
目標檢測學習總結之RCNN、SPP-net、Fast RCNN、Faster RCNN、YOLO、SSD的區別
在計算機視覺領域,“目標檢測”主要解決兩個問題:影象上多個目標物在哪裡(位置),是什麼(類別)。
圍繞這個問題,人們一般把其發展歷程分為3個階段:
1. 傳統的目標檢測方法
2. 以R-CNN為代表的結合region proposal和CNN分類的目標檢測框架(R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN, R-FCN)
3. 以YOLO為代表的將目標檢測轉換為迴歸問題的端到端(End-to-End)的目標檢測框架(YOLO, SSD)
一、傳統的目標檢測方法
傳統目標檢測的方法一般分為三個階段:首先在給定的影象上選擇一些候選的區域,然後對這些區域提取特徵,最後使用訓練的分類器進行分類。分別如下:
a)區域選擇
b)特徵提取:提取候選區域相關的視覺特徵。比如人臉檢測常用的Harr特徵;行人檢測和普通目標檢測常用的HOG特徵等。由於目標的形態多樣性,光照變化多樣性,背景多樣性等因素使得設計一個魯棒的特徵並不是那麼容易,然而提取特徵的好壞直接影響到分類的準確性。
c)分類器:利用分類器進行識別,比如常用的SVM模型。傳統的目標檢測中,多尺度形變部件模型DPM(Deformable Part Model)表現比較優秀,連續獲得VOC(Visual Object Class)2007到2009的檢測冠軍。DPM把物體看成了多個組成的部件(比如人臉的鼻子、嘴巴等),用部件間的關係來描述物體,這個特性非常符合自然界很多物體的非剛體特徵。DPM可以看做是HOG+SVM的擴充套件,很好的繼承了兩者的優點,在人臉檢測、行人檢測等任務上取得了不錯的效果,但是DPM相對複雜,檢測速度也較慢,從而也出現了很多改進的方法。
總結:傳統目標檢測存在的兩個主要問題:
- 基於滑動視窗的區域選擇策略沒有針對性,時間複雜度高,視窗冗餘。
- 手工設計的特徵對於多樣性的變化並沒有很好的魯棒性。
二、兩階段檢測
1. RCNN
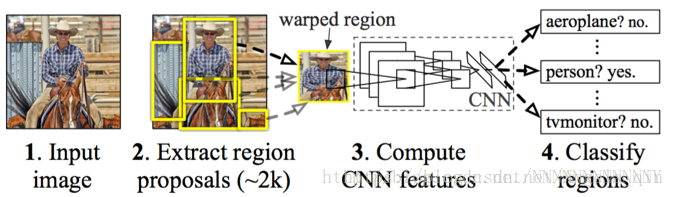
R-CNN的目標檢測流程:
a)輸入影象,用selective search(選擇性搜尋)演算法在影象中提取2000個左右的region proposal(侯選框),並把所有region proposal warp(縮放)成固定大小(原文采用227×227) 。
補充:selective search
選擇性搜尋綜合了蠻力搜尋(exhaustive search)和分割(segmentation)的方法。選擇性搜尋意在找出可能的目標位置來進行物體的識別。
我們首先用[13]得到一些初始化的區域R={r1,….rn}
計算出每個相鄰區域的相似性s(ri,rj)
1.找出相似性最大的區域max(S)={ri,rj}
2.合併rt=ri∪rj
3.從S集合中,移走所有與ri,rj相關的資料
4.計算新集合rt與所有與它相鄰區域的相似性s(rt,r*)
5.R=R∪rt
直到S集合為空,重複1~5。
