不同長寬比不同尺度的候選框(40*60*9≈2萬個),並將其對映(對映比例16)到rescale影象中框出來,捨棄超出邊界的預proposal,再根據每個區域的softmax score進行從大到小排序,提取前2000個預proposal,對這個2000個進行NMS(非極大值抑制),最後將得到的再次進行排序,輸出300個proposal給faster RCNN進行預測。(注意此時rcnn的預測類別不包括背景,因為RPN輸出的已經預設是前景了)
RPN是一個卷積層(256維)+ relu(啟用函式) + 左右兩個層的(clc layer 和 reg layer)的小網路。RPN在feature map上用3×3的滑動視窗進行卷積,卷積步長stride=1,填充padding=2得到可以被9個anchor區域共享的256d特徵,輸給clc layer和reg layer後,也就是隻要一次前向,就同時預測k個區域的前景、背景概率(1個區域2個scores,所以得到2k個scores),以及bounding box(1個區域4個coordinates,所以是4k個coordinates),最終每一個bbox都有一個6維的向量,前2維用來判斷該框內是否有物體,後面4個維度用來判斷該bbox裡物體的座標。另外,在訓練RPN篩選候選框時,設定跟任意ground truth(GT) IOU的閾值為0.7,大於0.7的anchor標記為前景(正標籤),小於0.3的標定為背景(負樣本),然後在分類層,損失函式用softmax loss,RPN只對有標籤的區域計算loss,非正非負的區域不算損失,對訓練沒有作用。
而且,在訓練的過程中,FasterRCNN採用交替訓練的方式,用初始化的權值訓練RPN,再用RPN提取的候選區域訓練卷積網路,更新權值。
ROI-Pooling
ROI-Polling:Roi pooling其實就是將RPN得到的大約300個候選框對映到卷積特徵圖上並摳出來的過程,並且最重要的是經過ROI池化,不同大小的方框可以得到固定大小的特徵圖。具體的操作如下:1)根據輸入的image,將Roi對映到feature map對應的位置;2)將對映後的區域劃分為7×7大小的sections(sections數量和輸出的維度相同7×7); 3)對每個section(可以不一樣大)進行max pooling操作。這樣我們就可以從不同大小的方框得到固定大小的對應的maps。而且輸出的feature maps的大小不取決於ROI和卷積feature maps大小。ROI pooling最大的好處就在於極大地提高了訓練和測試速度(處理速度)。
下面進行補充:(概念性解釋)
❶說說GDA吧
隨機梯度下降演算法(GDA)成了訓練深度網路的主流方法。儘管隨機梯度下降法對於訓練深度網路簡單高效,但是它有個毛病,就是需要我們人為的去選擇引數,比如學習率、引數初始化、權重衰減係數、Drop out比例(丟棄)等。這些引數的選擇對訓練結果至關重要,以至於我們很多時間都浪費在這些的調參上。
❷什麼是BN層?有什麼用
BN(Batch Normalization)層的作用 Batch Normalization是由google提出的一種訓練優化方法,在網路的每一層輸入的時候,插入了一個歸一化層,歸一化處理以後再進入網路的下一層。這樣可以(1)加速收斂(2)控制過擬合,可以少用或不用Dropout和正則(3)降低網路對初始化權重不敏感(4)允許使用較大的學習率。Dropout是在訓練期間,將隱含層的一些神經元隨機丟棄,防止模型出現過擬合。
❸什麼是過擬合(over-fitting)和欠擬合(under-fitting)?以及解決方法?
