
Kaggle —— 泰坦尼克號Titanic
1. 資料總覽
Titanic 生存模型預測,其中包含了兩組資料:train.csv 和 test.csv,分別為訓練集合和測試集合。
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
觀察前幾行的源資料:
train_data = pd.read_csv('data/train.csv' - 1
- 2
- 3
- 4
- 5
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
資料資訊總覽:
train_data.info()
print("-" * 40)
test_data.info()- 1
- 2
- 3
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
----------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
從上面我們可以看出,Age、Cabin、Embarked、Fare幾個特徵存在缺失值。
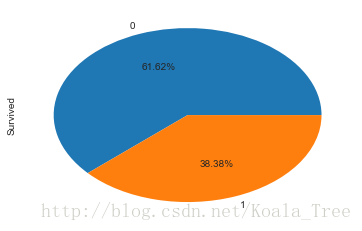
繪製存活的比例:
train_data['Survived'].value_counts().plot.pie(autopct = '%1.2f%%')- 1
<matplotlib.axes._subplots.AxesSubplot at 0x230c2508ef0>
- 1
- 2
2. 缺失值處理的方法
對資料進行分析的時候要注意其中是否有缺失值。
一些機器學習演算法能夠處理缺失值,比如神經網路,一些則不能。對於缺失值,一般有以下幾種處理方法:
(1)如果資料集很多,但有很少的缺失值,可以刪掉帶缺失值的行;
(2)如果該屬性相對學習來說不是很重要,可以對缺失值賦均值或者眾數。比如在哪兒上船Embarked這一屬性(共有三個上船地點),缺失倆值,可以用眾數賦值
train_data.Embarked[train_data.Embarked.isnull()] = train_data.Embarked.dropna().mode().values- 1
(3)對於標稱屬性,可以賦一個代表缺失的值,比如‘U0’。因為缺失本身也可能代表著一些隱含資訊。比如船艙號Cabin這一屬性,缺失可能代表並沒有船艙。
#replace missing value with U0
train_data['Cabin'] = train_data.Cabin.fillna('U0') # train_data.Cabin[train_data.Cabin.isnull()]='U0'- 1
- 2
(4)使用迴歸 隨機森林等模型來預測缺失屬性的值。因為Age在該資料集裡是一個相當重要的特徵(先對Age進行分析即可得知),所以保證一定的缺失值填充準確率是非常重要的,對結果也會產生較大影響。一般情況下,會使用資料完整的條目作為模型的訓練集,以此來預測缺失值。對於當前的這個資料,可以使用隨機森林來預測也可以使用線性迴歸預測。這裡使用隨機森林預測模型,選取資料集中的數值屬性作為特徵(因為sklearn的模型只能處理數值屬性,所以這裡先僅選取數值特徵,但在實際的應用中需要將非數值特徵轉換為數值特徵)
from sklearn.ensemble import RandomForestRegressor
#choose training data to predict age
age_df = train_data[['Age','Survived','Fare', 'Parch', 'SibSp', 'Pclass']]
age_df_notnull = age_df.loc[(train_data['Age'].notnull())]
