
Python資料探勘課程 四.決策樹DTC資料分析及鳶尾資料集分析
一. 分類及決策樹介紹
1.分類
分類其實是從特定的資料中挖掘模式,作出判斷的過程。比如Gmail郵箱裡有垃圾郵件分類器,一開始的時候可能什麼都不過濾,在日常使用過程中,我人工對於每一封郵件點選“垃圾”或“不是垃圾”,過一段時間,Gmail就體現出一定的智慧,能夠自動過濾掉一些垃圾郵件了。
這是因為在點選的過程中,其實是給每一條郵件打了一個“標籤”,這個標籤只有兩個值,要麼是“垃圾”,要麼“不是垃圾”,Gmail就會不斷研究哪些特點的郵件是垃圾,哪些特點的不是垃圾,形成一些判別的模式,這樣當一封信的郵件到來,就可以自動把郵件分到“垃圾”和“不是垃圾”這兩個我們人工設定的分類的其中一個。
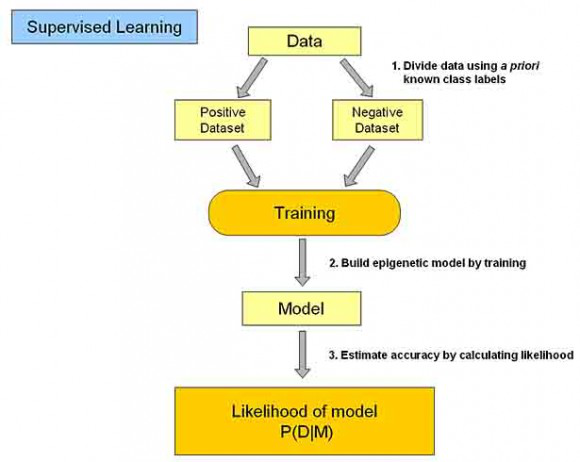
分類學習主要過程如下:
(1)訓練資料集存在一個類標記號,判斷它是正向資料集(起積極作用,不垃圾郵件),還是負向資料集(起抑制作用,垃圾郵件);
(2)然後需要對資料集進行學習訓練,並構建一個訓練的模型;
(3)通過該模型對預測資料集進預測,並計算其結果的效能。
2.決策樹(decision tree)
決策樹是用於分類和預測的主要技術之一,決策樹學習是以例項為基礎的歸納學習演算法,它著眼於從一組無次序、無規則的例項中推理出以決策樹表示的分類規則。構造決策樹的目的是找出屬性和類別間的關係,用它來預測將來未知類別的記錄的類別。它採用自頂向下的遞迴方式,在決策樹的內部節點進行屬性的比較,並根據不同屬性值判斷從該節點向下的分支,在決策樹的葉節點得到結論。
決策樹演算法根據資料的屬性採用樹狀結構建立決策模型, 決策樹模型常用來解決分類和迴歸問題。常見的演算法包括:分類及迴歸樹(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 隨機森林(Random Forest), 多元自適應迴歸樣條(MARS)以及梯度推進機(Gradient Boosting Machine, GBM)。
