
Kaggle入門——泰坦尼克號生還者預測
前言
這個是Kaggle比賽中泰坦尼克號生存率的分析。強烈建議在做這個比賽的時候,再看一遍電源《泰坦尼克號》,可能會給你一些啟發,比如婦女兒童先上船等。所以是否獲救其實並非隨機,而是基於一些背景有先後順序的。
1,背景介紹
1912年4月15日,載著1316號乘客和891名船員的豪華巨輪泰坦尼克號在首次航行期間撞上冰山後沉沒,2224名乘客和機組人員中有1502人遇難。沉船導致大量傷亡的原因之一是沒有足夠的救生艇給乘客和船員。雖然倖存下來有一些運氣因素,但有一些人比其他人更有可能生存,比如婦女,兒童和上層階級。在本文中將對哪些人可能生存作出分析,特別是運用Python和機器學習的相關模型工具來預測哪些乘客倖免於難,最後提交結果。
其中訓練和測試資料是一些乘客的個人資訊以及存活狀況,要嘗試根據它生成合適的模型並預測其他人的存活狀況。這是一個二分類的問題。
2,資料檔案說明
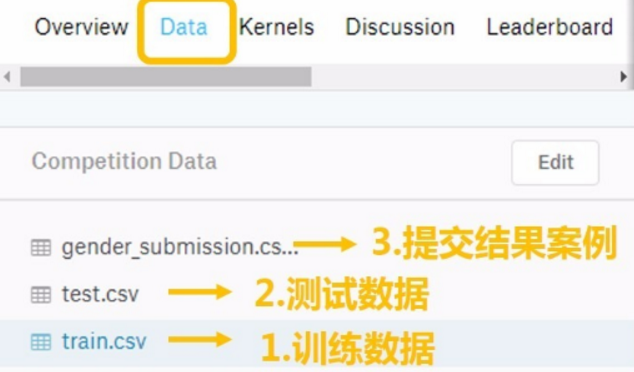
從Kaggle泰坦尼克號專案頁面下載資料:https://www.kaggle.com/c/titanic
下面是問題的背景頁:
下面是可下載Data的頁面
下面是forum頁面,我們會從中學到各種資料處理/建模想法:
3,資料變數說明
每個乘客有12個屬性,其中PassengerID在這裡只起到索引作用,而Survived是我們要預測的目標,因此我們要處理的資料總共有10個變數。

對於上述變數的說明:
- PassengerID(ID)
- Survived(存活與否)
- Pclass(客艙等級,在當時的英國階級分層比較嚴重,較為重要)
- Name(姓名,可提取出更多資訊)
- Sex(性別,較為重要)
- Age(年齡,較為重要)
- Parch(直系親友,是指父母,孩子,其中1表示有一個,依次類推)
- SibSp(旁系,是指兄弟姐妹)
- Ticket(票編號,這個是個玄學問題)
- Fare(票價,可能票價貴的獲救機率大)
- Cabin(客艙編號)
- Embarked(上船的港口編號,是指從不同的港口上船)
4,評估方法
將從基礎的方法開始學習,然後預測結果,最後將準確率最高的模型預測的結果提交到Kaggle上,檢視自己的結果如何。
5,完整程式碼,請移步小編的GitHub
傳送門:請點選我
如果點不開,複製這個地址:https://github.com/LeBron-Jian/Kaggle-learn
資料預處理
資料的質量決定模型能達到的上限、所以對資料的預處理無比重要。機器學習的演算法模型是用來挖掘資料中潛在模式的,但是若資料太過複雜,潛在的模式就很難找到,更糟糕的是,我們所收集的資料的特徵和我們想預測的標籤之間並沒有太大關聯,這時候這個特徵就像噪音一樣只會干擾我們的模型做出準確的預測。所以說,我們要對拿到手的資料集進行分析,並看看各個特徵到底會不會顯著影響到我們要預測的標籤值。
1,總體預覽
在Data下的我們的 train.csv 和 test.csv 兩個檔案分別存著官方給出的訓練和測試資料。
train.info()
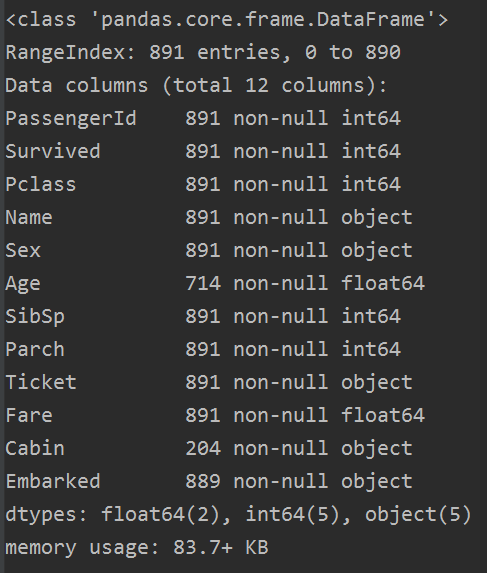
從資料中發現,總數為891個,那還有特徵是有空值的,Cabin甚至只有一點資料(不著急,這裡我們先看看)。而且有些資料是數值型的,一些是文字型的,還有一些是類目性的。這些我們用下面函式是看不到的。
res = all_data.describe()
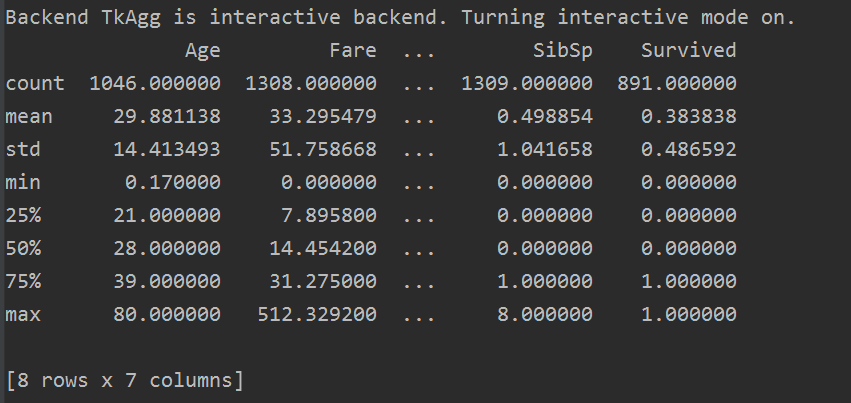
describe() 函式時檢視資料的描述統計資訊,只檢視數值型資料,字串型的資料,如姓名(name),客艙號(Cabin)等不可顯示。
而上面資訊告訴我們,大概有 0.383838的人最終獲救了,平均乘客年齡大概是29.88歲等等。。
2,資料初步分析
每個乘客都有這麼多屬性,那我們咋知道哪些屬性更有用,而又應該怎麼用他們呢?說實話這會我也不知道,但是我們要知道,對資料的認識是非常重要的!所以我們要深入的看我們的資料,後面就會寫到如何分析資料。
為什麼要這樣分析資料,我們可以先看看這個文章https://zhuanlan.zhihu.com/p/26663761。一個泰坦尼克號的生還者寫下的回憶錄,我這裡貼上幾個重要的:
注意:面對沉船災難,婦女和兒童先上救生艇,當然也有例外,不過很少。




這次分析分析以下幾個方面:
- 1,性別與倖存率的關係
- 2,乘客社會等級與倖存率的關係
- 3,攜帶配偶及兄弟姐妹與倖存率的關係
- 4,攜帶父母及子女與倖存率的關係
- 5,年齡與倖存率的關係
- 6,登港港口與倖存率的關係
- 7,稱呼(從姓名中提取乘客的稱呼)與倖存率的關係
- 8,家庭總人數與倖存率的關係
- 9,不同船艙的乘客與倖存率的關係
(這些分析參考部落格:https://www.jianshu.com/p/e79a8c41cb1a)
首先,我們看看得到的資料中,倖存的人與死亡人數的比重:
res = train['Survived'].value_counts()
print(res)
'''
0 549
1 342
Name: Survived, dtype: int64 '''
2.1 性別與生存率的關係
我們從上面知道,讓婦女兒童上船,那麼女性的倖存率到底如何呢?我們看圖:
sns.barplot(x='Sex', y='Survived', data=train)
圖如下:

我們可以看到,確實是女性倖存率遠高於男性,那麼性別Sex是一個很重要的特徵。
2.2 乘客等級與生存率的關係
sns.barplot(x='Pclass', y='Survived', data=train)
圖如下:
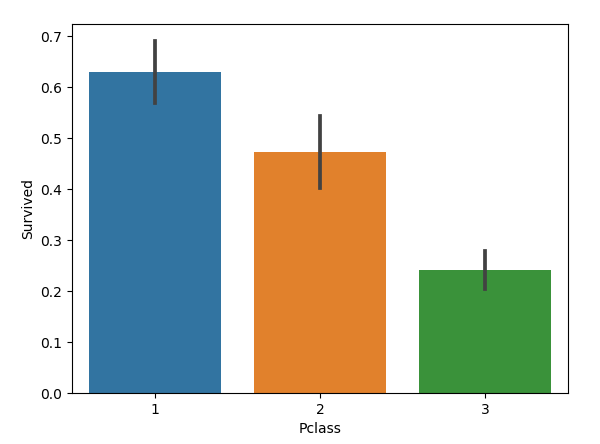
我們發現,乘客社會等級越高,倖存率越高,所以Pclass這個特徵也比較重要。
2.3 攜帶配偶及兄弟姐妹與生存率的關係
sns.barplot(x='SibSp', y='Survived', data=train)
圖如下:
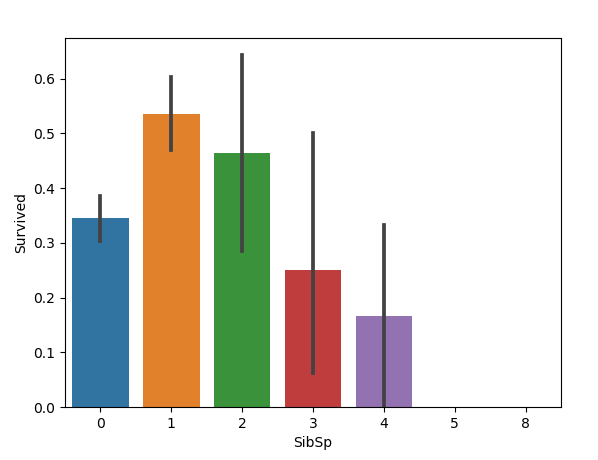
只能說:攜帶的配偶與兄弟姐妹適中的乘客倖存率更高,可能帶個配偶倖存率最高。
2.4 攜帶父母與子女與生存率的關係
sns.barplot(x='Parch', y='Survived', data=train)
圖如下:
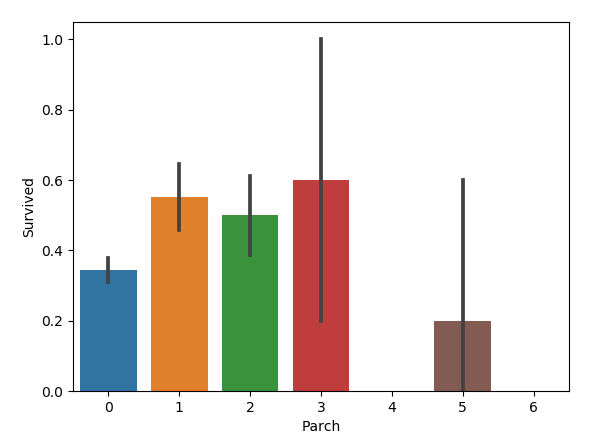
好像也是父母與子女適中的乘客倖存率更高。
2.5 年齡與倖存率的關係