age_df_isnull = age_df.loc[(train_data['Age'].isnull())]
X = age_df_notnull.values[:,1:]
Y = age_df_notnull.values[:,0]
# use RandomForestRegression to train data
RFR = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
RFR.fit(X,Y)
predictAges = RFR.predict(age_df_isnull.values[:,1:])
train_data.loc[train_data['Age'].isnull(), ['Age']]= predictAges- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
讓我們再來看一下缺失資料處理後的DataFram:
train_data.info()- 1
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 891 non-null object
Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3. 分析資料關係
(1) 性別與是否生存的關係 Sex
train_data.groupby(['Sex','Survived'])['Survived'].count()- 1
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()- 1
<matplotlib.axes._subplots.AxesSubplot at 0x230c251ab00>
- 1
- 2
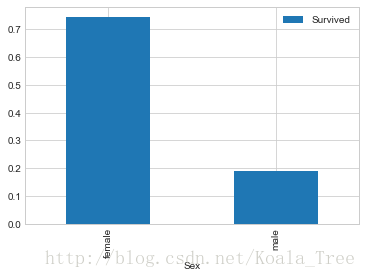
以上為不同性別的生存率,可見在泰坦尼克號事故中,還是體現了Lady First。
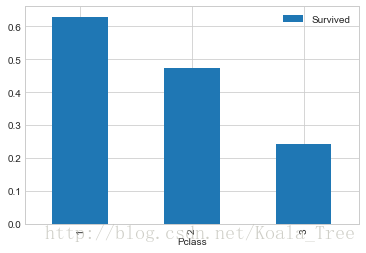
(2) 船艙等級和生存與否的關係 Pclass
train_data.groupby(['Pclass','Survived'])['Pclass'].count()- 1
Pclass Survived
1 0 80
1 136
2 0 97
1 87
3 0 372
1 119
Name: Pclass, dtype: int64
train_data[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()- 1
<matplotlib.axes._subplots.AxesSubplot at 0x230c5e08b70>
- 1
- 2
train_data[['Sex','Pclass','Survived']].groupby(['Pclass','Sex']).mean().plot.bar()- 1
<matplotlib.axes._subplots.AxesSubplot at 0x230c5e2ad68>
- 1
- 2
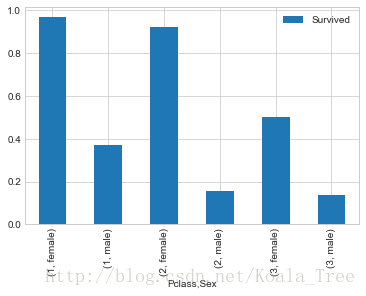
不同等級船艙的男女生存率:
train_data.groupby(['Sex', 'Pclass', 'Survived'])['Survived'].count()- 1
Sex Pclass Survived
female 1 0 3
1 91
2 0 6
1 70
3 0 72
1 72
male 1 0 77
1 45
2 0 91
1 17
3 0 300
1 47
Name: Survived, dtype: int64
從圖和表中可以看出,總體上泰坦尼克號逃生是婦女優先,但是對於不同等級的船艙還是有一定的區別。
(3) 年齡與存活與否的關係 Age