決策數有兩大優點:1)決策樹模型可以讀性好,具有描述性,有助於人工分析;2)效率高,決策樹只需要一次構建,反覆使用,每一次預測的最大計算次數不超過決策樹的深度。
示例1:
下面舉兩個例子,參考下面文章,強烈推薦大家閱讀,尤其是決策樹原理。
演算法雜貨鋪——分類演算法之決策樹(Decision tree) - leoo2sk
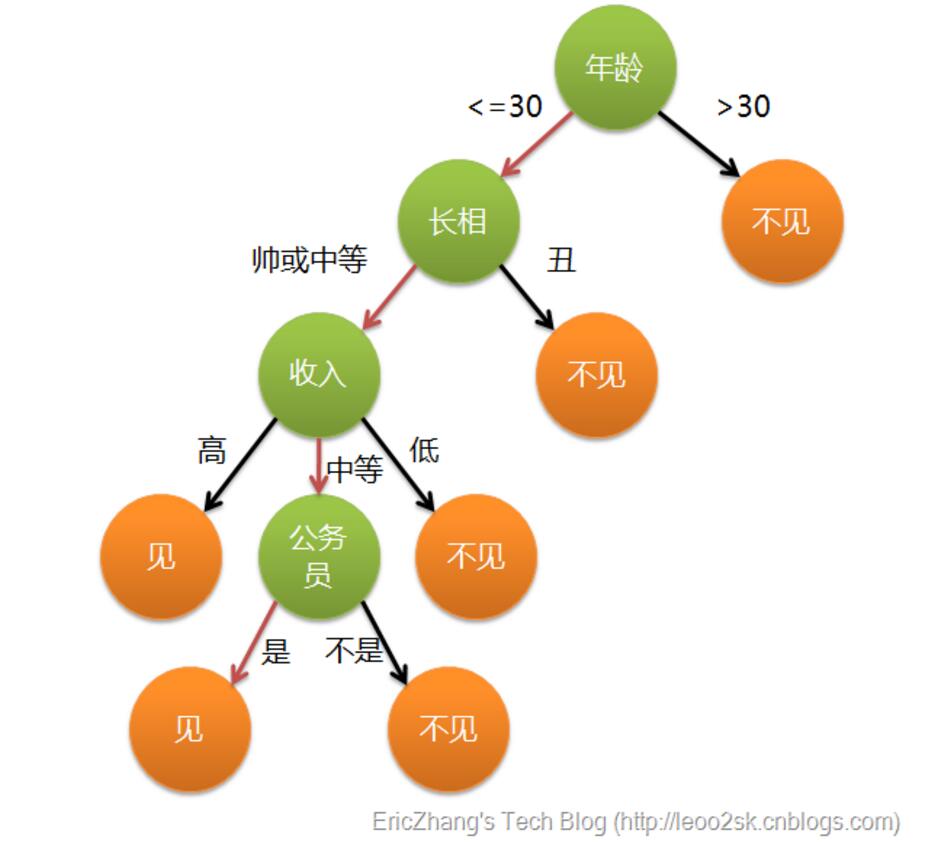
這個也是我上課講述的例子,引用上面文章的。通俗來說,決策樹分類的思想類似於找物件。現想象一個女孩的母親要給這個女孩介紹男朋友,於是有了下面的對話:
女兒:多大年紀了?
母親:26。
女兒:長的帥不帥?
母親:挺帥的。
女兒:收入高不?
母親:不算很高,中等情況。
女兒:是公務員不?
母親:是,在稅務局上班呢。
女兒:那好,我去見見。
這個女孩的決策過程就是典型的分類樹決策。相當於通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。假設這個女孩對男人的要求是:30歲以下、長相中等以上並且是高收入者或中等以上收入的公務員,那麼這個可以用下圖表示女孩的決策邏輯。
示例2:
另一個課堂上的例子,參考CSDN的大神lsldd的文章,推薦大家閱讀學習資訊熵。
用Python開始機器學習(2:決策樹分類演算法)
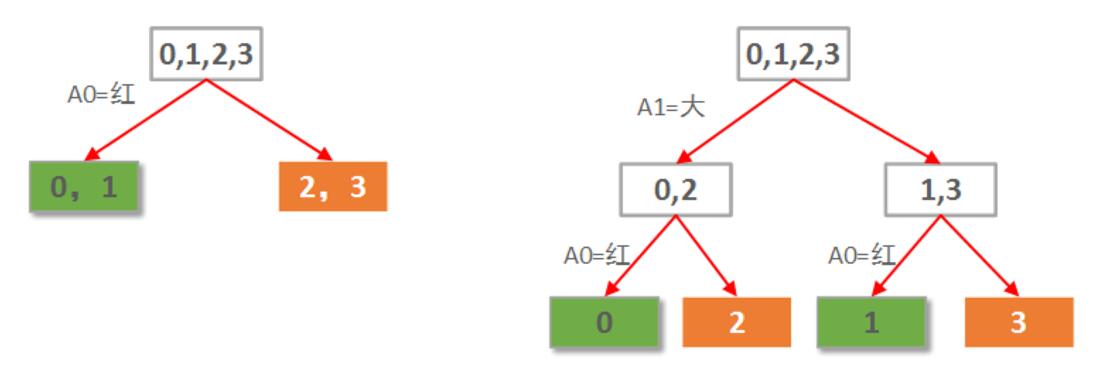
假設要構建這麼一個自動選好蘋果的決策樹,簡單起見,我只讓他學習下面這4個樣本:
- 樣本 紅 大 好蘋果
- 0111
- 1101
- 2010
- 3000
本例僅2個屬性。那麼很自然一共就只可能有2棵決策樹,如下圖所示:

決策樹構建的基本步驟如下:
1. 開始,所有記錄看作一個節點;
2. 遍歷每個變數的每一種分割方式,找到最好的分割點;
3. 分割成兩個節點N1和N2;
4. 對N1和N2分別繼續執行2-3步,直到每個節點足夠“純”為止。
二. 鳶尾花卉Iris資料集
在Sklearn機器學習包中,集成了各種各樣的資料集,上節課講述Kmeans使用的是一個NBA籃球運動員資料集,需要定義X多維矩陣或讀取檔案匯入,而這節課使用的是鳶尾花卉Iris資料集,它是很常用的一個數據集。
資料集來源:Iris
plants data set - KEEL dataset
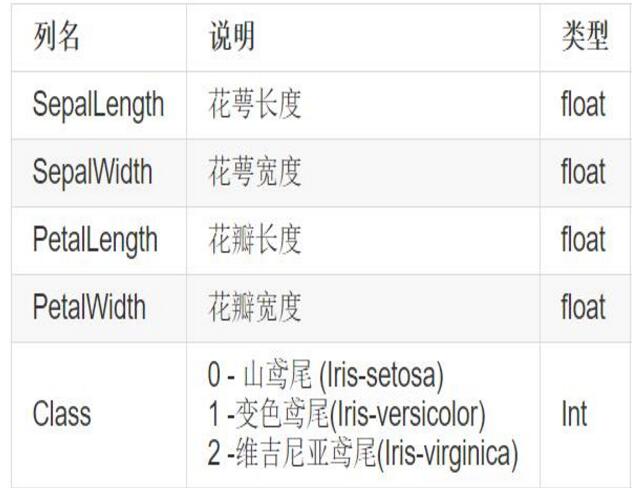
該資料集一共包含4個特徵變數,1個類別變數。共有150個樣本,鳶尾有三個亞屬,分別是山鳶尾 (Iris-setosa),變色鳶尾(Iris-versicolor)和維吉尼亞鳶尾(Iris-virginica)。
iris是鳶尾植物,這裡儲存了其萼片和花瓣的長寬,共4個屬性,鳶尾植物分三類。
iris裡有兩個屬性iris.data,iris.target。
data裡是一個矩陣,每一列代表了萼片或花瓣的長寬,一共4列,每一列代表某個被測量的鳶尾植物,一共取樣了150條記錄。程式碼如下:
- #匯入資料集iris
- from sklearn.datasets import load_iris
- #載入資料集
- iris = load_iris()
- #輸出資料集
- print iris.data
- [[ 5.13.51.40.2]
- [ 4.93.1.40.2]
- [ 4.73.21.30.2]
- [ 4.63.11.50.2]
- [ 5.3.61.40.2]
- [ 5.43.91.70.4]
- [ 4.63.41.40.3]
- [ 5.3.41.50.2]
- [ 4.42.91.40.2]
- ....