facet = sns.FacetGrid(train, hue='Survived', aspect=2)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlabel('Age')
plt.ylabel('density')
圖如下:
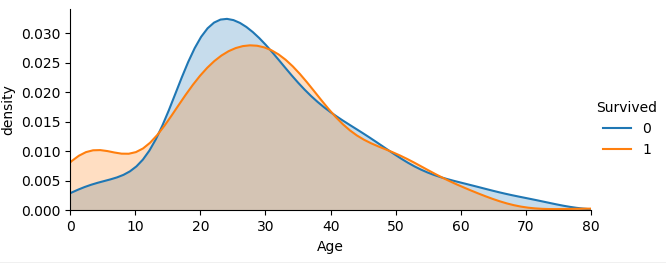
從不同生還情況的密度圖可以看出,在年齡15歲的左側,生還率有明顯差別,密度圖非交叉區域面積非常大,但在其他年齡段,則差別不是很明顯,認為是隨機所致,因此可以考慮將年齡偏小的區域分離出來。
2.6 登港港口與倖存率的關係
登船港口(Embarked):
- 出發地點:S = 英國南安普頓Southampton
- 途徑地點1:C = 法國 瑟堡市Cherbourg
- 途徑地點2:Q = 愛爾蘭 昆士敦Queenstown
我們先按照登港港口與倖存率的關係畫圖,程式碼如下:
sns.countplot('Embarked',hue='Survived',data=train)
圖如下:
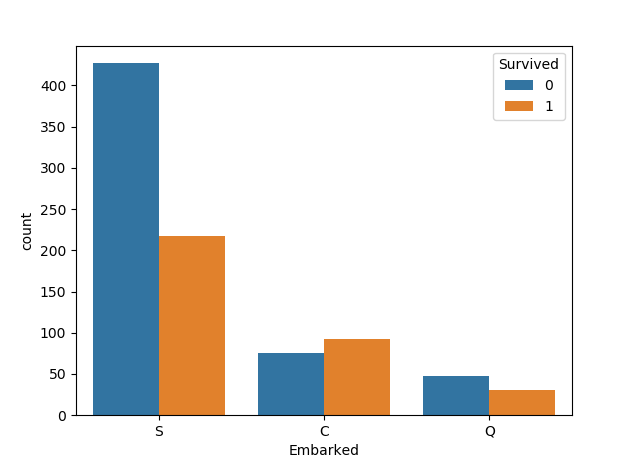
我們發現C地的生存率更高,這個應該儲存為模型特徵,最後我們再篩選嘛。
2.7 不同稱呼與倖存率的關係
每個人都有自己的名字,而且每個名字都是獨一無二的,名字和倖存與否看起來並沒有直接關聯,那怎麼利用這個特徵呢?有用的資訊就隱藏在稱呼當中,比如上面我們提到過女生優先,所以稱呼為Mrs和 Miss 的就比稱呼為Mr 的的更可能倖存,於是我們需要從Name中拿到其稱呼並建立新的特徵列Title。
我們注意在每一個name 中,有一個非常顯著的特點:乘客頭銜每個名字當中都包含了具體的稱謂或者說是頭銜,將這部分資訊提取出來後可以作為非常有用的一個新變數,可以幫助我們進行預測。
例如:
Braund, Mr. Owen Harris
Heikkinen, Miss. Laina
Oliva y Ocana, Dona. Fermina
Peter, Master. Michael J
定義函式,從名字中獲取頭銜。
all_data['Title'] = all_data.Name.apply(lambda name: name.split(',')[1].split('.')[0].strip())
如果上面程式碼看不懂,可以看下面這個:
# get all the titles and print how often each one occurs
titles = all_data['Name'].apply(get_title)
print(pd.value_counts(titles))
# A function to get the title from a name
def get_title(name):
# use a regular expression to search for a title
title_search = re.search('([A-Za-z]+)\.', name)
# if the title exists, extract and return it
if title_search:
return title_search.group(1)
return ''
我們可以看看稱呼的種類和數量:
all_data.Title.value_counts() out: Mr 757 Miss 260 Mrs 197 Master 61 Rev 8 Dr 8 Col 4 Mlle 2 Ms 2 Major 2 Capt 1 Lady 1 Jonkheer 1 Don 1 Dona 1 the Countess 1 Mme 1 Sir 1 Name: Title, dtype: int64
我們將定義以下幾種頭銜型別
- Officer政府官員
- Royalty王室(皇室)
- Mr已婚男士
- Mrs已婚婦女
- Miss年輕未婚女子
- Master有技能的人/教師
大類可以分為六個:Mr,Miss,Mrs,Master,Royalty,Officer,姓名中頭銜字串與定義頭銜型別的分類程式碼如下:
all_data = pd.concat([train, test], ignore_index=True)
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
all_data['Title'] = all_data['Title'].map(Title_Dict)
sns.barplot(x="Title", y="Survived", data=all_data)
上面的pandas不會使用,也可以使用下面程式碼:
# map each title to an integer some titles are very rare
# and are compressed into the same codes as other titles
title_mapping = {
'Mr': 1,
'Miss': 2,
'Mrs': 3,
'Master': 4,
'Rev': 5,
'Dr': 6,
'Col': 7,
'Mlle': 8,
'Ms': 9,
'Major': 10,
'Don': 11,
'Countess': 12,
'Mme': 13,
'Jonkheer ': 14,
'Sir': 15,
'Dona': 16,
'Capt': 17,
'Lady': 18,
}
for k, v in title_mapping.items():
titles[titles == k] = v
# print(k, v)
all_data['Title'] = titles
至於如何分類,就看自己的想法了,我這裡只是將所有的稱呼表示出來,你可以自己分。我按照上面的分類:
title_mapping = {
'Mr': 2,
'Miss': 3,
'Mrs': 4,
'Master': 1,
'Rev': 5,
'Dr': 5,
'Col': 5,
'Mlle': 3,
'Ms': 4,
'Major': 6,
'Don': 5,
'Countess': 5,
'Mme': 4,
'Jonkheer ': 1,
'Sir': 5,
'Dona': 5,
'Capt': 6,
'Lady': 5,
}
圖如下:

2.8 家庭總人數與倖存率的關係
我們新增FamilyLabel特徵,這個特徵等於父母兒童+配偶兄弟姐妹+1,在文中就是 FamilyLabel=Parch+SibSp+1,然後將FamilySize分為三類:
all_data['FamilySize']=all_data['SibSp']+all_data['Parch']+1 sns.barplot(x="FamilySize", y="Survived", data=all_data)