所謂過擬合(over-fitting)其實就是在模型訓練時,所提取的特徵過於豐富,以至於模型在訓練集中表現得過於優越而在驗證資料集以及測試資料集中表現不佳。舉個例子:我要訓練一個識別狗的模型,而我的樣本中恰好都是泰迪,等樣本訓練完以後我那一張金毛的測試圖片,很可能結果就輸出不是一條狗,因為這個模型在訓練的時候基本上是按照泰迪的特徵來打造的,這就造成了模型的過擬合。欠擬合(under-fitting)則是提取泰迪的特徵比較少,導致訓練出來的模型不能很好地匹配,表現得很差,甚至泰迪都無法識別。(多增加一些特徵提取層或採用更復雜的網路)
方法:正則化(regulation)即在定義的損失函式後面加了一項永不為0的部分,這樣採用梯度下降演算法就不會使模型中的損失函式趨近0。另外增大訓練樣本規模同樣也可以防止過擬合。
❹pooling 、Roi pooling 和Roi align的區別:
General Pooling其實就是對卷積層得到的特徵圖進行降取樣,一方面縮小了特徵圖尺寸(也可以說降低卷積層輸出的特徵向量),起到了降維的作用,另一方面丟掉了一些特徵資訊一定程度上提高了模型的泛化能力,可以防止出現過擬合。一般有平均池化mean pooling和最大池化max pooling。ROI Pooling顧名思義,是Pooling層的一種,而且是針對RoIs的Pooling,他的特點是輸入特徵圖尺寸不固定,但是輸出特徵圖尺寸固定。
RoIPooling 採用的是INTER_NEAREST(即最近鄰插值),即在resize時,對於 縮放後坐標不能剛好為整數 的情況,採用了 粗暴的四捨五入,相當於選取離目標點最近的點。RoIAlign把最近鄰插值換成了雙線性插值,即從原圖到特徵圖的ROI對映直接使用雙線性插值,不取整,這樣誤差會小很多,經過池化後再對應回原圖的準確性也更高些,可以保證影象的空間對稱性(Alignment)。
❺mAP咋計算的?
平均精度(AP)、平均精度均值(mAP)、精確率(precision)、召回率(recall)、交併比IOU、置信度閾值(confidence thresholds)
那到底啥是準確率 – precision 和召回率 – recall:
若一個待檢測的物體為狗,我們將被正確識別的狗,即檢測為狗實際也為狗,稱為True positives。將被正確識別的貓,即檢測為貓實際也為貓,稱為True negatives。被錯誤識別為狗的貓稱為 False positives,被錯誤識別為貓的狗稱為 False negatives。

準確率可以反映一個類別的預測正確率 。
recall 的計算為:

準確率和召回率是互相影響的,因為如果想要提高準確率就會把預測的置信率閾值調高,所有置信率較高的預測才會被顯示出來,而那一些正確正預測(True Positive)可能因為置信率比較低而沒有被顯示了。一般情況下準確率高、召回率就低,召回率低、準確率高,如果兩者都低,就是網路出問題了。一般情況,用不同的閥值,統計出一組不同閥值下的精確率和召回率,如下圖:
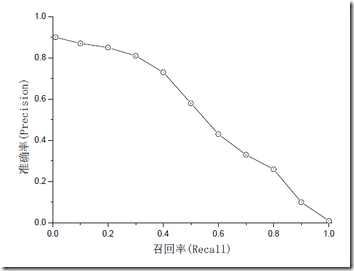
Precision其實就是在識別出來的圖片中,True positives所佔的比率。也就是所有被識別出來的狗中,真正的狗所佔的比例。Recall 是測試集中所有正樣本樣例中,被正確識別為正樣本的比例。也就是被正確識別出來的飛機個數與測試集中所有真實飛機的個數的比值。Precision-recall 曲線:改變識別閾值,使得系統依次能夠識別前K張圖片,閾值的變化同時會導致Precision與Recall值發生變化,從而得到曲線。曲線下的面積就是AP,mAP是多個類別AP的平均值。
具體的呢:
首先設定一組閾值,[0, 0.1, 0.2, …, 1]。然後對於recall大於每一個閾值(比如recall>0.3),我們都會得到一個對應的最大precision。這樣,我們就計算出了11個precision。AP即為這11個precision的平均值。這種方法英文叫做11-point interpolated average precision。
當然PASCAL VOC CHALLENGE自2010年後就換了另一種計算方法。新的計算方法假設這N個樣本中有M個正例,那麼我們會得到M個recall值(1/M, 2/M, ..., M/M),對於每個recall值r,我們可以計算出對應(r' > r)的最大precision,然後對這M個precision值取平均即得到最後的AP值。
好啦~
加油,各位,
自己也加油!