分別分析不同等級船艙和不同性別下的年齡分佈和生存的關係:
fig, ax = plt.subplots(1, 2, figsize = (18, 8))
sns.violinplot("Pclass", "Age", hue="Survived", data=train_data, split=True, ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0, 110, 10))
sns.violinplot("Sex", "Age", hue="Survived", data=train_data, split=True, ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0, 110, 10))
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
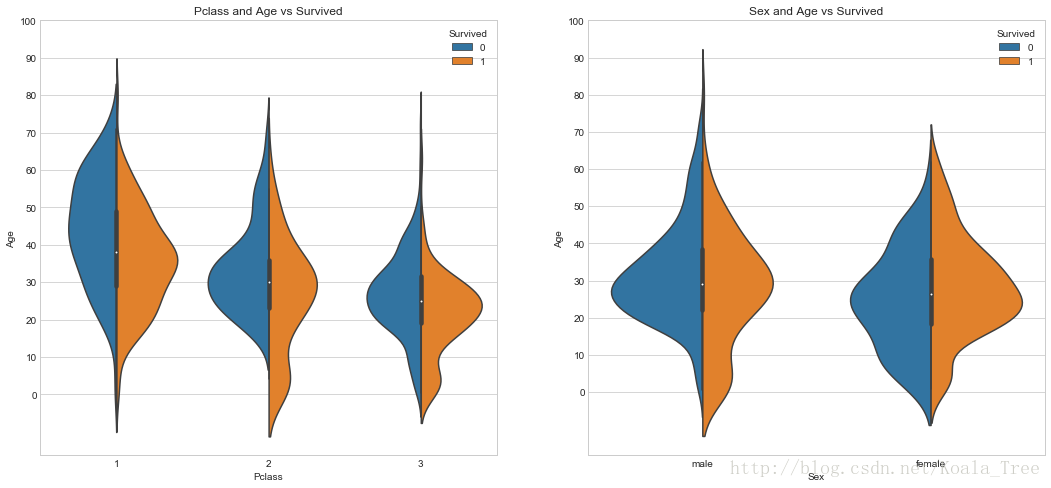
分析總體的年齡分佈:
plt.figure(figsize=(12,5))
plt.subplot(121)
train_data['Age'].hist(bins=70)
plt.xlabel('Age')
plt.ylabel('Num')
plt.subplot(122)
train_data.boxplot(column='Age', showfliers=False)
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
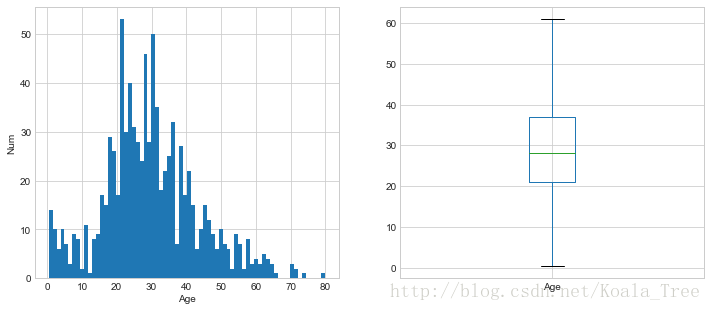
不同年齡下的生存和非生存的分佈情況:
facet = sns.FacetGrid(train_data, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, train_data['Age'].max()))
facet.add_legend()- 1
- 2
- 3
- 4
<seaborn.axisgrid.FacetGrid at 0x230c5e53cf8>
- 1
- 2
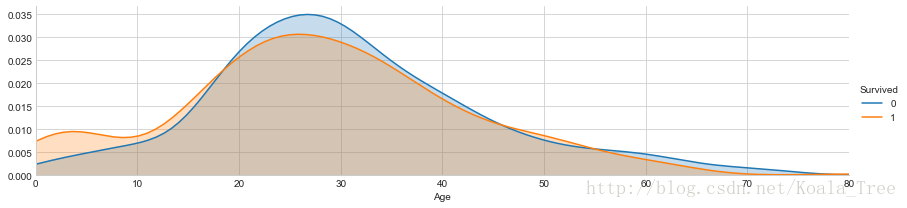
不同年齡下的平均生存率:
# average survived passengers by age
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
train_data["Age_int"] = train_data["Age"].astype(int)
average_age = train_data[["Age_int", "Survived"]].groupby(['Age_int'],as_index=False).mean()
sns.barplot(x='Age_int', y='Survived', data=average_age)- 1
- 2
- 3
- 4
- 5
<matplotlib.axes._subplots.AxesSubplot at 0x230c60135f8>
- 1
- 2
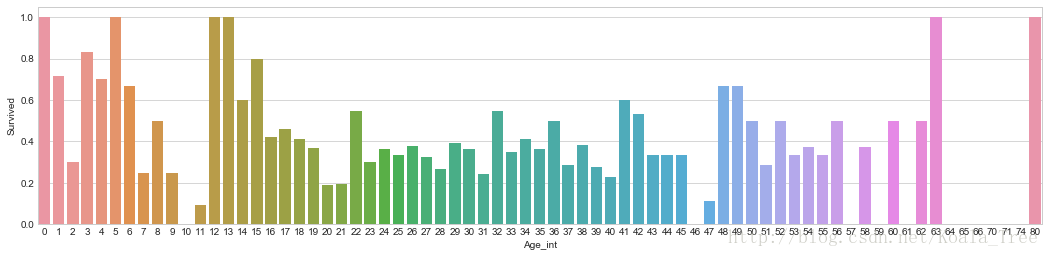
train_data['Age'].describe()- 1
count 891.000000
mean 29.668231
std 13.739002
min 0.420000
25% 21.000000
50% 28.000000
75% 37.000000
max 80.000000
Name: Age, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
樣本有891,平均年齡約為30歲,標準差13.5歲,最小年齡為0.42,最大年齡80.