圖如下:
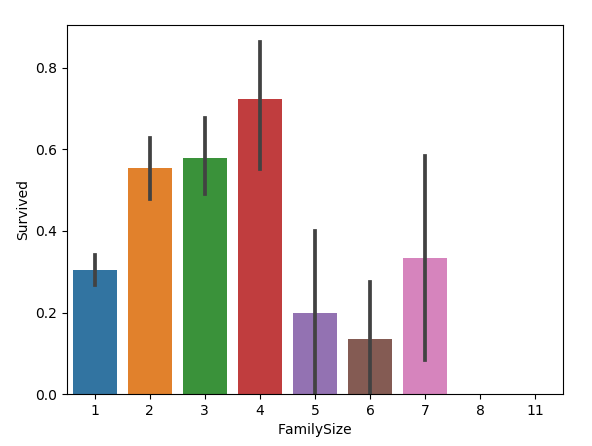
家庭類別:
- 小家庭Family_Single:家庭人數=1
- 中等家庭Family_Small: 2<=家庭人數<=4
- 大家庭Family_Large: 家庭人數>=5
我們按照生存率將FamilySize分為三類,構成FamilyLabel特徵:
def Fam_label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 7)) | (s == 1):
return 1
elif (s > 7):
return 0
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch'] + 1
all_data['FamilyLabel']=all_data['FamilySize'].apply(Fam_label)
sns.barplot(x="FamilyLabel", y="Survived", data=all_data)
結果圖如下:
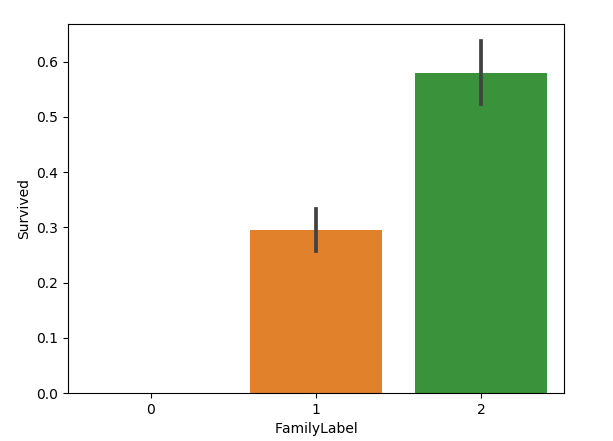
也可以提取名字長度的特徵:
# generating a familysize column 是指所有的家庭成員
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch']
# the .apply method generates a new series
all_data['NameLength'] = all_data['Name'].apply(lambda x: len(x))
最後我們選擇是否使用這些特徵。
2.9 不同船艙的乘客與倖存率的關係
船艙號(Cabin)裡面資料總數是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比較大。這注定是個棘手的問題。
當然船艙的資料並不是很多,但是乘客位於不同船艙,也就意味著身份不同,所以我們新增Deck特徵,先把Cabin空白的填充為“Unknown”,再提取Cabin中的首字母構成乘客的甲板號。
all_data['Cabin'] = all_data['Cabin'].fillna('Unknown')
all_data['Deck'] = all_data['Cabin'].str.get(0)
sns.barplot(x="Deck", y="Survived", data=all_data)
圖如下:
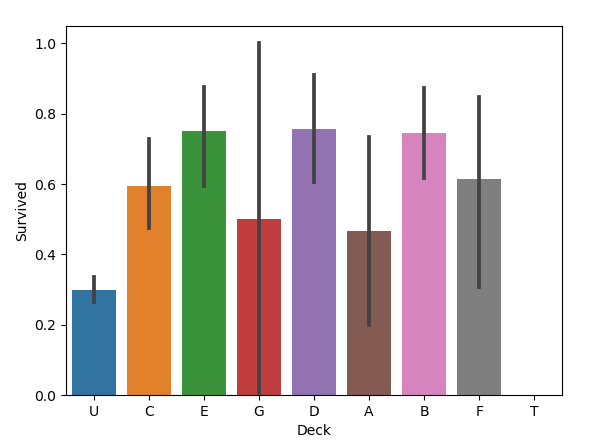
2.10 與二到四人共票號的乘客與倖存率的關係
新增了一個特徵叫做 TicketGroup特徵,這個特徵是統計每個乘客的共票號數。程式碼如下:
Ticket_Count = dict(all_data['Ticket'].value_counts())
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x: Ticket_Count[x])
sns.barplot(x='TicketGroup', y='Survived', data=all_data)
圖如下:
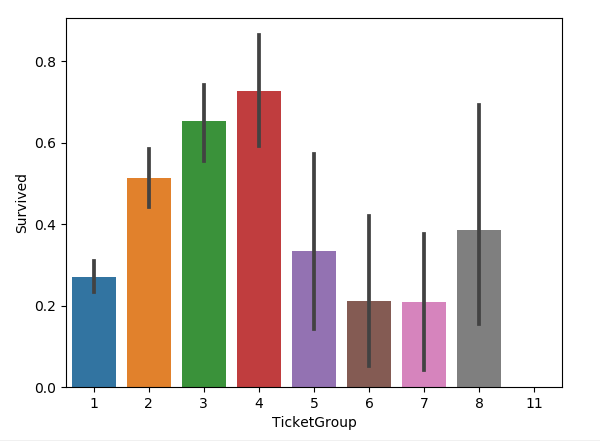
把生存率按照TicketGroup 分為三類:
Ticket_Count = dict(all_data['Ticket'].value_counts())
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x: Ticket_Count[x])
all_data['TicketGroup'] = all_data['TicketGroup'].apply(Ticket_Label)
sns.barplot(x='TicketGroup', y='Survived', data=all_data)
def Ticket_Label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 8)) | (s == 1):
return 1
elif (s > 8):
return 0
圖如下:
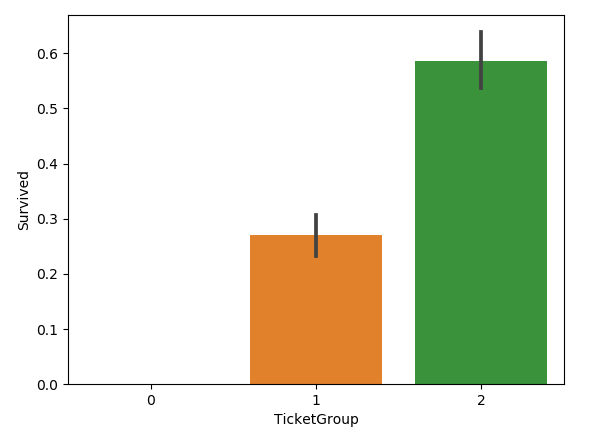
3,資料清洗
3.1 缺失值填充
上面我們從整體分析的時候,也發現了有著不少的缺失值,缺失量也有比較大的,所以我們如何填充缺失值,這是個問題。
很多機器學習演算法為了訓練模型,要求所傳入的特徵中不能有空值。一般做如下處理:
1,如果是數值型別,用平均值取代 .fillna(.mean())
2,如果是分類資料,用最常見的類別取代 .value_counts() + fillna.()
3,使用模型預測缺失值,例如KNN
具體可以參考我的部落格:
Python機器學習筆記:使用sklearn做特徵工程和資料探勘
我們首先看看那些變數都有缺失值:
下面這個是train的資料,總共資料有891個,那麼在訓練的資料集中 Age,Cabin, Embarked 有缺失值。
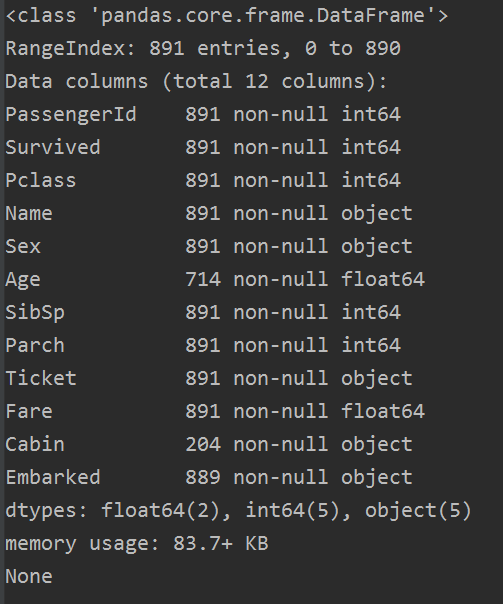
下面這個是test的資料,總共有418個數據,其中Age, Fare, Cabin 有缺失值。

這裡對Age的缺失值處理方法是採用平均值:
traindata['Age'] = traindata['Age'].fillna(traindata['Age'].median()) test['Age'] = test['Age'].fillna(test['Age'].median())
當然平均值可能有些不妥,我百度,也有說按照稱呼對Age的缺失值進行補全了,(上面我們不是對姓名做了處理:2.7 不同稱呼與倖存率之間的關係),因為Miss用於未婚女子,通常其年齡比較小,Mrs則表示太太,夫人,一般年齡較大,因此利用稱呼中隱含的資訊去推斷其年齡是比較合理的,下面可以根據title進行分組並對Age進行補全。
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
all_data = pd.concat([train, test], ignore_index=True)
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
all_data['Title'] = all_data['Title'].map(Title_Dict)