Selective Search方法從一種圖片生成約2000個候選區域,採用一種過分割的手段,將影象分割成小區域,然後bottom-up,合併可能性最高的兩個區域,重複合併,直到整張影象上合併成一個區域為止。輸出所有曾經存在過的區域,就是候選區域。
相似度計算:考慮了顏色(顏色直方圖,畫素值統計)、紋理(梯度統計)、尺寸和空間交疊(交疊越大越相似)這4個引數
b) 將歸一化後的region proposal輸入CNN網路,提取特徵
c) 對於每個region proposal提取到的CNN特徵,再用SVM分類來做識別,用線性迴歸來微調邊框位置與大小,其中每個類別單獨訓練一個邊框迴歸(bounding-box regression)器。
總結:R-CNN框架仍存在如下問題:
a) 重複計算:我們通過regionproposal提取2000個左右的候選框,這些候選框都需要進行CNN操作,計算量依然很大,其中有不少其實是重複計算
b) multi-stage pipeline,訓練分為多個階段,步驟繁瑣:region proposal、CNN特徵提取、SVM分類、邊框迴歸,
c) 訓練耗時,佔用磁碟空間大:卷積出來的特徵資料還需要單獨儲存
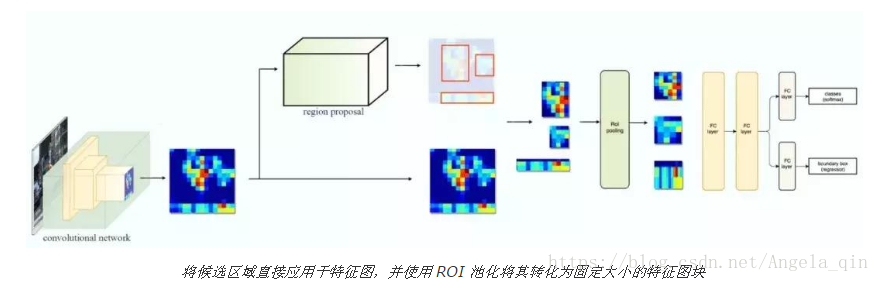
R-CNN 利用候選區域方法建立了約 2000 個 ROI。這些區域被轉換為固定大小的影象,並分別饋送到卷積神經網路中(將原始影象根據ROI切割、reshape再送進NN學習)。該網路架構後面會跟幾個全連線層,以實現目標分類並提煉邊界框。

使用候選區域、CNN、仿射層來定位目標。以下是 R-CNN 整個系統的流程圖:

通過使用更少且更高質量的 ROI,R-CNN 要比滑動視窗方法更快速、更準確。
ROIs = region_proposal(image)
for ROI in ROIs:
patch = get_patch(image, ROI)
results = detector(pach)
2. SPP-net
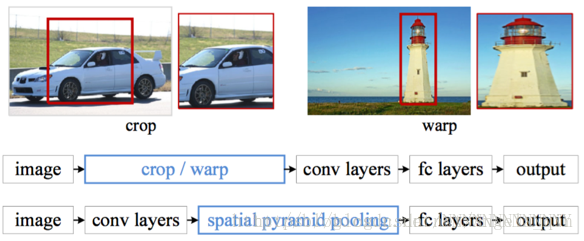
SPP-net的主要思想是去掉了原始影象上的crop/warp等操作,換成了在卷積特徵上的空間金字塔池化層(Spatial Pyramid Pooling,SPP)。
為何要引入SPP層?一部分原因是fast R-CNN裡對影象進行不同程度的crop/warp會導致一些問題,比如上圖中的crop會導致物體不全,warp導致物體被拉伸後形變嚴重。但更更更重要的原因是:fast R-CNN裡我們對每一個region proposal都要進行一次CNN提取特徵操作,這樣帶來了很多重複計算。試想假如我們只對整幅影象做一次CNN特徵提取,那麼原圖一個regionproposal可以對應到featuremap(特徵圖)一個window區域,只需要將這些不同大小window的特徵對映到同樣的維度,將其作為全連線的輸入,就能保證只對影象提取一次卷積層特徵。