- [ 6.73.5.22.3]
- [ 6.32.55.1.9]
- [ 6.53.5.22. ]
- [ 6.23.45.42.3]
- [ 5.93.5.11.8]]
Iris Setosa(山鳶尾)
Iris Versicolour(雜色鳶尾)
Iris Virginica(維吉尼亞鳶尾)
- #輸出真實標籤
- print iris.target
- print len(iris.target)
- #150個樣本 每個樣本4個特徵
- print iris.data.shape
- [0000000000000000000000000000000000000
- 0000000000000111111111111111111111111
- 1111111111111111111111111122222222222
- 2222222222222222222222222222222222222
- 22]
- 150
- (150L, 4L)
下面給詳細介紹使用決策樹進行對這個資料集進行測試的程式碼。
三. 決策樹實現鳶尾資料集分析
1. DecisionTreeClassifier
Sklearn機器學習包中,決策樹實現類是DecisionTreeClassifier,能夠執行資料集的多類分類。
輸入引數為兩個陣列X[n_samples,n_features]和y[n_samples],X為訓練資料,y為訓練資料的標記資料。
DecisionTreeClassifier構造方法為:
- sklearn.tree.DecisionTreeClassifier(criterion='gini'
- , splitter='best'
- , max_depth=None
- , min_samples_split=2
- , min_samples_leaf=1
- , max_features=None
- , random_state=None
- , min_density=None
- , compute_importances=None
- , max_leaf_nodes=None)
- # -*- coding: utf-8 -*-
-
相關推薦
Python資料探勘課程 四.決策樹DTC資料分析及鳶尾資料集分析
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~ 一. 分類及決策樹介紹 1.分類 分類其實是從特定的資料中挖掘模式,作
《python資料分析和資料探勘》——ID3決策樹學習筆記
ID3決策樹 決策樹在分類預測和規則提取中有著廣泛的應用。他是一樹狀結構,每一個節點對應著一個分類,非葉節點對應著在某個屬性上的劃分,根據樣本在該屬性上的不同取值將其劃分成若干個子集。構造決策樹的核心問題就是如何選擇適當的屬性對樣本進行拆分。 基本原理 ————————希望自己能用
Thinking in SQL系列之四:資料探勘C4.5決策樹演算法
原創: 牛超 2017-02-11 Mail:[email protected] C4.5是一系列用在機器學習和資料探勘的分類問題中的演算法。它的目標是監督學習:給定一個數據集,其中的每一個元組都能用一組屬性值來描述,每一個元組屬於一個互斥的類別中的某一
資料探勘學習筆記-決策樹演算法淺析(含Java實現)
目錄 一、通俗理解決策樹演算法原理 二、舉例說明演算法執行過程 三、Java實現 本文基於書籍《資料探勘概念與技術》,由於剛接觸Data Mining,所以可能有理解不到位的情況,記錄學習筆記,提升自己對演算法的理解。 程式碼下方有,如果有金幣的童鞋可以貢獻一下給無恥的
【Python資料探勘課程】七.PCA降維操作及subplot子圖繪製
這篇文章主要介紹四個知識點,也是我那節課講課的內容。 1.PCA降維操作; 2.Python中Sklearn的PCA擴充套件包; 3.Matplotlib的subplot函式繪製子圖; 4.通過Kmean
python資料探勘課程 十三.WordCloud詞雲配置過程及詞頻分析
一. 安裝WordCloud 在使用WordCloud詞雲之前,需要使用pip安裝相應的包。 pip install WordCloud pip install jieba 其中WordCloud是詞雲,ji
機器學習——十大資料探勘之一的決策樹CART演算法
本文始發於個人公眾號:TechFlow,原創不易,求個關注 今天是**機器學習專題**的第23篇文章,我們今天分享的內容是十大資料探勘演算法之一的CART演算法。 CART演算法全稱是**Classification and regression tree**,也就是分類迴歸樹的意思。和之前介紹