# sns.barplot(x="Title", y="Survived", data=all_data)
grouped = all_data.groupby(['Title'])
median = grouped.Age.median()
print(median)
Title
Master 4.5
Miss 22.0
Mr 29.0
Mrs 35.0
Officer 49.5
Royalty 40.0
Name: Age, dtype: float64
可以看到,不同稱呼的乘客其年齡的中位數有顯著差異,因此我們只需要按稱呼對缺失值進行補全即可,這裡使用中位數(平均數也是可以的,在這個問題當中兩者差異不大,而中位數看起來更整潔一些)。
程式碼如下:
all_data['Title'] = all_data['Title'].map(Title_Dict)
# sns.barplot(x="Title", y="Survived", data=all_data)
grouped = all_data.groupby(['Title'])
median = grouped.Age.median()
for i in range(len(all_data['Age'])):
if pd.isnull(all_data['Age'][i]):
all_data['Age'][i] = median[all_data['Title'][i]]
我們可以檢視一下 all_data.info()
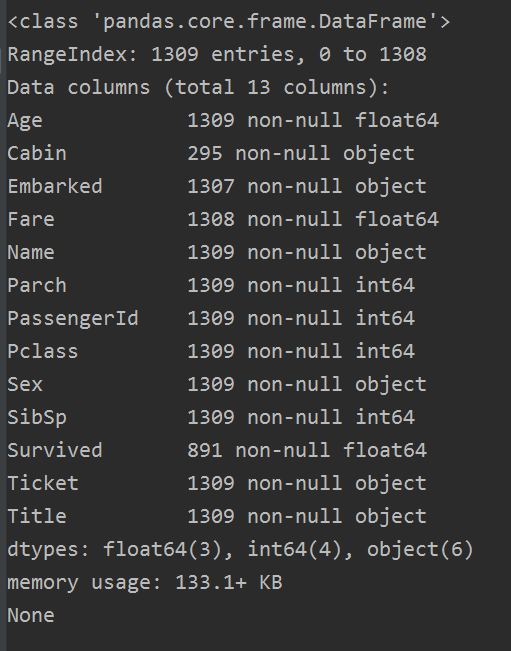
Age的缺失值已經補全了,下面我們對Cabin,Embarked 以及Fare進行補全。
而Embarked 缺失值只有兩個,對結果影響不大,所以我們這裡將缺失值補全為登船港口人數最多的港口(這裡其實應用的是先驗概率最大原則)。從結果來看(上面分析過),S地的登船人數最多,所以我們將缺失值填充為最頻繁出現的值,S=英國安南普頓Southampton。
all_data['Embarked'] = all_data['Embarked'].fillna('S')
上面我們也提到過Cabin缺失數值比較多,所以我們把船艙號(Cabin)的缺失值填充為U,表示未知(Unknown)。
# 缺失資料比較多,船艙號(Cabin)缺失值填充為U,表示未知(Uknow)
all_data['Cabin'] = all_data['Cabin'].fillna('U')
Fare只有一個缺失值,所以我們可以用票價Fare的平均值補全。
all_data['Fare'] = all_data['Fare'].fillna(all_data.Fare.median())
至此,我們的缺失值就補全了,check一下:
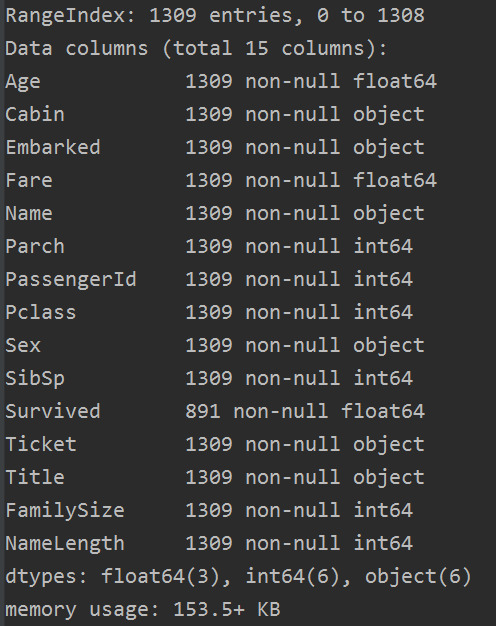
完整程式碼如下:
def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
# print(test.info())
all_data = pd.concat([train, test], ignore_index=True)
titles = all_data['Name'].apply(get_title)
# print(pd.value_counts(titles))
# map each title to an integer some titles are very rare
# and are compressed into the same codes as other titles
title_mapping = {
'Mr': 2,
'Miss': 3,
'Mrs': 4,
'Master': 1,
'Rev': 5,
'Dr': 5,
'Col': 5,
'Mlle': 3,
'Ms': 4,
'Major': 6,
'Don': 5,
'Countess': 5,
'Mme': 4,
'Jonkheer': 1,
'Sir': 5,
'Dona': 5,
'Capt': 6,
'Lady': 5,
}
for k, v in title_mapping.items():
titles[titles == k] = v
# print(k, v)
all_data['Title'] = titles
grouped = all_data.groupby(['Title'])
median = grouped.Age.median()
for i in range(len(all_data['Age'])):
if pd.isnull(all_data['Age'][i]):
all_data['Age'][i] = median[all_data['Title'][i]]
# print(all_data['Age'])
# generating a familysize column 是指所有的家庭成員
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch']
# the .apply method generates a new series
all_data['NameLength'] = all_data['Name'].apply(lambda x: len(x))
# print(all_data['NameLength'])
all_data['Embarked'] = all_data['Embarked'].fillna('S')
# 缺失資料比較多,船艙號(Cabin)缺失值填充為U,表示未知(Uknow)
all_data['Cabin'] = all_data['Cabin'].fillna('U')
all_data['Fare'] = all_data['Fare'].fillna(all_data.Fare.median())
all_data.loc[all_data['Embarked'] == 'S', 'Embarked'] = 0
all_data.loc[all_data['Embarked'] == 'C', 'Embarked'] = 1
all_data.loc[all_data['Embarked'] == 'Q', 'Embarked'] = 2
all_data.loc[all_data['Sex'] == 'male', 'Sex'] = 0
all_data.loc[all_data['Sex'] == 'female', 'Sex'] = 1
traindata, testdata = all_data[:891], all_data[891:]