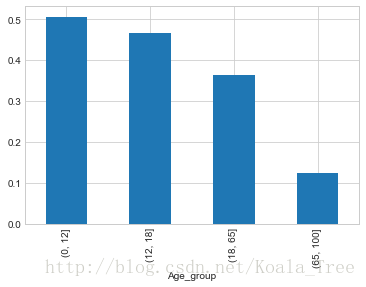
按照年齡,將乘客劃分為兒童、少年、成年和老年,分析四個群體的生還情況:
bins = [0, 12, 18, 65, 100]
train_data['Age_group'] = pd.cut(train_data['Age'], bins)
by_age = train_data.groupby('Age_group')['Survived'].mean()
by_age- 1
- 2
- 3
- 4
Age_group
(0, 12] 0.506173
(12, 18] 0.466667
(18, 65] 0.364512
(65, 100] 0.125000
Name: Survived, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
by_age.plot(kind = 'bar')- 1
<matplotlib.axes._subplots.AxesSubplot at 0x230c6079e80>
- 1
- 2
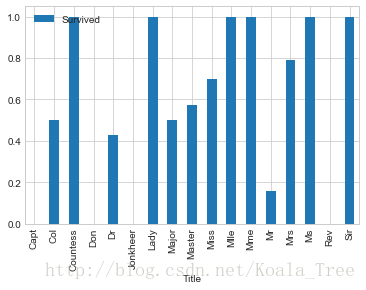
(4) 稱呼與存活與否的關係 Name
通過觀察名字資料,我們可以看出其中包括對乘客的稱呼,如:Mr、Miss、Mrs等,稱呼資訊包含了乘客的年齡、性別,同時也包含了如社會地位等的稱呼,如:Dr,、Lady、Major、Master等的稱呼。
train_data['Title'] = train_data['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_data['Title'], train_data['Sex'])- 1
- 2
- 3
| Sex | female | male |
|---|---|---|
| Title | ||
| Capt | 0 | 1 |
| Col | 0 | 2 |
| Countess | 1 | 0 |
| Don | 0 | 1 |
| Dr | 1 | 6 |
| Jonkheer | 0 | 1 |
| Lady | 1 | 0 |
| Major | 0 | 2 |
| Master | 0 | 40 |
| Miss | 182 | 0 |
| Mlle | 2 | 0 |
| Mme | 1 | 0 |
| Mr | 0 | 517 |
| Mrs | 125 | 0 |
| Ms | 1 | 0 |
| Rev | 0 | 6 |
| Sir | 0 | 1 |
觀察不同稱呼與生存率的關係:
train_data[['Title','Survived']].groupby(['Title']).mean().plot.bar()- 1
<matplotlib.axes._subplots.AxesSubplot at 0x230c61699b0>
- 1
- 2
同時,對於名字,我們還可以觀察名字長度和生存率之間存在關係的可能:
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
train_data['Name_length'] = train_data['Name'].apply(len)
name_length = train_data[['Name_length','Survived']].groupby(['Name_length'],as_index=False).mean()
sns.barplot(x='Name_length', y='Survived', data=name_length)- 1
- 2
- 3
- 4
<matplotlib.axes._subplots.AxesSubplot at 0x230c61689b0>
- 1
- 2
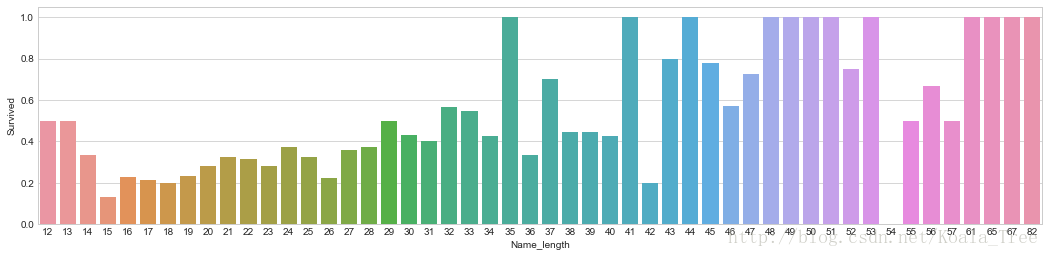
從上面的圖片可以看出,名字長度和生存與否確實也存在一定的相關性。
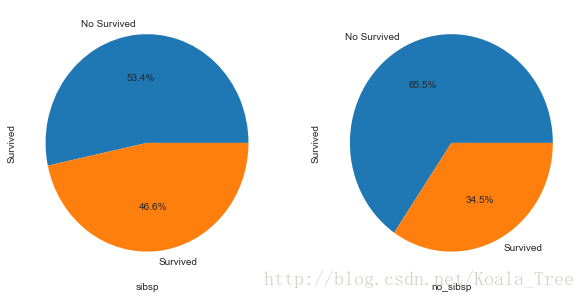
(5) 有無兄弟姐妹和存活與否的關係 SibSp
# 將資料分為有兄弟姐妹的和沒有兄弟姐妹的兩組:
sibsp_df = train_data[train_data['SibSp'] != 0]
