
Spark入門到精通(入門)——第二節 Spark 2.0.0 檢視job 歷史日誌
本文十分的重要,希望對大家的spark學習有一些幫助:
1 引言:
在使用Spark的時候,有時候我們會關注job的歷史日誌,但是在Spark中預設情況下,歷史日誌是關閉的,在本篇部落格中主要介紹一下如何啟動spark的歷史日誌。
2 開啟歷史日誌伺服器
2.1 安裝spark
參考
2.2 修改配置檔案
1修改spark-default.conf
//將模板檔案修改為配置檔案 cp spark-defaults.conf.template spark-defaults.conf //修改的配置資訊 spark.eventLog.enabled true //設定hdfs的目錄,需要和自己hadoop的目錄匹配 spark.eventLog.dir hdfs://linux102:9001/var/log/spark spark.eventLog.compress true
修改後的結果如圖所示
- spark.eventLog.enabled true
- spark.eventLog.dir hdfs://master01:9000/directory
- spark.eventLog.compress true
當然,:HDFS上的目錄需要提前存在
2 修改spark-env.sh檔案
spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://linux102:9001/directory"
3 引數描述:
spark.eventLog.dir:Application在執行過程中所有的資訊均記錄在該屬性指定的路徑下; spark.history.ui.port=4000 調整WEBUI訪問的埠號為4000 spark.history.fs.logDirectory=hdfs://linux102:9001/directory 配置了該屬性後,在start-history-server.sh時就無需再顯式的指定路徑,Spark History Server頁面只展示該指定路徑下的資訊 注意:我這裡修改了hdfs的埠號 spark.history.retainedApplications=3 指定儲存Application歷史記錄的個數,如果超過這個值,舊的應用程式資訊將被刪除,這個是記憶體中的應用數,而不是頁面上顯示的應用數。
4 測試
將配置好的Spark檔案拷貝到其他節點上 /home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
啟動後執行:【別忘了啟動HDFS】 /home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/sbin/start-history-server.sh
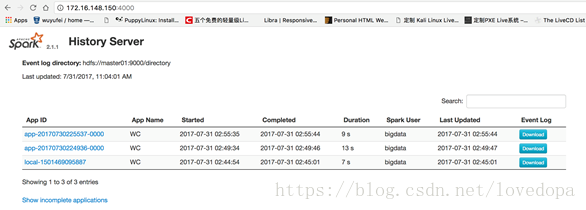
到此為止,Spark History Server安裝完畢. 如果遇到Hadoop HDFS的寫入許可權問題: org.apache.hadoop.security.AccessControlException 解決方案: 在hdfs-site.xml中新增如下配置,關閉許可權驗證 <property> <name>dfs.permissions</name> <value>false</value> </property>