# print(traindata.shape, testdata.shape, all_data.shape) # (891, 15) (418, 15) (1309, 15)
traindata, trainlabel = traindata.drop('Survived', axis=1), traindata['Survived'] # train.pop('Survived')
testdata = testdata
corrDf = all_data.corr()
'''
檢視各個特徵與生成情況(Survived)的相關係數,
ascending=False表示按降序排列
'''
res = corrDf['Survived'].sort_values(ascending=False)
print(res)
return traindata, trainlabel, testdata
# A function to get the title from a name
def get_title(name):
# use a regular expression to search for a title
title_search = re.search('([A-Za-z]+)\.', name)
# if the title exists, extract and return it
if title_search:
return title_search.group(1)
return ''
OK,下一步,我們就需要進行特徵工程對補全後的特徵做進一步處理。
3.2 特徵處理
當補全資料後,我們查看了資料型別,總共有三種資料型別。有整形 int, 有浮點型 float, 有object。我們需要用數值替代類別。有些動作我們前面已經做過了,但是這裡總體再過一遍。
- 1,乘客性別(Sex):男性male,女性 female male=0,female=1
- 2,登船港口(Embarked):S,C,Q S=0, C=1, Q=2
- 3,乘客姓名(Name):我們分為六類(具體見前面2.7 不同稱呼與倖存率的關係)
程式碼如下(其實上面都有):
all_data.loc[all_data['Embarked'] == 'S', 'Embarked'] = 0
all_data.loc[all_data['Embarked'] == 'C', 'Embarked'] = 1
all_data.loc[all_data['Embarked'] == 'Q', 'Embarked'] = 2
all_data.loc[all_data['Sex'] == 'male', 'Sex'] = 0
all_data.loc[all_data['Sex'] == 'female', 'Sex'] = 1
titles = all_data['Name'].apply(get_title)
# print(pd.value_counts(titles))
# map each title to an integer some titles are very rare
# and are compressed into the same codes as other titles
title_mapping = {
'Mr': 2,
'Miss': 3,
'Mrs': 4,
'Master': 1,
'Rev': 5,
'Dr': 5,
'Col': 5,
'Mlle': 3,
'Ms': 4,
'Major': 6,
'Don': 5,
'Countess': 5,
'Mme': 4,
'Jonkheer': 1,
'Sir': 5,
'Dona': 5,
'Capt': 6,
'Lady': 5,
}
for k, v in title_mapping.items():
titles[titles == k] = v
# print(k, v)
all_data['Title'] = titles
4,特徵提取
一般來說,一個比較真實的專案,也就是說資料探勘工程需要建立特徵工程,我們需要看看如何提取新的特徵,使得我們的準確率更高。這個怎麼說呢,其實我們上面對資料分析了那麼多,肯定是有原因的。下面一一闡述。
4.1 隨機森林尋找重要特徵
上面我們將資料缺失值填充完後,然後進行了概述,總共有14個特徵,1個結果(Survived),其中四個特徵是object型別,我們去掉,剩下了10個特徵,我們做重要特徵提取
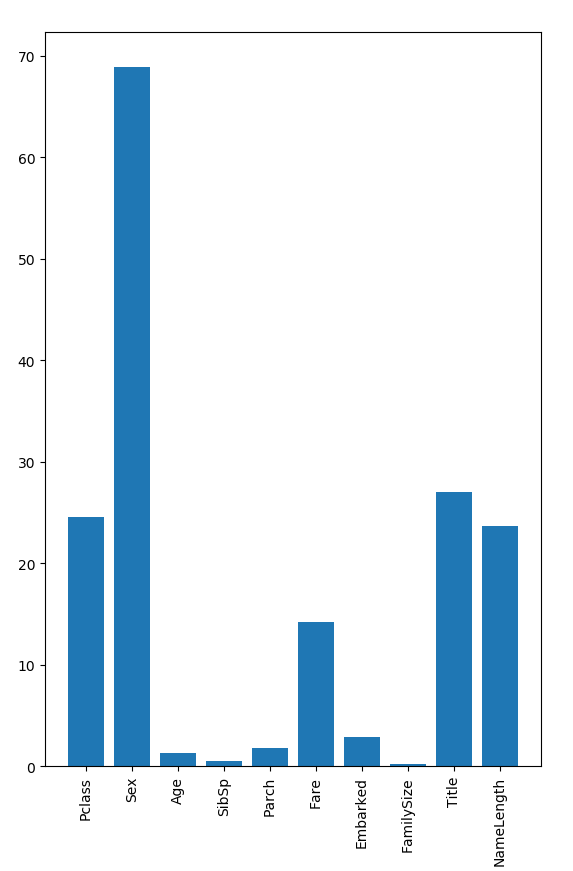
我們使用上面五個比較重要的特徵:Pclass,Sex,Fare,Title, NameLength 做隨機森林模型訓練。
def random_forestclassifier_train(traindata, trainlabel, testdata):
# predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilySize', 'Title', 'NameLength']
predictors =['Pclass', 'Sex', 'Fare', 'Title', 'NameLength', ]
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正確率為 %s%%" % test_accuracy) # 正確率為 80.44692737430168%
準確率還沒有不提取特徵的高。。。。這就有點尷尬哈。
4.2 相關係數法
相關係數法:計算各個特徵的相關係數
# 相關性矩陣
corrDf = all_data.corr()
'''
檢視各個特徵與生成情況(Survived)的相關係數,
ascending=False表示按降序排列
'''
res = corrDf['Survived'].sort_values(ascending=False)
print(res)
結果如下:
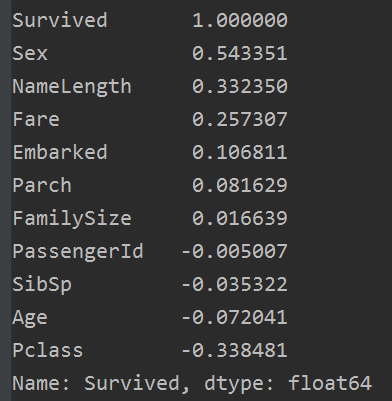
我們使用上面六個正相關的特徵:Sex,NameLength, Fare,Embarked,Parch, FamiySize, 做隨機森林模型訓練。
def random_forestclassifier_train(traindata, trainlabel, testdata):
# predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilySize', 'Title', 'NameLength']
predictors = ['Sex', 'Fare', 'Embarked', 'NameLength', 'Parch', 'FamilySize']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正確率為 %s%%" % test_accuracy) # 正確率為 81.56424581005587%