SPP就是為了解決這種問題的。SPP使用空間金字塔取樣(spatial pyramid pooling)將每個window劃分為4*4, 2*2, 1*1的塊,然後每個塊使用max-pooling下采樣,這樣對於每個window經過SPP層之後都得到了一個長度為(4*4+2*2+1)*256維度的特徵向量,將這個作為全連線層的輸入進行後續操作。
總結:使用SPP-NET大大加快了目標檢測的速度,但是依然存在著很多問題:
a) 訓練分為多個階段,依然步驟繁瑣
b) SPP-NET在微調網路時固定了卷積層,只對全連線層進行微調,而對於一個新的任務,有必要對卷積層也進行微調。(分類的模型提取的特徵更注重高層語義,而目標檢測任務除了語義資訊還需要目標的位置資訊)(這一點其實不是很懂啊)
3. Fast-RCNN
Fast-RCNN在RCNN的基礎上又做了一些改進:
- 與SPP類似,它只對整幅影象做一次CNN特徵提取,在後面加了一個類似於SPP的ROI pooling layer,其實就是下采樣。不過因為不是固定尺寸輸入,因此每次的pooling網格大小需要動態調整,從而實現區域歸一化。
- 用softmax替代SVM分類,同時利用Multi-task Loss(多工損失函式)將邊框迴歸和分類一起進行。
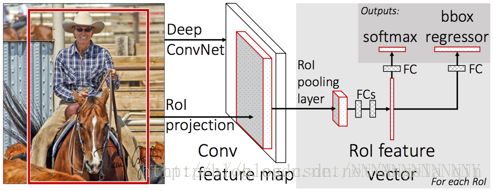
這裡再說一下Fast-RCNN的主要步驟:
a) 特徵提取:以整張圖片為輸入利用CNN得到圖片的特徵層;
b) region proposal:通過Selective Search等方法從原始圖片提取區域候選框,並把這些候選框一一投影到最後的特徵層;
c) 區域歸一化:針對特徵層上的每個區域候選框進行RoI Pooling操作,得到固定大小的特徵表示; ROI pooling可以 speed up both train and test time
d) 分類與迴歸:然後再通過兩個全連線層,分別用softmax做多目標分類,用迴歸模型進行邊框位置與大小微調。
總結:Fast-RCNN確實做得很棒,其缺點在於:region proposal的提取使用selective search,目標檢測時間大多消耗在這上面(提region proposal 2~3s,而提特徵分類只需0.32s),無法滿足實時應用。
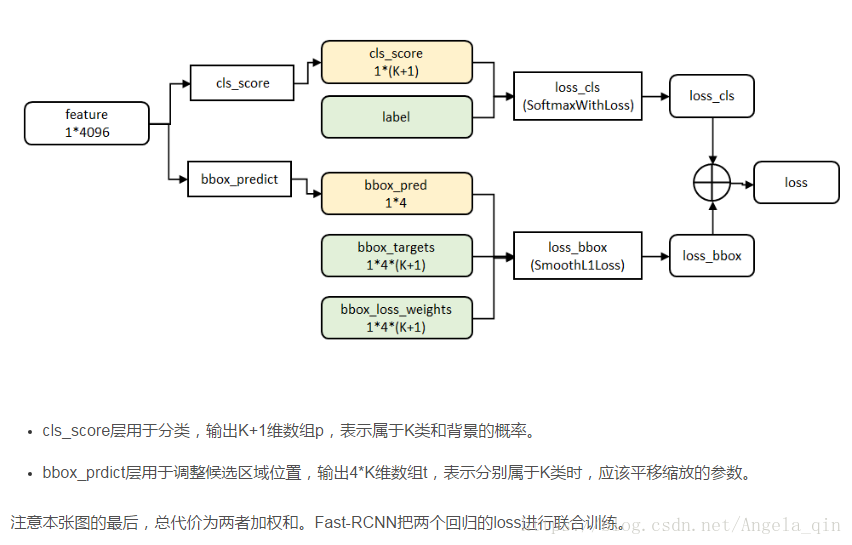
- K+1:分別屬於K類和背景的概率
- 4*(K+1): 分別屬於K類和背景時,應該平移縮放的引數
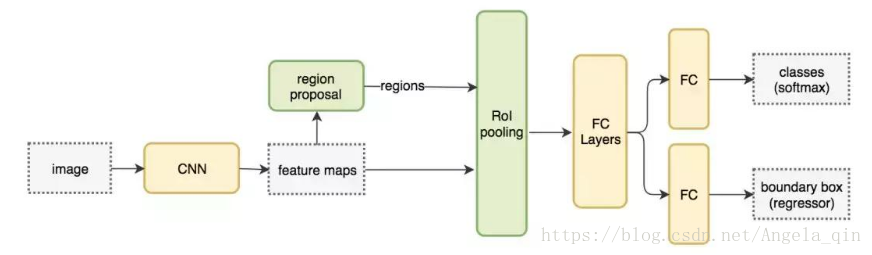
Fast-RCNN 使用特徵提取器(CNN)先提取整個影象的特徵,而不是從頭開始對每個影象塊提取多次。然後,我們可以將建立候選區域的方法直接應用到提取到的特徵圖上。例如,Fast-RCNN 選擇了 VGG16 中的卷積層 conv5 輸出的 Feture Map 來生成 ROI,這些關注區域隨後會結合對應的特徵圖以裁剪為特徵圖塊,並用於目標檢測任務中。我們使用 ROI 池化將特徵圖塊轉換為固定的大小,並饋送到全連線層進行分類和定位。因為 Fast-RCNN 不會重複提取特徵,因此它能顯著地減少處理時間。