no_sibsp_df = train_data[train_data['SibSp'] == 0]- 1
- 2
- 3
plt.figure(figsize=(10,5))
plt.subplot(121)
sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%')
plt.xlabel('sibsp')
plt.subplot(122)
no_sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%')
plt.xlabel('no_sibsp')
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
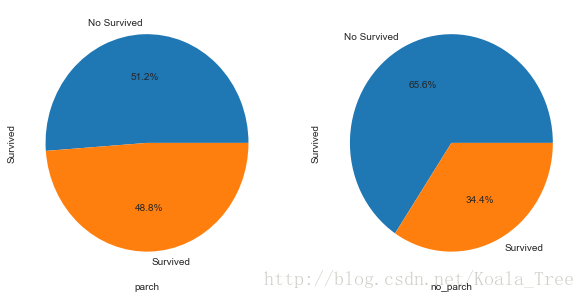
(6) 有無父母子女和存活與否的關係 Parch
和有無兄弟姐妹一樣,同樣分析可以得到:
parch_df = train_data[train_data['Parch'] != 0]
no_parch_df = train_data[train_data['Parch'] == 0]
plt.figure(figsize=(10,5))
plt.subplot(121)
parch_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%')
plt.xlabel('parch')
plt.subplot(122)
no_parch_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%')
plt.xlabel('no_parch')
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
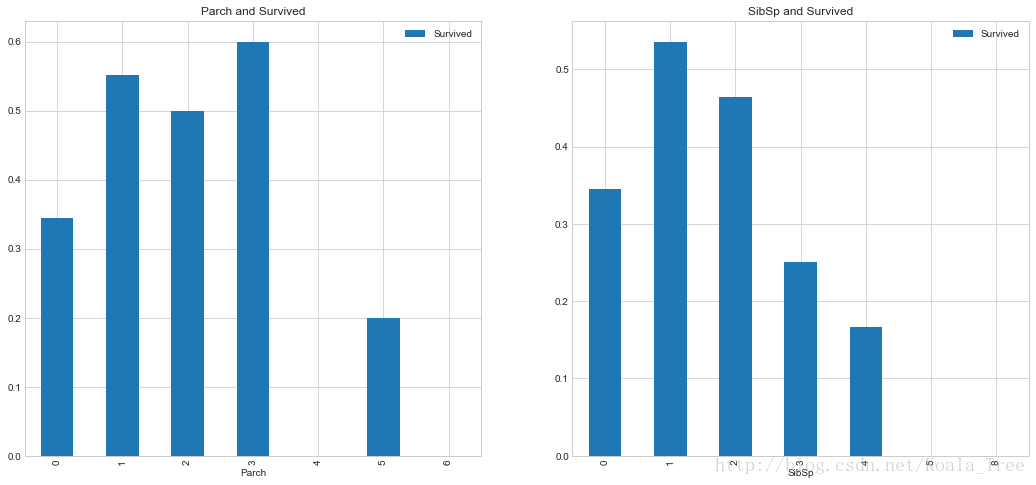
fig,ax=plt.subplots(1,2,figsize=(18,8))
train_data[['Parch','Survived']].groupby(['Parch']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Parch and Survived')
train_data[['SibSp','Survived']].groupby(['SibSp']).mean().plot.bar(ax=ax[1])
ax[1].set_title('SibSp and Survived')- 1
- 2
- 3
- 4
- 5
Text(0.5,1,'SibSp and Survived')
- 1
- 2
train_data['Family_Size'] = train_data['Parch'] + train_data['SibSp'] + 1
train_data[['Family_Size','Survived']].groupby(['Family_Size']).mean().plot.bar()- 1
- 2
<matplotlib.axes._subplots.AxesSubplot at 0x230c77155c0>
- 1
- 2
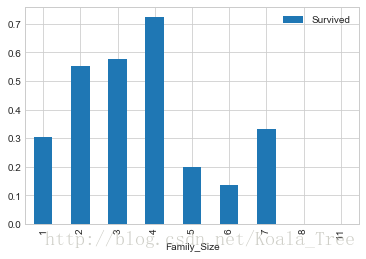
從圖表中可以看出,若獨自一人,那麼其存活率比較低;但是如果親友太多的話,存活率也會很低。
(8) 票價分佈和存活與否的關係 Fare
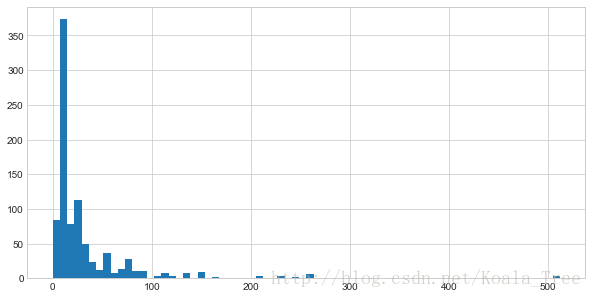
首先繪製票價的分佈情況:
plt.figure(figsize=(10,5))
train_data['Fare'].hist(bins = 70)
train_data.boxplot(column='Fare', by='Pclass', showfliers=False)
plt.show()- 1
- 2
- 3
- 4
- 5
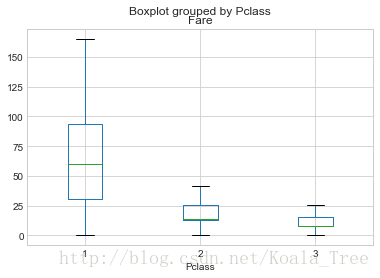
train_data['Fare'].describe()- 1
count 891.000000
mean 32.204208
std 49.693429
min 0.000000
25% 7.910400
50% 14.454200
75% 31.000000
max 512.329200