相比於上個隨機森林,效果好了不少,準確率提高了1個百分點。
4.3 嘗試用所有特徵做隨機森林模型訓練
def random_forestclassifier_train(traindata, trainlabel, testdata):
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilySize', 'Title', 'NameLength']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正確率為 %s%%" % test_accuracy) # 正確率為 83.79888268156425%
準確率進一步提高,這次提高了兩個百分點。
這可能是目前效果最好的吧。。。。。。
所以下一步進行整合學習各種嘗試,然後調參。。。。。。over
模型訓練及其結果展示
1,線性迴歸模型
這裡展示兩種線性迴歸的方式,但是不知道為什麼我的線性迴歸模型準確率低的可怕,都沒有蒙的多,只有37.63003367180264%。具體原因不知道,希望細心的網友幫我發現。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier
warnings.filterwarnings('ignore')
def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 為資料填充函式 用括號裡面的東西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata
def linear_regression_test(traindata, trainlabel, testdata):
traindata = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
traindata['Age'] = traindata['Age'].fillna(traindata['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
traindata.loc[traindata['Sex'] == 'male', 'Sex'] = 0
traindata.loc[traindata['Sex'] == 'female', 'Sex'] = 1
# .fillna() 為資料填充函式 用括號裡面的東西填充
traindata['Embarked'] = traindata['Embarked'].fillna('S')
traindata.loc[traindata['Embarked'] == 'S', 'Embarked'] = 0
traindata.loc[traindata['Embarked'] == 'C', 'Embarked'] = 1
traindata.loc[traindata['Embarked'] == 'Q', 'Embarked'] = 2
# the columns we'll use to predict the target
all_variables = ['PassengerID', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked']
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
# traindata, testdata = traindata[predictors], testdata[predictors]
alg = LinearRegression()
kf = KFold(n_splits=3, random_state=1)
predictions = []
for train_index, test_index in kf.split(traindata):
# print(train_index, test_index)
train_predictors = (traindata[predictors].iloc[train_index, :])
train_target = traindata['Survived'].iloc[train_index]
alg.fit(train_predictors, train_target)
test_predictions = alg.predict(traindata[predictors].iloc[test_index, :])
predictions.append(test_predictions)
# print(type(predictions))
predictions = np.concatenate(predictions, axis=0) #<class 'numpy.ndarray'>
# print(type(predictions))
predictions[predictions > 0.5] = 1
predictions[predictions < 0.5] = 1
accuracy = sum(predictions[predictions == traindata['Survived']]/len(predictions))
print(accuracy) # 0.3838383838383825
def linear_regression_train(traindata, trainlabel, testdata):
# the columns we'll use to predict the target
all_variables = ['PassengerID', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked']
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
traindata, testdata = traindata[predictors], testdata[predictors]
print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = LinearRegression()
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正確率為 %s%%" % test_accuracy) # 正確率為 37.63003367180264%
