
深度學習(花書)讀書筆記——第二章-線性代數
第二章-線性代數
2.1 標量、向量、矩陣和張量
標量(scalar):一個標量就是一個單獨的數,它不同於線性代數中研究的其他大部分物件(通常是多個數的陣列)。向量(vector):一個向量是一列數。這些數是有序排列的。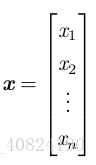
矩陣(matrix):矩陣是一個二維陣列。
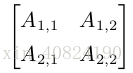
張量(tensor):在某些情況下,我們會討論座標超過兩維的陣列。一般地,一個數組中的元素分佈在若干維座標的規則網格中,我們稱之為張量。我們使用字型 A
轉置(transpose):
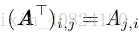
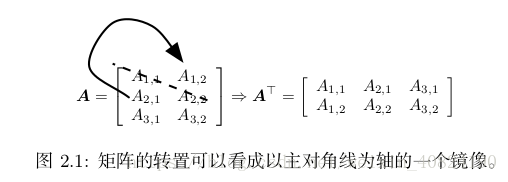
2.2 矩陣和向量相乘
C = AB:如果矩陣 A 的形狀是 m × n,矩陣 B 的形狀是 n × p,那麼矩陣C 的形狀是 m × p。
矩陣乘積服從分配律:A(B + C) = AB + AC
矩陣乘積也服從結合律:A(BC) = (AB)
不同於標量乘積,矩陣乘積並不滿足交換律(AB = BA 的情況並非總是滿足)。
矩陣乘積的轉置:
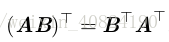
兩個向量的點積(dot product)滿足交換律:
2.3 單位矩陣和逆矩陣
單位矩陣(identity matrix):所有沿主對角線的元素都是 1,而所有其他位置的元素都是0。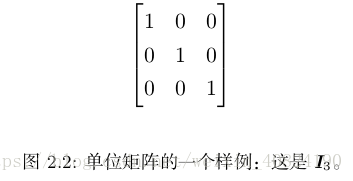
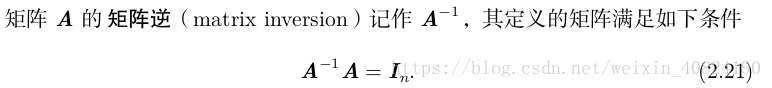
2.4 線性相關和生成子空間(p32)
2.5 範數
有時我們需要衡量一個向量的大小。在機器學習中,我們經常使用被稱為 範數(norm)的函式衡量向量大小。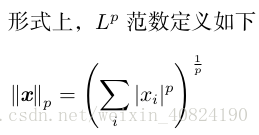
範數是將向量對映到非負值的函式。直觀上來說,向量 x 的範數衡量從原點到點 x 的距離。
當 p = 2 時,L2範數被稱為 歐幾里得範數(Euclidean norm)。它表示從原點出發到向量 x 確定的點的歐幾里得距離。L2範數在機器學習中出現地十分頻繁,經常簡化表示為||x||略去了下標 2。平方L2 範數也經常用來衡量向量的大小,可以簡單地通過點積xTx 計算。
注意:平方 L2 範數在數學和計算上都比 L2 範數本身更方便。例如,平方 L2
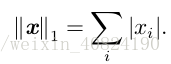
當機器學習問題中零和非零元素之間的差異非常重要時,通常會使用 L1 範數。每當x 中某個元素從 0 增加 ε,對應的 L 1 範數也會增加 ε。
另外一個經常在機器學習中出現的範數是 L ∞ 範數,也被稱為 最大範數(max norm)。這個範數表示向量中具有最大幅值的元素的絕對值:
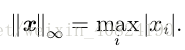
有時候我們可能也希望衡量矩陣的大小。在深度學習中,最常見的做法是使用 Frobenius 範數(Frobenius norm),F-範數。
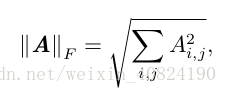
2.6 特殊型別的矩陣和向量
對角矩陣(diagonal matrix)只在主對角線上含有非零元素,其他位置都是零。對稱(symmetric)矩陣是轉置和自己相等的矩陣。單位向量(unit vector)是具有單位範數(unit norm)的向量:||x||2=1.正交矩陣(orthogonal matrix)是指行向量和列向量是分別標準正交的方陣:ATA=AAT=I.這意味著:A-1=AT所以正交矩陣受到關注是因為求逆計算代價小。