Name: Fare, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
繪製生存與否與票價均值和方差的關係:
fare_not_survived = train_data['Fare'][train_data['Survived'] == 0]
fare_survived = train_data['Fare'][train_data['Survived'] == 1]
average_fare = pd.DataFrame([fare_not_survived.mean(), fare_survived.mean()])
std_fare = pd.DataFrame([fare_not_survived.std(), fare_survived.std()])
average_fare.plot(yerr=std_fare, kind='bar', legend=False)
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
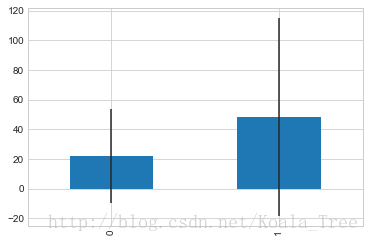
由上圖示可知,票價與是否生還有一定的相關性,生還者的平均票價要大於未生還者的平均票價。
(9) 船艙型別和存活與否的關係 Cabin
由於船艙的缺失值確實太多,有效值僅僅有204個,很難分析出不同的船艙和存活的關係,所以在做特徵工程的時候,可以直接將該組特徵丟棄。
當然,這裡我們也可以對其進行一下分析,對於缺失的資料都分為一類。
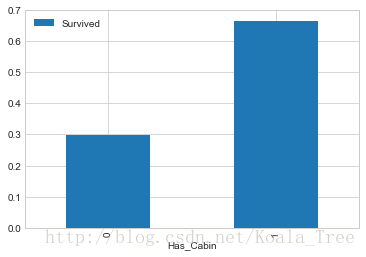
簡單地將資料分為是否有Cabin記錄作為特徵,與生存與否進行分析:
# Replace missing values with "U0"
train_data.loc[train_data.Cabin.isnull(), 'Cabin'] = 'U0'
train_data['Has_Cabin'] = train_data['Cabin'].apply(lambda x: 0 if x == 'U0' else 1)
train_data[['Has_Cabin','Survived']].groupby(['Has_Cabin']).mean().plot.bar()- 1
- 2
- 3
- 4
<matplotlib.axes._subplots.AxesSubplot at 0x230c7566080>
- 1
- 2
對不同型別的船艙進行分析:
# create feature for the alphabetical part of the cabin number
train_data['CabinLetter'] = train_data['Cabin'].map(lambda x: re.compile("([a-zA-Z]+)").search(x).group())
# convert the distinct cabin letters with incremental integer values
train_data['CabinLetter'] = pd.factorize(train_data['CabinLetter'])[0]
train_data[['CabinLetter','Survived']].groupby(['CabinLetter']).mean().plot.bar()- 1
- 2
- 3
- 4
- 5
<matplotlib.axes._subplots.AxesSubplot at 0x230c5ebcd30>
- 1
- 2
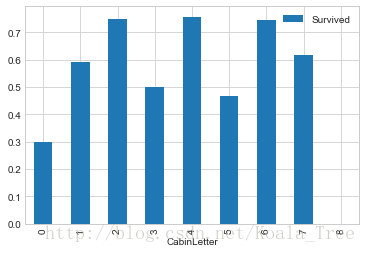
可見,不同的船艙生存率也有不同,但是差別不大。所以在處理中,我們可以直接將特徵刪除。
(10) 港口和存活與否的關係 Embarked
泰坦尼克號從英國的南安普頓港出發,途徑法國瑟堡和愛爾蘭昆士敦,那麼在昆士敦之前上船的人,有可能在瑟堡或昆士敦下船,這些人將不會遇到海難。
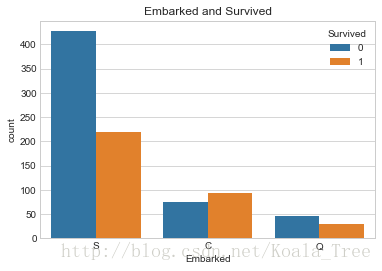
sns.countplot('Embarked', hue='Survived', data=train_data)
plt.title('Embarked and Survived')- 1
- 2