# res = clf.predict(testdata)
if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
# print(traindata.shape[1]) # 11
linear_regression_train(traindata, trainlabel, testdata)
# linear_regression_test(traindata, trainlabel, testdata)
2,邏輯迴歸模型
邏輯迴歸也是隻選擇了幾個比較全的特徵,準確率還好,達到了: 81.56424581005587%。程式碼如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier
warnings.filterwarnings('ignore')
def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 為資料填充函式 用括號裡面的東西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata
def logistic_regression_train(traindata, trainlabel, testdata):
# the columns we'll use to predict the target
all_variables = ['PassengerID', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked']
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = LogisticRegression()
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正確率為 %s%%" % test_accuracy) # 正確率為 81.56424581005587%
# res = clf.predict(testdata)
if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
logistic_regression_train(traindata, trainlabel, testdata)
3,隨機森林模型
我們依舊選擇和上面相同的特徵,使用隨機森林來做,準確率為:81.56424581005587%。效果還行,不過也只是和邏輯迴歸一樣,程式碼如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier
warnings.filterwarnings('ignore')
def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 為資料填充函式 用括號裡面的東西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata
def random_forestclassifier_train(traindata, trainlabel, testdata):
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正確率為 %s%%" % test_accuracy) # 正確率為 81.56424581005587%
if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
random_forestclassifier_train(traindata, trainlabel, testdata)
4,整合學習模型
這裡簡單的整合GradientBoostingClassifier和LogisticRegression 兩種演算法。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.ensemble import GradientBoostingClassifier
import re
warnings.filterwarnings('ignore')
# A function to get the title from a name
def get_title(name):
# use a regular expression to search for a title
title_search = re.search('([A-Za-z]+)\.', name)
# if the title exists, extract and return it
if title_search:
return title_search.group(1)
return ''
def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 為資料填充函式 用括號裡面的東西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
# generating a familysize column 是指所有的家庭成員
train['FamilySize'] = train['SibSp'] + train['Parch']
test['FamilySize'] = test['SibSp'] + test['Parch']
# the .apply method generates a new series
train['NameLength'] = train['Name'].apply(lambda x: len(x))
test['NameLength'] = test['Name'].apply(lambda x: len(x))
titles_train = train['Name'].apply(get_title)
titles_test = test['Name'].apply(get_title)
title_mapping = {
'Mr': 1,
'Miss': 2,
'Mrs': 3,
'Master': 4,
'Rev': 6,
'Dr': 5,
'Col': 7,
'Mlle': 8,
'Ms': 2,
'Major': 7,
'Don': 9,
'Countess': 10,
'Mme': 8,
'Jonkheer': 10,
'Sir': 9,
'Dona': 9,
'Capt': 7,
'Lady': 10,
}
for k, v in title_mapping.items():
titles_train[titles_train == k] = v
