
學習對稱形式的量化(Learning Symmetric Quantization)
"SYQ: Learning Symmetric Quantization For Efficient Deep Neural Networks"這篇文章提出了基於梯度的對稱量化(SYQ: Learning Symmetric Quantization)方法,可以設計高效率的二值化或三值化深度網路(1-bit或2-bit權重量化),並在pixel-wise、row-wise或者layer-wise定義不同粒度的縮放因子(scaling factor)用來估計網路引數。每一層的啟用輸出則採用線性量化表示為2-8bits定點數值。
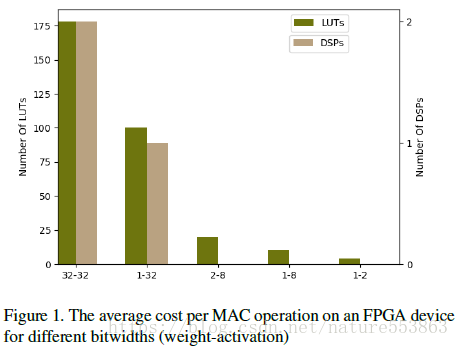
量化是一種行之有效的模型壓縮方法。如上圖所示,權重與啟用量化可有效降低網路計算的複雜度(MAC運算元)、並減少硬體實現(以FPGA實現為例)的資源消耗,包括DSP計算資源與儲存開銷等。尤其是在W1A2量化時,點積運算簡化為位元操作,計算開銷基本可忽略。否則若涉及乘法操作,計算資源開銷基本上與乘法器尺寸的二次方成比例。
權重量化操作將網路層的權重(通常為FP32型別)對映到一個有限精度(1-2bits、int8等)取值的離散數值集合(code-book)上。文章採用二值化或三值化方法用來量化網路權重,並採用STE法直接近似求導:

權重量化之後,通過尋找一個合適的縮放因子(scaling factor),能夠進一步降低量化帶來的精度損失。通過最小化損失函式可以尋求最優縮放因子:
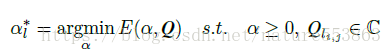
將權重分組、分開量化,能夠增強量化後模型的表示能力。文章採用對角矩陣描述pixel-wise、row-wise或者layer-wise的數值縮放操作,有助於權重分組、並控制量化粒度:
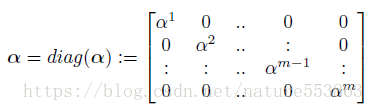
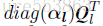
針對卷積層,先將權重在pixel-wise或者row-wise進行分組,然後通過對角矩陣執行縮放:
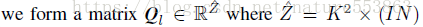
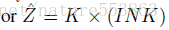
由於FC層對量化操作具有較強的魯棒性,因此FC層在layer-wise進行縮放,只需儲存一個可訓練的縮放因子。
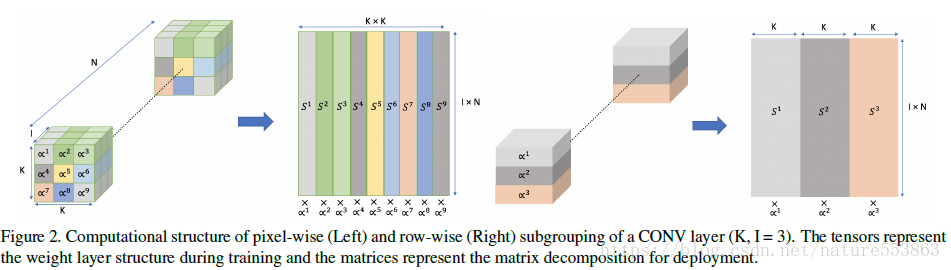
針對卷積層(K x K x I x N),上圖表示採用不同的分組方式,即在pixel-wise(左邊)或row-wise(右邊)構建權重量化的縮放操作時,所涉及的code-book及其索引方式。
文章接下來闡述了對稱形式的量化學習方法,首先定義了對稱量化器具備的特點:

則卷積層的每個權重分組,可按下式計算縮放因子的梯度,進而更新縮放因子:
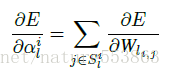
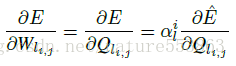
採用對稱分佈的code-book,能夠提供有序的索引方式、規整的計算形式,有利於降低計算複雜度、減少儲存開銷,且細粒度的權重量化與縮放能夠有效降低STE求導帶來的梯度失配。
卷積層每個分組縮放因子的初始化值表示為該組權重絕對值之和的均值:
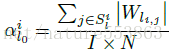
每一層的啟用輸出(activation)採用線性均勻方式予以量化,並採用STE方法近似求解導數:

結合權重(binary或ternary方式)、啟用(2-8bits線性方式)的量化、縮放因子的構造(分組形式的對角矩陣)、以及求導公式(STE求導),SYQ(Symmetric Quantization)訓練如下:

實驗部分在ImageNet 2012資料集(1.28M訓練圖片,50K驗證圖片)上做了測試,對比了不同量化粒度、量化位元數的實驗結果,並與其他量化方法做了比較。Resnet50採用W2-A8量化時,Top-1精度損失為4.8%(相比於baseline)。具體結論與結果見論文。
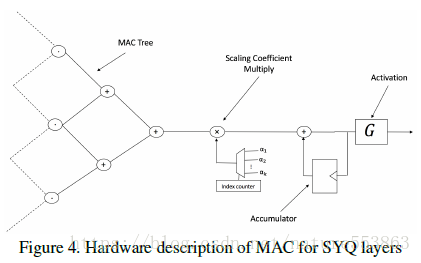
文章最後探討了基於SYQ量化(可簡化點積運算形式)的網路層硬體實現架構(Architecture),並在Xilinx FPGA上評估了資源消耗(LUT、DSP、BRAM)。如下圖所示,PE(Processing Element)首先執行不同分組內輸入與權重的乘累加操作(MAC),然後將加法器樹輸出乘以相應的scaling factor,進而將不同分組的scaling輸出累加在一起輸入到啟用單元:
論文地址:http://phwl.org/papers/syq_cvpr18.pdf
GitHub:https://github.com/julianfaraone/SYQ