
Spark入門-什麼是Spark
·spark認識
Spark使用Scala語言進行實現,它是一種面向物件、函數語言程式設計語言,能夠像操作本地集合物件一樣輕鬆地操作分散式資料集,在Spark官網上介紹,它具有執行速度快、易用性好、通用性強和隨處執行等特點。
spark特點
·執行速度快
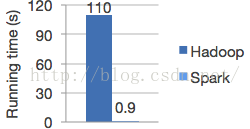
spark在記憶體中對資料進行迭代計算如果資料由記憶體讀取是hadoop MapReduce的100倍。Spark是基於記憶體的迭代計算框架,適用於需要多次操作特定資料集的應用場合。需要反覆操作的次數越多,所需讀取的資料量越大,受益越大,資料量小但是計算密集度較大的場合,受益就相對較小.
·易用性好
支援Scala程式設計java程式設計
·一次編譯,隨意執行
spark執行在Hadoop,cloud上,能夠讀取HDFS,HBase Cassandra等資料來源
·通用性強
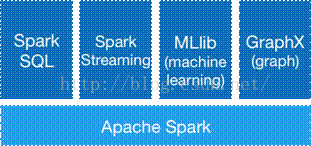
spark生態圈(BDAS)包括spark Core、spark SQL Spark Streaming等元件,這些元件提供spark Core處理記憶體計算框架
·Spak 和Hadoop區別
spark是在MapReduce上發展而來,繼承了其分散式平行計算的優點並改進了MapReduce明顯的缺陷:
1.提高了效率
Spark把中間資料放到記憶體中,迭代運算效率高。MapReduce中計算結果需要落地,儲存到磁碟上,這樣勢必會影響整體速度,而Spark支援DAG圖的分散式平行計算的程式設計框架,減少了迭代過程中資料的落地,提高了處理效率
2.容錯性高
Spark引進了彈性分散式資料集RDD (Resilient Distributed Dataset) 的抽象,它是分佈在一組節點中的只讀物件集合,這些集合是彈性的,如果資料集一部分丟失,需要進行重建。
相比來說spark更加通用,spark提供了更多的資料集操作型別,處理節點之間通訊模型不是向hadoop只採用Shuffle模式,而是採用使用者可命名,控制中
間結果的儲存,分割槽。
·Spark Core
1)提供了有向無環圖(DAG)的分散式平行計算框架,並提供Cache機制來支援多次迭代計算或者資料共享,大大減少迭代計算之間讀取資料局的開銷,這對於需要進行多次迭代的資料探勘和分析效能有很大提升
2)在Spark中引入了RDD (Resilient Distributed Dataset) 的抽象,它是分佈在一組節點中的只讀物件集合,這些集合是彈性的,如果資料集一部分丟失,則可以根據“血統”對它們進行重建,保證了資料的高容錯性;
移動計算而非移動資料,RDD Partition可以就近讀取分散式檔案系統中的資料塊到各個節點記憶體中進行計算
使用多執行緒池模型來減少task啟動開稍
3)採用容錯的、高可伸縮性的akka作為通訊框架
·Spark Streaming
SparkStreaming是一個對實時資料流進行高通量、容錯處理的流式處理系統,可以對多種資料來源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)進行類似Map、Reduce和Join等複雜操作,並將結果儲存到外部檔案系統、資料庫或應用到實時儀表盤。
·Spark SQL
SparkSQL的前身是Shark,Shark是伯克利實驗室Spark生態環境的元件之一,它修改了記憶體管理、物理計劃、執行三個模組,並使之能執行在Spark引擎上,從而使得SQL查詢的速度得到10-100倍的提升。Shark過於依賴Hive,它是當時唯一執行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce計算過程中大量的中間磁碟落地過程消耗了大量的I/O,降低執行效率.SparkSQL在資料相容性、效能優化、元件擴充套件等方面做了很大提升。