train['Title'] = titles_train
for k, v in title_mapping.items():
titles_test[titles_test == k] = v
test['Title'] = titles_test
# print(pd.value_counts(titles_train))
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata
def emsemble_model_train(traindata, trainlabel, testdata):
# the algorithms we want to ensemble
# we're using the more linear predictors for the logistic regression,
# and everything with the gradient boosting classifier
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3),
['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked', ]],
[LogisticRegression(random_state=1),
['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked', ]]
]
# initialize the cross validation folds
kf = KFold(n_splits=3, random_state=1)
predictions = []
for train_index, test_index in kf.split(traindata):
# print(train_index, test_index)
full_test_predictions = []
for alg, predictors in algorithms:
train_predictors = (traindata[predictors].iloc[train_index, :])
train_target = trainlabel.iloc[train_index]
alg.fit(train_predictors, train_target)
test_predictions = alg.predict(traindata[predictors].iloc[test_index, :])
full_test_predictions.append(test_predictions)
# use a simple ensembling scheme
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
test_predictions[test_predictions <= 0.5] = 0
test_predictions[test_predictions >= 0.5] = 1
predictions.append(test_predictions)
predictions = np.concatenate(predictions, axis=0)
# compute accuracy bu comparing to the training data
accuracy = sum(predictions[predictions == trainlabel]) / len(predictions)
print(accuracy)
def emsemble_model_train(traindata, trainlabel, testdata):
# the algorithms we want to ensemble
# we're using the more linear predictors for the logistic regression,
# and everything with the gradient boosting classifier
predictors = ['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked', ]
traindata, testdata = traindata[predictors], testdata[predictors]
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf1 = GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3)
clf2 = LogisticRegression(random_state=1)
# training the algorithm using the predictors and target
clf1.fit(trainSet, trainlabel)
clf2.fit(trainSet, trainlabel)
test_accuracy1 = clf1.score(testSet, testlabel) * 100
test_accuracy2 = clf2.score(testSet, testlabel) * 100
print(test_accuracy1, test_accuracy2) # 78.77094972067039 80.44692737430168
print("正確率為 %s%%" % ((test_accuracy1+test_accuracy2)/2)) # 正確率為 79.60893854748603%
if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
emsemble_model_train(traindata, trainlabel, testdata)
當然,對於整合學習中,整合集中演算法,也可以使用賦予權重比的方式。具體可以參考:
Python機器學習筆記 整合學習總結
這裡不再多贅述。
我的GitHub地址:https://github.com/LeBron-Jian/Kaggle-learn
參考文獻:
https://www.jianshu.com/p/ee91d8880bbd
https://www.jianshu.com/p/e79a8c41cb1a
https://www.cnblogs.com/python-1807/p/10645170.html
https://blog.csdn.net/han_xiaoyang/article/details/4979