以下是 Fast-RCNN 的流程圖:
在下面的虛擬碼中,計算量巨大的特徵提取過程從 For 迴圈中移出來了,因此速度得到顯著提升。Fast-RCNN 的訓練速度是 RCNN 的 10 倍,推斷速度是後者的 150 倍。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs:
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
4. Faster-RCNN:(RPN + Fast-RCNN)
Faster-RCNN用RPN獲得的proposal替代Fast-RCNN中selective search獲取的proposal(使用卷積神經網路直接產生region proposal)。
RPN網路的作用是輸入一張影象,輸出一批矩形候選區域,類似於以往目標檢測中的Selective Search一步。網路結構是基於卷積神經網路,但輸出包含二類softmax和bbox迴歸的多工模型。
以ZF網路為例:
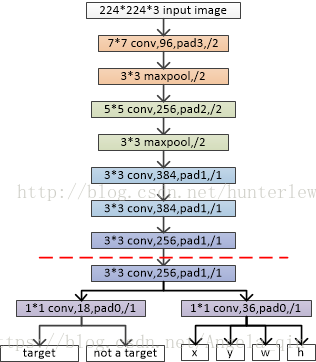
其中,虛線以上是ZF網路最後一層卷積層前的結構,虛線以下是RPN網路特有的結構。首先是3*3的卷積,然後通過1*1卷積輸出分為兩路,其中一路輸出是目標和非目標的概率,另一路輸出box相關的四個引數,包括box的中心座標x和y,box寬w和長h。
從卷積運算本身而言,卷積相當於滑窗。假如輸入影象是1000*600,則經過了幾次stride後,map大小縮小了16倍,最後一層卷積層輸出大約為60*40大小。因此,在對60*40的map進行滑窗時,以中心畫素為基點構造9種anchor對映到原來的1000*600影象中,對映比例為16倍。那麼總共可以得到60*40*9大約2萬個anchor。
假如某anchor與任一目標區域的IoU>0.7,則判定為有目標。
RPN網路得到的大約2萬個anchor不是都直接給Fast-RCNN,因為有很多重疊的框。文章通過非極大值抑制的方法,設定IoU為0.7的閾值,即僅保留覆蓋率不超過0.7的區域性最大分數的box(粗篩)。最後留下大約2000個anchor,然後再取前N個box(比如300個)給Fast-RCNN。Fast-RCNN將輸出300個判定類別及其box,對類別分數採用閾值為0.3的非極大值抑制(精篩),並僅取分數大於某個分數的目標結果(比如,只取分數60分以上的結果)。
視窗分類和位置精修
1)分類層(cls_score)輸出每一個位置上,9個anchor屬於前景和背景的概率。
2)視窗迴歸層(bbox_pred)輸出每一個位置上,9個anchor對應視窗應該平移縮放的引數(x,y,w,h)。
對於每一個位置來說,分類層從256維特徵中輸出屬於前景和背景的概率;視窗迴歸層從256維特徵中輸出4個平移縮放參數。