【Python資料探勘課程】四.決策樹DTC資料分析及鳶尾資料集分析
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~一. 分類及決策樹介紹1.分類 分類其實是從特定的資料中挖掘模式,作出判斷的過程。比如Gmail郵箱
【python資料探勘課程】十九.鳶尾花資料集視覺化、線性迴歸、決策樹花樣分析
這是《Python資料探勘課程》系列文章,也是我這學期上課的部分內容。本文主要講述鳶尾花資料集的各種分析,包括視覺化分析、線性迴歸分析、決策樹分析等,通常一個數據集是可以用於多種分析的,希望這篇文章對大
【python資料探勘課程】十八.線性迴歸及多項式迴歸分析四個案例分享
這是《Python資料探勘課程》系列文章,也是我這學期大資料金融學院上課的部分內容。本文主要講述和分享線性迴歸作業中,學生們做得比較好的四個案例,經過我修改後供大家學習,內容包括: 1.線性迴歸預測Pizza價格案例 2.線性迴歸分析波士頓房價案例 3.隨機
【python資料探勘課程】十四.Scipy呼叫curve_fit實現曲線擬合
前面系列文章講過各種知識,包括繪製曲線、散點圖、冪分佈等,而如何在在散點圖一堆點中擬合一條直線,也變得非常重要。這篇文章主要講述呼叫Scipy擴充套件包的curve_fit函式實現曲線擬
Python資料探勘課程 六.Numpy、Pandas和Matplotlib包基礎知識
前面幾篇文章採用的案例的方法進行介紹的,這篇文章主要介紹Python常用的擴充套件包,同時結合資料探勘相關知識介紹該包具體的用法,主要介紹Numpy、Pandas和Matplotlib三個包。目錄: 一.Python常用擴充套件包
【Python資料探勘課程】五.線性迴歸知識及預測糖尿病例項
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~ 同時這篇文章是我上課的內容,所以參考了一些知識,強烈推薦大家學習斯坦福的機器學習Ng教授課程和Sc
【python資料探勘課程】十.Pandas、Matplotlib、PCA繪圖實用程式碼補充
這篇文章主要是最近整理《資料探勘與分析》課程中的作品及課件過程中,收集了幾段比較好的程式碼供大家學習。同時,做資料分析到後面,除非是研究演算法創新的,否則越來越覺得資料非常重要,才是有價值的東西。後面的課程會慢慢講解Python應用在Hadoop和Spark中,以及netwo
【python資料探勘課程】十五.Matplotlib呼叫imshow()函式繪製熱圖
前面系列文章講過資料探勘的各種知識,最近在研究人類時空動力學分析和冪率定律,發現在人類興趣轉移模型中,可以通過熱圖(斑圖)來進行描述的興趣轉移,如下圖所示。下一篇文章將簡單普及人類動力學相關知識研究。這
【python資料探勘課程】十二.Pandas、Matplotlib結合SQL語句對比圖分析
一. 直方圖四圖對比 資料庫如下所示,包括URL、作者、標題、摘要、日期、閱讀量和評論數等。 執行結果如下所示,其中繪製多個圖的核心程式碼為: p1 = plt.subplot(221) plt.bar(ind, num
【python資料探勘課程】十六.邏輯迴歸LogisticRegression分析鳶尾花資料
今天是教師節,容我先感嘆下。祝天下所有老師教師節快樂,這是自己的第二個教師節,這一年來,無限感慨,有給一個人的指導,有給十幾個人講畢設,有幾十人的實驗,有上百人的課堂,也有給上千人的Python網路直播
【Python資料探勘課程】六.Numpy、Pandas和Matplotlib包基礎知識
前面幾篇文章採用的案例的方法進行介紹的,這篇文章主要介紹Python常用的擴充套件包,同時結合資料探勘相關知識介紹該包具體的用法,主要介紹Numpy、Pandas和Matplotlib三
Python資料探勘課程 五.線性迴歸知識及預測糖尿病例項
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~ 同時這篇文章是我上課的內容,所以參考了一些知識,強烈推薦大家學習斯坦福的機器學習Ng教
【Python資料探勘課程】八.關聯規則挖掘及Apriori實現購物推薦
這篇文章主要介紹三個知識點,也是我《資料探勘與分析》課程講課的內容。 1.關聯規則挖掘概念及實現過程; 2.Apriori演算法挖掘頻繁項集; 3.Python實現關聯規則挖掘及置信度、支援度計算。一. 關聯規則挖掘概