Text(0.5,1,'Embarked and Survived')
- 1
- 2
sns.factorplot('Embarked', 'Survived', data=train_data, size=3, aspect=2)
plt.title('Embarked and Survived rate')
plt.show()- 1
- 2
- 3
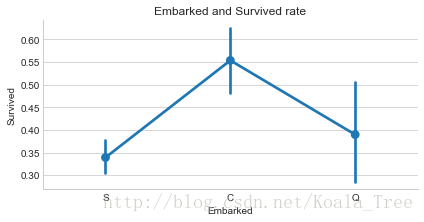
由上可以看出,在不同的港口上船,生還率不同,C最高,Q次之,S最低。
以上為所給出的資料特徵與生還與否的分析。
據瞭解,泰坦尼克號上共有2224名乘客。本訓練資料只給出了891名乘客的資訊,如果該資料集是從總共的2224人中隨機選出的,根據中心極限定理,該樣本的資料也足夠大,那麼我們的分析結果就具有代表性;但如果不是隨機選取,那麼我們的分析結果就可能不太靠譜了。
(11) 其他可能和存活與否有關係的特徵
對於資料集中沒有給出的特徵資訊,我們還可以聯想其他可能會對模型產生影響的特徵因素。如:乘客的國籍、乘客的身高、乘客的體重、乘客是否會游泳、乘客職業等等。
另外還有資料集中沒有分析的幾個特徵:Ticket(船票號)、Cabin(船艙號),這些因素的不同可能會影響乘客在船中的位置從而影響逃生的順序。但是船艙號資料缺失,船票號類別大,難以分析規律,所以在後期模型融合的時候,將這些因素交由模型來決定其重要性。
4. 變數轉換
變數轉換的目的是將資料轉換為適用於模型使用的資料,不同模型接受不同型別的資料,Scikit-learn要求資料都是數字型numeric,所以我們要將一些非數字型的原始資料轉換為數字型numeric。
所以下面對資料的轉換進行介紹,以在進行特徵工程的時候使用。
所有的資料可以分為兩類:
- 1.定性(Quantitative)變數可以以某種方式排序,Age就是一個很好的列子。
- 2.定量(Qualitative)變數描述了物體的某一(不能被數學表示的)方面,Embarked就是一個例子。
定性(Qualitative)轉換:
1. Dummy Variables
就是類別變數或者二元變數,當qualitative variable是一些頻繁出現的幾個獨立變數時,Dummy Variables比較適合使用。我們以Embarked為例,Embarked只包含三個值’S’,’C’,’Q’,我們可以使用下面的程式碼將其轉換為dummies:
embark_dummies = pd.get_dummies(train_data['Embarked'])
train_data = train_data.join(embark_dummies)
train_data.drop(['Embarked'], axis=1,inplace=True)- 1
- 2
- 3
embark_dummies = train_data[['S', 'C', 'Q']]
embark_dummies.head()- 1
- 2
| S | C | Q | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 |
2. Factorizing
dummy不好處理Cabin(船艙號)這種標稱屬性,因為他出現的變數比較多。所以Pandas有一個方法叫做factorize(),它可以建立一些數字,來表示類別變數,對每一個類別對映一個ID,這種對映最後只生成一個特徵,不像dummy那樣生成多個特徵。
# Replace missing values with "U0"
train_data['Cabin'][train_data.Cabin.isnull()] = 'U0'
# create feature for the alphabetical part of the cabin number
train_data['CabinLetter'] = train_data['Cabin'].map( lambda x : re.compile("([a-zA-Z]+)").search(x).group())
# convert the distinct cabin letters with incremental integer values
train_data['CabinLetter'] = pd.factorize(train_data['CabinLetter'])[0]- 1
- 2
- 3
- 4
- 5