在圖5中,要注意,3*3卷積核的中心點對應原圖(re-scale,原始碼設定re-scale為600*1000)上的位置(點),將該點作為anchor的中心點,在原圖中框出多尺度、多種長寬比的anchors。所以,anchor不在conv特徵圖上,而在原圖上。對於一個大小為H*W的特徵層,它上面每一個畫素點對應9個anchor, 這裡有一個重要的引數feat_stride = 16, 它表示特徵層上移動一個點,對應原圖移動16個畫素點(看一看網路中的stride就明白16的來歷了)。把這9個anchor的座標進行平移操作,獲得在原圖上的座標。之後根據ground truth label和這些anchor之間的關係生成rpn_labels

VGG16中,13個卷積層的最後一層和RPN提取的區域都輸入到RCNN中進行檢測。

Faster R-CNN的主要步驟如下:
a) 特徵提取:同Fast R-CNN;b) region proposal:在最終的卷積特徵層上利用k個不同的矩形框(Anchor Box)進行region proposal;即對每個Anchor Box對應的區域進行object/non-object二分類,並用k個迴歸模型(各自對應不同的Anchor Box)微調候選框位置與大小 。
feature map上生成region proposal(通過RPN),每張圖片大約300個建議視窗。
c) 區域歸一化:同fast R-CNN;RoI pooling層 。
d) 分類與迴歸:進行目標分類,並做邊框迴歸(感覺這一塊再做一次邊框迴歸是不是有點重複)。 利用SoftMax Loss和Smooth L1 Loss對分類概率和邊框迴歸(Bounding Box Regression)聯合訓練。
Faster R-CNN的訓練:為了讓RPN的網路和Fast R-CNN網路實現卷積層的權值共享,其訓練方法比較複雜,簡而言之就是迭代的Alternating training。
feature_maps = process(image)
ROIs = region_proposal(feature_maps) # Expensive!
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
Faster R-CNN 採用與 Fast R-CNN 相同的設計,只是它用內部深層網路代替了候選區域方法。新的候選區域網路(RPN)在生成 ROI 時效率更高,並且以每幅影象10 毫秒的速度執行。
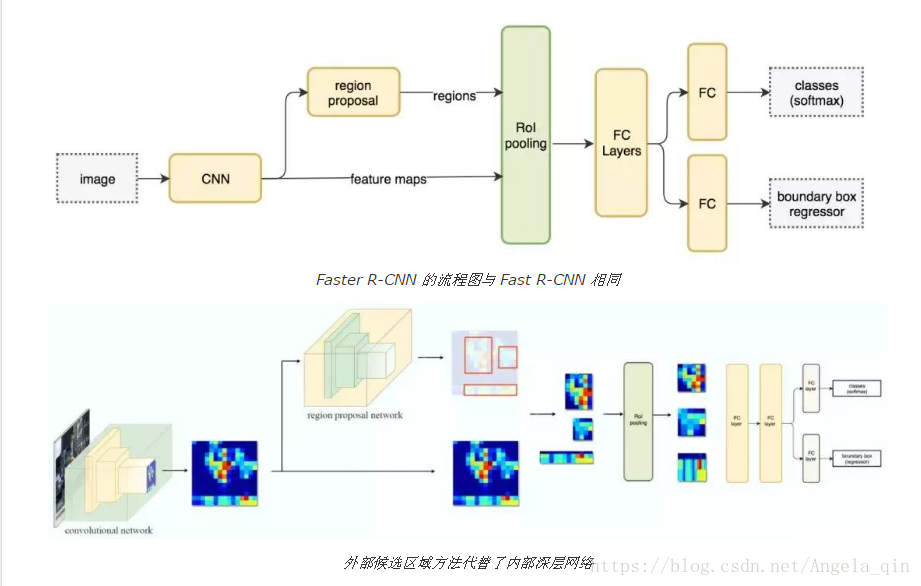

三、單階段檢測(直接通過特徵圖檢測)

1. YOLO
1)YOLOv1
徹底端到端(End-to-End)的目標檢測方法,不需要中間的region proposal在找目標,直接回歸便完成了位置和類別的判定。
如果兩個小目標同時落入一個格子中,模型也只能預測一個。大物體IOU誤差和小物體IOU誤差對網路訓練中loss貢獻值接近,因此,對於小物體,小的IOU誤差也會對網路優化過程造成很大的影響,從而降低了物體檢測的定位準確性。YOLO採用了多個下采樣層,網路學到的物體特徵並不精細,因此也會影響檢測效果。