2.7 特徵分解
特徵分解(eigendecomposition)是使用最廣的矩陣分解之一,即我們將矩陣分解成一組特徵向量和特徵值。方陣 A 的特徵向量(eigenvector)是指與 A 相乘後相當於對該向量進行縮放的非零向量 v :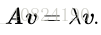
每個實對稱矩陣都可以分解成實特徵向量和實特徵值:
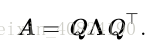
2.8 奇異值分解
奇異值分解(singular value decomposition, SVD),將矩陣分解為奇異向量(singular vector)和 奇異值(singular value)。通過奇異值分解,我們會得到一些與特徵分解相同型別的資訊。然而,奇異值分解有更廣泛的應用。每個實數矩陣都有一個奇異值分解,但不一定都有特徵分解。例如,非方陣的矩陣沒有特徵分解,這時我們只能使用奇異值分解。
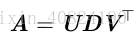
假設 A 是一個 m × n 的矩陣,那麼 U 是一個 m × m 的矩陣,D 是一個 m × n的矩陣,V 是一個 n × n 矩陣。這些矩陣中的每一個經定義後都擁有特殊的結構。矩陣 U 和 V 都定義為正交矩陣,而矩陣 D 定義為對角矩陣。注意,矩陣 D 不一定是方陣。
對角矩陣 D 對角線上的元素被稱為矩陣 A 的奇異值(singular value)。矩陣U 的列向量被稱為左奇異向量(left singular vector),矩陣 V 的列向量被稱 右奇異向量(right singular vector)。
事實上,我們可以用與 A 相關的特徵分解去解釋 A 的奇異值分解。A 的 左奇異向量(left singular vector)是 AAT 的特徵向量。 A 的 右奇異向量(right singularvector)是ATA的特徵向量。A 的非零奇異值是ATA特徵值的平方根,同時也是AAT 特徵值的平方根。
2.9 Moore-Penrose 偽逆
對於非方矩陣而言,其逆矩陣沒有定義。Moore-Penrose 偽逆(Moore-Penrose pseudoinverse)使我們在這類問題上取得了一定的進展。矩陣 A 的偽逆定義為:

計算偽逆的實際演算法沒有基於這個定義,而是使用下面的公式:
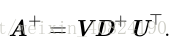
2.10 跡運算
跡運算返回的是矩陣對角元素的和: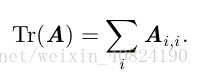
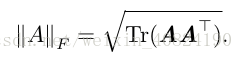
用跡運算表示表示式,我們可以使用很多有用的等式巧妙地處理表達式。例如,跡運算在轉置運算下是不變的:
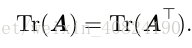
多個矩陣相乘得到的方陣的跡,和將這些矩陣中的最後一個挪到最前面之後相乘的跡是相同的。當然,我們需要考慮挪動之後矩陣乘積依然定義良好:
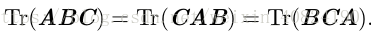
即使迴圈置換後矩陣乘積得到的矩陣形狀變了,跡運算的結果依然不變。例如,假設矩陣 A ∈ R m×n ,矩陣 B ∈ R n×m ,我們可以得到
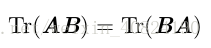 儘管 AB ∈ R m×m 和 BA ∈ R n×n 。
儘管 AB ∈ R m×m 和 BA ∈ R n×n 。另一個有用的事實是標量在跡運算後仍然是它自己:a = Tr(a)。