與Faster-RCNN相比,YOLOv1有更加明顯的優勢,首先fFaster-RCNN需要一個rpn網路代替selective search來找出候選區域,而YOLOv1則直接將7x7這49個區域作為候選區域。

(1) 給個一個輸入影象,首先將影象劃分成7 * 7的網格。
(2) 對於每個網格,每個網格預測2個bounding box(每個box包含5個預測量)以及20個類別概率,總共輸出7×7×(2*5+20)=1470個tensor
(3) 根據上一步可以預測出7 * 7 * 2 = 98個目標視窗,然後根據閾值去除可能性比較低的目標視窗,再由NMS去除冗餘視窗即可。
YOLOv1使用了end-to-end的迴歸方法,沒有region proposal步驟,直接回歸便完成了位置和類別的判定。種種原因使得YOLOv1在目標定位上不那麼精準,直接導致YOLO的檢測精度並不是很高。
YOLOv1是單階段方法的開山之作。它將檢測任務表述成一個統一的、端到端的迴歸問題,並且以只處理一次圖片同時得到位置和分類而得名。
YOLOv1的主要優點:
- 快。
- 全域性處理使得背景錯誤相對少,相比基於區域性(區域)的方法, 如Fast-RCNN。
- 泛化效能好,在藝術作品上做檢測時,YOLOv1表現比Fast-RCNN好。

YOLOv1的工作流程如下:
1.準備資料:將圖片縮放,劃分為等分的網格,每個網格按跟GroundTruth的IoU分配到所要預測的樣本。
2.卷積網路:由GoogLeNet更改而來,每個網格對每個類別預測一個條件概率值,並在網格基礎上生成B個box,每個box預測五個迴歸值,四個表徵位置,第五個表徵這個box含有物體(注意不是某一類物體)的概率和位置的準確程度(由IoU表示)。測試時,分數如下計算:

等式左邊第一項由網格預測,後兩項由每個box預測,以條件概率的方式得到每個box含有不同類別物體的分數。因而,卷積網路共輸出的預測值個數為S×S×(B×5+C),其中S為網格數,B為每個網格生成box個數,C為類別數。
3.後處理:使用NMS(Non-MaximumSuppression,非極大抑制)過濾得到最後的預測框
損失函式的設計
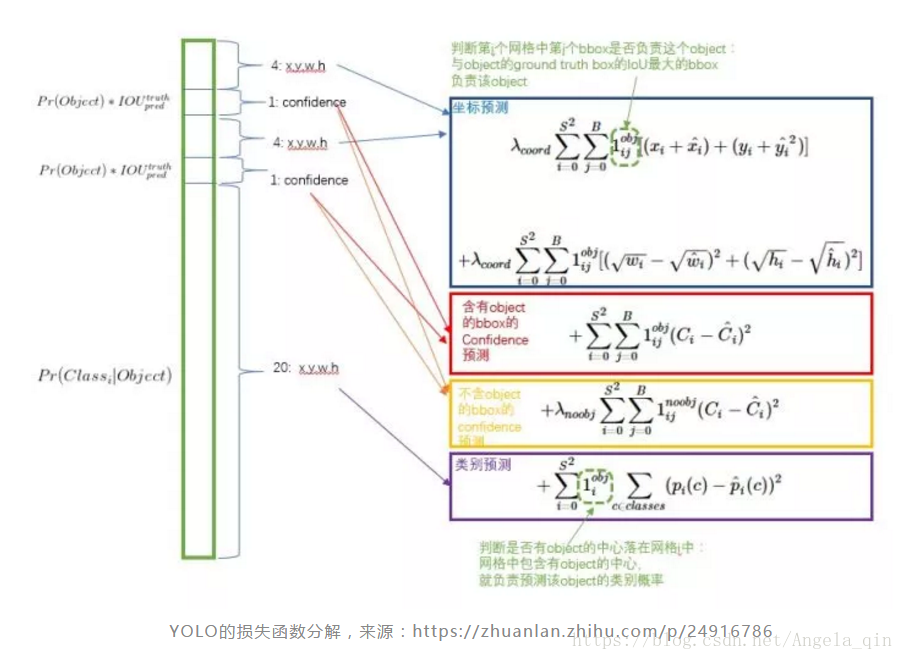
損失函式被分為三部分:座標誤差、物體誤差、類別誤差。為了平衡類別不均衡和大小物體等帶來的影響,損失函式中添加了權重並將長寬取根號。
小結
YOLOv1提出了單階段的新思路,相比兩階段方法,其速度優勢明顯,實時的特性令人印象深刻。但YOLOv1本身也存在一些問題,如劃分網格較為粗糙,每個網格生成的box個數等限制了對小尺度物體和相近物體的檢測。
2)YOLOv2
YOLOv2與YOLOv1的區別
1)將dropout層去掉,在每個卷積層添加了bach-normalization,mAP提高了2%。
2)高解析度分類器,輸入為高解析度資料由224*224變為448*448,mAP提高了4%。
3)刪除一個pooling層,得到高解析度資料,在卷積層之後使用anchor代替全連線層,把輸入448*448轉為416*416,這樣得到的feature map為奇數,feature map會有一箇中心單元,物體落在中心位置的可能是比較大的,這樣可以使用一箇中心單元代替四個來預測物體。
4)anchorbox是使用K-mean聚類來確定,聚類的距離計算使用來代替歐式距離。
5)不像YOLOv1使用grid來預測每個grid屬於哪種類別的概率Pr(Classi|Object),YOLOv2預測物體類別選用anchorbox的來預測。
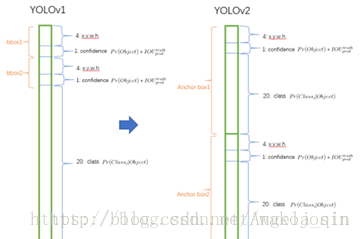
6) 預測box座標是延續YOLOv1預測boundingboxes相對柵格左上角的座標, 為了確保bounding boxes的中心落在柵格中(即座標落在0到1之間),boundingbox中心送入到啟用函式中來。

對於每個邊框預測5個座標值,tx、ty、tw、th、to。若單元相對影象左上角的偏移為(cx,cy),並且視窗的先驗寬高為pw、ph。
7)新增一個passthrough層提高對小物體的檢測,此層將高解析度的feature和低解析度的feature進行資訊融合,通過堆疊不同通道中相鄰的特徵而非空間位置實現融合高低解析度的特徵,使得26×26×512的特徵圖轉換為與原始特徵相連線的13×13×2048的特徵圖,mAP值提高了1%。
8)YOLOv2網路只用到了卷積層和池化層,因此可以進行動態調整輸入影象的尺寸。根據自己的要求調節精度和速度。
2. SSD
YOLO預測某個位置使用的是全圖的特徵,SSD預測某個位置使用的是這個位置周圍的特徵。使用Faster R-CNN的anchor機制。
不同於Faster R-CNN,這個anchor是在多個feature map上,這樣可以利用多層的特徵並且自然的達到多尺度(不同層的feature map 3*3滑窗感受野不同)。
個人感覺SSD模型與Faster RCNN中的RPN很類似。SSD中的dafault bounding box類似於RPN中的anchor,但是,SSD在不同的特徵層中考慮不同的尺度,RPN在一個特徵層考慮不同的尺度。
提出了 SSD 物體檢測模型,與現在流行的檢測模型一樣,將檢測過程整個成一個 single deep neural network。便於訓練與優化,同時提高檢測速度。SSD 將輸出一系列 離散化(discretization) 的 bounding boxes,這些 bounding boxes 是在 不同層次(layers) 上的 feature maps 上生成的,並且有著不同的 aspect ratio。
在 prediction 階段:
- 要計算出每一個 default box 中的物體,其屬於每個類別的可能性,即 score,得分。如對於 資料集,總共有 20 類,那麼得出每一個 bounding box 中物體屬於這 20 個類別的每一種的可能性。
- 同時,要對這些 bounding boxes 的 shape 進行微調,以使得其符合物體的 外接矩形。
- 還有就是,為了處理相同物體的不同尺寸的情況,SSD 結合了不同解析度的 feature maps 的 predictions。
剛開始的層使用影象分類模型中的層,稱為base network,在此基礎上,新增一些輔助結構:
1) Mult-scale feature map fordetection
在base network後,新增一些卷積層,這些層的大小逐漸減小,可以進行多尺度預測
2) Convolutional predictorsfor detection
每一個新新增的層,可以使用一系列的卷積核進行預測。對於一個大小為m*n、p通道的特徵層,使用3*3的卷積核進行預測,在某個位置上預測出一個值,該值可以是某一類別的得分,也可以是相對於default bounding boxes的偏移量,並且在影象的每個位置都將產生一個值。
3) Default boxes and aspectratio
在特徵圖的每個位置預測K個box。對於每個box,預測C個類別得分,以及相對於default bounding box的4個偏移值,這樣需要(C+4)*k個預測器,在m*n的特徵圖上將產生(C+4)*k*m*n個預測值。這裡,default bounding box類似於FasterRCNN中anchors。
在訓練時,本文的 SSD 與那些用 region proposals + pooling 方法的區別是,SSD 訓練影象中的groundtruth 需要賦予到那些固定輸出的 boxes 上。在前面也已經提到了,SSD 輸出的是事先定義好的,一系列固定大小的 bounding boxes。
如下圖中,狗狗的 groundtruth 是紅色的 bounding boxes,但進行 label 標註的時候,要將紅色的 groundtruth box 賦予 圖(c)中一系列固定輸出的boxes 中的一個,即 圖(c)中的紅色虛線框。

當這種將訓練影象中的groundtruth 與固定輸出的 boxes 對應之後,就可以 end-to-end 的進行 lossfunction 的計算以及back-propagation 的計算更新了。
SSD相比YOLO有以下突出的特點:
- 多尺度的feature map:基於VGG的不同卷積段,輸出feature map到迴歸器中。這一點試圖提升小物體的檢測精度。
- 更多的anchor box,每個網格點生成不同大小和長寬比例的box,並將類別預測概率基於box預測(YOLO是在網格上),得到的輸出值個數為(C+4)×k×m×n,其中C為類別數,k為box個數,m×n為feature map的大小。
SSD是單階段模型早期的集大成者,達到跟接近兩階段模型精度的同時,擁有比兩階段模型快一個數量級的速度。後續的單階段模型工作大多基於SSD改進展開。
總結
兩階段(2-stage)檢測模型
兩階段模型因其對圖片的兩階段處理得名,也稱為基於區域(Region-based)的方法,我們選取RCNN系列工作作為這一型別的代表。
單階段(1-stage)檢測模型
單階段模型沒有中間的區域檢出過程,直接從圖片獲得預測結果,也被成為Region-free方法。
相關資源
目標檢測學習總結:
SSD: