
Apache Flink:詳細入門
阿新 • • 發佈:2018-12-30
Apache Flink是一個面向分散式資料流處理和批量資料處理的開源計算平臺,它能夠基於同一個Flink執行時(Flink Runtime),提供支援流處理和批處理兩種型別應用的功能。現有的開源計算方案,會把流處理和批處理作為兩種不同的應用型別,因為他們它們所提供的SLA是完全不相同的:流處理一般需要支援低延遲、Exactly-once保證,而批處理需要支援高吞吐、高效處理,所以在實現的時候通常是分別給出兩套實現方法,或者通過一個獨立的開源框架來實現其中每一種處理方案。例如,實現批處理的開源方案有MapReduce、Tez、Crunch、Spark,實現流處理的開源方案有Samza、Storm。
Flink在實現流處理和批處理時,與傳統的一些方案完全不同,它從另一個視角看待流處理和批處理,將二者統一起來:Flink是完全支援流處理,也就是說作為流處理看待時輸入資料流是無界的;批處理被作為一種特殊的流處理,只是它的輸入資料流被定義為有界的。基於同一個Flink執行時(Flink Runtime),分別提供了流處理和批處理API,而這兩種API也是實現上層面向流處理、批處理型別應用框架的基礎。
基本特性 關於Flink所支援的特性,我這裡只是通過分類的方式簡單做一下梳理,涉及到具體的一些概念及其原理會在後面的部分做詳細說明。
流處理特性
API支援
Libraries支援
整合支援
基本概念 Stream & Transformation & Operator 使用者實現的Flink程式是由Stream和Transformation這兩個基本構建塊組成,其中Stream是一箇中間結果資料,而Transformation是一個操作,它對一個或多個輸入Stream進行計算處理,輸出一個或多個結果Stream。當一個Flink程式被執行的時候,它會被對映為Streaming Dataflow。一個Streaming Dataflow是由一組Stream和Transformation Operator組成,它類似於一個DAG圖,在啟動的時候從一個或多個Source Operator開始,結束於一個或多個Sink Operator。
下面是一個由Flink程式對映為Streaming Dataflow的示意圖,如下所示:
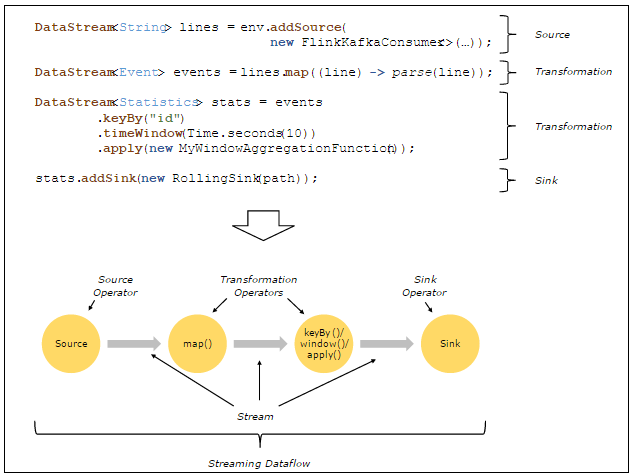
上圖中,FlinkKafkaConsumer是一個Source Operator,map、keyBy、timeWindow、apply是Transformation Operator,RollingSink是一個Sink Operator。
Parallel Dataflow 在Flink中,程式天生是並行和分散式的:一個Stream可以被分成多個Stream分割槽(Stream Partitions),一個Operator可以被分成多個Operator Subtask,每一個Operator Subtask是在不同的執行緒中獨立執行的。一個Operator的並行度,等於Operator Subtask的個數,一個Stream的並行度總是等於生成它的Operator的並行度。
有關Parallel Dataflow的例項,如下圖所示:

上圖Streaming Dataflow的並行檢視中,展現了在兩個Operator之間的Stream的兩種模式:
另外,Source Operator對應2個Subtask,所以並行度為2,而Sink Operator的Subtask只有1個,故而並行度為1。
Task & Operator Chain 在Flink分散式執行環境中,會將多個Operator Subtask串起來組成一個Operator Chain,實際上就是一個執行鏈,每個執行鏈會在TaskManager上一個獨立的執行緒中執行,如下圖所示:

上圖中上半部分表示的是一個Operator Chain,多個Operator通過Stream連線,而每個Operator在執行時對應一個Task;圖中下半部分是上半部分的一個並行版本,也就是對每一個Task都並行化為多個Subtask。
Time & Window Flink支援基於時間視窗操作,也支援基於資料的視窗操作,如下圖所示:
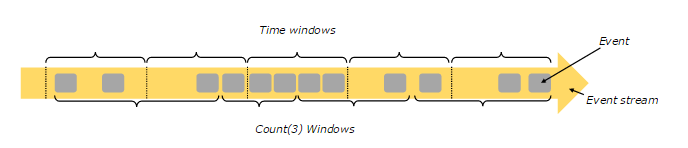
上圖中,基於時間的視窗操作,在每個相同的時間間隔對Stream中的記錄進行處理,通常各個時間間隔內的視窗操作處理的記錄數不固定;而基於資料驅動的視窗操作,可以在Stream中選擇固定數量的記錄作為一個視窗,對該視窗中的記錄進行處理。
有關視窗操作的不同型別,可以分為如下幾種:傾斜視窗(Tumbling Windows,記錄沒有重疊)、滑動視窗(Slide Windows,記錄有重疊)、會話視窗(Session Windows),具體可以查閱相關資料。
在處理Stream中的記錄時,記錄中通常會包含各種典型的時間欄位,Flink支援多種時間的處理,如下圖所示:
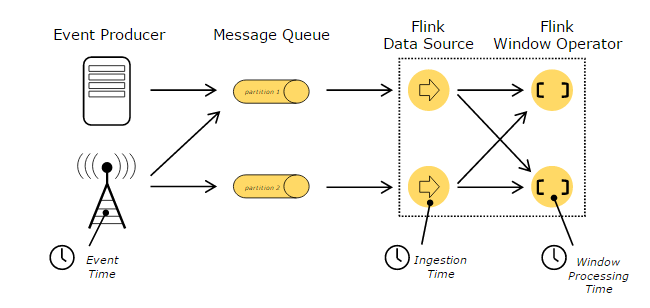
上圖描述了在基於Flink的流處理系統中,各種不同的時間所處的位置和含義,其中,Event Time表示事件建立時間,Ingestion Time表示事件進入到Flink Dataflow的時間 ,Processing Time表示某個Operator對事件進行處理事的本地系統時間(是在TaskManager節點上)。這裡,談一下基於Event Time進行處理的問題,通常根據Event Time會給整個Streaming應用帶來一定的延遲性,因為在一個基於事件的處理系統中,進入系統的事件可能會基於Event Time而發生亂序現象,比如事件來源於外部的多個系統,為了增強事件處理吞吐量會將輸入的多個Stream進行自然分割槽,每個Stream分割槽內部有序,但是要保證全域性有序必須同時兼顧多個Stream分割槽的處理,設定一定的時間視窗進行暫存資料,當多個Stream分割槽基於Event Time排列對齊後才能進行延遲處理。所以,設定的暫存資料記錄的時間視窗越長,處理效能越差,甚至嚴重影響Stream處理的實時性。
有關基於時間的Streaming處理,可以參考官方文件,在Flink中借鑑了Google使用的WaterMark實現方式,可以查閱相關資料。
基本架構 Flink系統的架構與Spark類似,是一個基於Master-Slave風格的架構,如下圖所示:
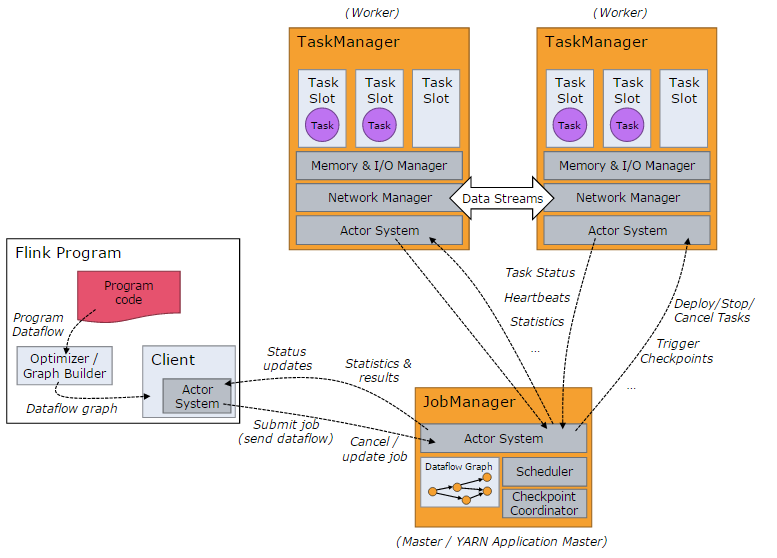
Flink叢集啟動時,會啟動一個JobManager程序、至少一個TaskManager程序。在Local模式下,會在同一個JVM內部啟動一個JobManager程序和TaskManager程序。當Flink程式提交後,會建立一個Client來進行預處理,並轉換為一個並行資料流,這是對應著一個Flink Job,從而可以被JobManager和TaskManager執行。在實現上,Flink基於Actor實現了JobManager和TaskManager,所以JobManager與TaskManager之間的資訊交換,都是通過事件的方式來進行處理。
如上圖所示,Flink系統主要包含如下3個主要的程序:
JobManager JobManager是Flink系統的協調者,它負責接收Flink Job,排程組成Job的多個Task的執行。同時,JobManager還負責收集Job的狀態資訊,並管理Flink叢集中從節點TaskManager。JobManager所負責的各項管理功能,它接收到並處理的事件主要包括:
TaskManager TaskManager也是一個Actor,它是實際負責執行計算的Worker,在其上執行Flink Job的一組Task。每個TaskManager負責管理其所在節點上的資源資訊,如記憶體、磁碟、網路,在啟動的時候將資源的狀態向JobManager彙報。TaskManager端可以分成兩個階段:
Client 當用戶提交一個Flink程式時,會首先建立一個Client,該Client首先會對使用者提交的Flink程式進行預處理,並提交到Flink叢集中處理,所以Client需要從使用者提交的Flink程式配置中獲取JobManager的地址,並建立到JobManager的連線,將Flink Job提交給JobManager。Client會將使用者提交的Flink程式組裝一個JobGraph, 並且是以JobGraph的形式提交的。一個JobGraph是一個Flink Dataflow,它由多個JobVertex組成的DAG。其中,一個JobGraph包含了一個Flink程式的如下資訊:JobID、Job名稱、配置資訊、一組JobVertex等。
元件棧
Flink是一個分層架構的系統,每一層所包含的元件都提供了特定的抽象,用來服務於上層元件。Flink分層的元件棧如下圖所示:

下面,我們自下而上,分別針對每一層進行解釋說明:
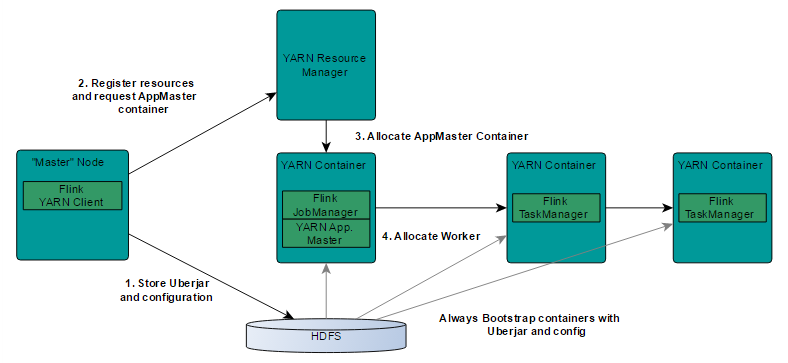
瞭解YARN的話,對上圖的原理非常熟悉,實際Flink也實現了滿足在YARN叢集上執行的各個元件:Flink YARN Client負責與YARN RM通訊協商資源請求,Flink JobManager和Flink TaskManager分別申請到Container去執行各自的程序。通過上圖可以看到,YARN AM與Flink JobManager在同一個Container中,這樣AM可以知道Flink JobManager的地址,從而AM可以申請Container去啟動Flink TaskManager。待Flink成功執行在YARN叢集上,Flink YARN Client就可以提交Flink Job到Flink JobManager,並進行後續的對映、排程和計算處理。
內部原理 容錯機制 Flink基於Checkpoint機制實現容錯,它的原理是不斷地生成分散式Streaming資料流Snapshot。在流處理失敗時,通過這些Snapshot可以恢復資料流處理。理解Flink的容錯機制,首先需要了解一下Barrier這個概念:
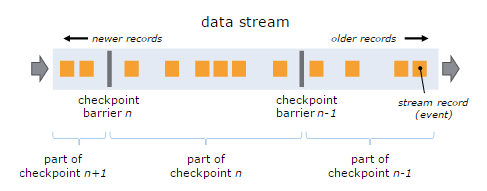
Stream Barrier是Flink分散式Snapshotting中的核心元素,它會作為資料流的記錄被同等看待,被插入到資料流中,將資料流中記錄的進行分組,並沿著資料流的方向向前推進。每個Barrier會攜帶一個Snapshot ID,屬於該Snapshot的記錄會被推向該Barrier的前方。因為Barrier非常輕量,所以並不會中斷資料流。帶有Barrier的資料流,如下圖所示:
基於上圖,我們通過如下要點來說明:
Operator的狀態包含兩種:一種是系統狀態,一個Operator進行計算處理的時候需要對資料進行緩衝,所以資料緩衝區的狀態是與Operator相關聯的,以視窗操作的緩衝區為例,Flink系統會收集或聚合記錄資料並放到緩衝區中,直到該緩衝區中的資料被處理完成;另一種是使用者自定義狀態(狀態可以通過轉換函式進行建立和修改),它可以是函式中的Java物件這樣的簡單變數,也可以是與函式相關的Key/Value狀態。
對於具有輕微狀態的Streaming應用,會生成非常輕量的Snapshot而且非常頻繁,但並不會影響資料流處理效能。Streaming應用的狀態會被儲存到一個可配置的儲存系統中,例如HDFS。在一個Checkpoint執行過程中,儲存的狀態資訊及其互動過程,如下圖所示:

在Checkpoint過程中,還有一個比較重要的操作——Stream Aligning。當Operator接收到多個輸入的資料流時,需要在Snapshot Barrier中對資料流進行排列對齊,如下圖所示:

具體排列過程如下:
排程機制 在JobManager端,會接收到Client提交的JobGraph形式的Flink Job,JobManager會將一個JobGraph轉換對映為一個ExecutionGraph,如下圖所示:

通過上圖可以看出:
JobGraph是一個Job的使用者邏輯視圖表示,將一個使用者要對資料流進行的處理表示為單個DAG圖(對應於JobGraph),DAG圖由頂點(JobVertex)和中間結果集(IntermediateDataSet)組成,其中JobVertex表示了對資料流進行的轉換操作,比如map、flatMap、filter、keyBy等操作,而IntermediateDataSet是由上游的JobVertex所生成,同時作為下游的JobVertex的輸入。
而ExecutionGraph是JobGraph的並行表示,也就是實際JobManager排程一個Job在TaskManager上執行的邏輯檢視,它也是一個DAG圖,是由ExecutionJobVertex、IntermediateResult(或IntermediateResultPartition)組成,ExecutionJobVertex實際對應於JobGraph圖中的JobVertex,只不過在ExecutionJobVertex內部是一種並行表示,由多個並行的ExecutionVertex所組成。另外,這裡還有一個重要的概念,就是Execution,它是一個ExecutionVertex的一次執行Attempt,也就是說,一個ExecutionVertex可能對應多個執行狀態的Execution,比如,一個ExecutionVertex執行產生了一個失敗的Execution,然後還會建立一個新的Execution來執行,這時就對應這個2次執行Attempt。每個Execution通過ExecutionAttemptID來唯一標識,在TaskManager和JobManager之間進行Task狀態的交換都是通過ExecutionAttemptID來實現的。
下面看一下,在物理上進行排程,基於資源的分配與使用的一個例子,來自官網,如下圖所示:
說明如下:
迭代機制 機器學習和圖計算應用,都會使用到迭代計算,Flink通過在迭代Operator中定義Step函式來實現迭代演算法,這種迭代演算法包括Iterate和Delta Iterate兩種型別,在實現上它們反覆地在當前迭代狀態上呼叫Step函式,直到滿足給定的條件才會停止迭代。下面,對Iterate和Delta Iterate兩種型別的迭代演算法原理進行說明:
Step函式在每一輪迭代中都會被執行,它可以是由map、reduce、join等Operator組成的資料流。下面通過官網給出的一個例子來說明Iterate Operator,非常簡單直觀,如下圖所示:
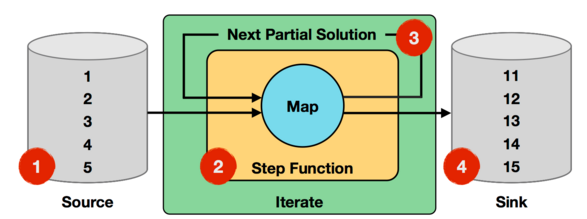
上面迭代過程中,輸入資料為1到5的數字,Step函式就是一個簡單的map函式,會對每個輸入的數字進行加1處理,而Next Partial Solution對應於經過map函式處理後的結果,比如第一輪迭代,對輸入的數字1加1後結果為2,對輸入的數字2加1後結果為3,直到對輸入數字5加1後結果為變為6,這些新生成結果數字2~6會作為第二輪迭代的輸入。迭代終止條件為進行10輪迭代,則最終的結果為11~15。
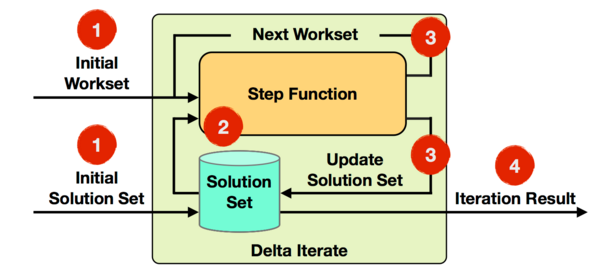
基於Delta Iterate Operator實現增量迭代,它有2個輸入,其中一個是初始Workset,表示輸入待處理的增量Stream資料,另一個是初始Solution Set,它是經過Stream方向上Operator處理過的結果。第一輪迭代會將Step函式作用在初始Workset上,得到的計算結果Workset作為下一輪迭代的輸入,同時還要增量更新初始Solution Set。如果反覆迭代知道滿足迭代終止條件,最後會根據Solution Set的結果,輸出最終迭代結果。
比如,我們現在已知一個Solution集合中儲存的是,已有的商品分類大類中購買量最多的商品,而Workset輸入的是來自線上實時交易中最新達成購買的商品的人數,經過計算會生成新的商品分類大類中商品購買量最多的結果,如果某些大類中商品購買量突然增長,它需要更新Solution Set中的結果(原來購買量最多的商品,經過增量迭代計算,可能已經不是最多),最後會輸出最終商品分類大類中購買量最多的商品結果集合。更詳細的例子,可以參考官網給出的“Propagate Minimum in Graph”,這裡不再累述。
Backpressure監控 Backpressure在流式計算系統中會比較受到關注,因為在一個Stream上進行處理的多個Operator之間,它們處理速度和方式可能非常不同,所以就存在上游Operator如果處理速度過快,下游Operator處可能機會堆積Stream記錄,嚴重會造成處理延遲或下游Operator負載過重而崩潰(有些系統可能會丟失資料)。因此,對下游Operator處理速度跟不上的情況,如果下游Operator能夠將自己處理狀態傳播給上游Operator,使得上游Operator處理速度慢下來就會緩解上述問題,比如通過告警的方式通知現有流處理系統存在的問題。
Flink Web介面上提供了對執行Job的Backpressure行為的監控,它通過使用Sampling執行緒對正在執行的Task進行堆疊跟蹤取樣來實現,具體實現方式如下圖所示:

JobManager會反覆呼叫一個Job的Task執行所線上程的Thread.getStackTrace(),預設情況下,JobManager會每間隔50ms觸發對一個Job的每個Task依次進行100次堆疊跟蹤呼叫,根據呼叫呼叫結果來確定Backpressure,Flink是通過計算得到一個比值(Radio)來確定當前執行Job的Backpressure狀態。在Web介面上可以看到這個Radio值,它表示在一個內部方法呼叫中阻塞(Stuck)的堆疊跟蹤次數,例如,radio=0.01,表示100次中僅有1次方法呼叫阻塞。Flink目前定義瞭如下Backpressure狀態:
另外,Flink還提供了3個引數來配置Backpressure監控行為:
通過上面個定義的Backpressure狀態,以及調整相應的引數,可以確定當前執行的Job的狀態是否正常,並且保證不影響JobManager提供服務。
Flink在實現流處理和批處理時,與傳統的一些方案完全不同,它從另一個視角看待流處理和批處理,將二者統一起來:Flink是完全支援流處理,也就是說作為流處理看待時輸入資料流是無界的;批處理被作為一種特殊的流處理,只是它的輸入資料流被定義為有界的。基於同一個Flink執行時(Flink Runtime),分別提供了流處理和批處理API,而這兩種API也是實現上層面向流處理、批處理型別應用框架的基礎。
基本特性 關於Flink所支援的特性,我這裡只是通過分類的方式簡單做一下梳理,涉及到具體的一些概念及其原理會在後面的部分做詳細說明。
流處理特性
- 支援高吞吐、低延遲、高效能的流處理
- 支援帶有事件時間的視窗(Window)操作
- 支援有狀態計算的Exactly-once語義
- 支援高度靈活的視窗(Window)操作,支援基於time、count、session,以及data-driven的視窗操作
- 支援具有Backpressure功能的持續流模型
- 支援基於輕量級分散式快照(Snapshot)實現的容錯
- 一個執行時同時支援Batch on Streaming處理和Streaming處理
- Flink在JVM內部實現了自己的記憶體管理
- 支援迭代計算
-
支援程式自動優化:避免特定情況下Shuffle、排序等昂貴操作,中間結果有必要進行快取
API支援
- 對Streaming資料類應用,提供DataStream API
-
對批處理類應用,提供DataSet API(支援Java/Scala)
Libraries支援
- 支援機器學習(FlinkML)
- 支援圖分析(Gelly)
- 支援關係資料處理(Table)
-
支援複雜事件處理(CEP)
整合支援
- 支援Flink on YARN
- 支援HDFS
- 支援來自Kafka的輸入資料
- 支援Apache HBase
- 支援Hadoop程式
- 支援Tachyon
- 支援ElasticSearch
- 支援RabbitMQ
- 支援Apache Storm
- 支援S3
-
支援XtreemFS
基本概念 Stream & Transformation & Operator 使用者實現的Flink程式是由Stream和Transformation這兩個基本構建塊組成,其中Stream是一箇中間結果資料,而Transformation是一個操作,它對一個或多個輸入Stream進行計算處理,輸出一個或多個結果Stream。當一個Flink程式被執行的時候,它會被對映為Streaming Dataflow。一個Streaming Dataflow是由一組Stream和Transformation Operator組成,它類似於一個DAG圖,在啟動的時候從一個或多個Source Operator開始,結束於一個或多個Sink Operator。
下面是一個由Flink程式對映為Streaming Dataflow的示意圖,如下所示:
上圖中,FlinkKafkaConsumer是一個Source Operator,map、keyBy、timeWindow、apply是Transformation Operator,RollingSink是一個Sink Operator。
Parallel Dataflow 在Flink中,程式天生是並行和分散式的:一個Stream可以被分成多個Stream分割槽(Stream Partitions),一個Operator可以被分成多個Operator Subtask,每一個Operator Subtask是在不同的執行緒中獨立執行的。一個Operator的並行度,等於Operator Subtask的個數,一個Stream的並行度總是等於生成它的Operator的並行度。
有關Parallel Dataflow的例項,如下圖所示:
上圖Streaming Dataflow的並行檢視中,展現了在兩個Operator之間的Stream的兩種模式:
-
One-to-one模式
-
Redistribution模式
另外,Source Operator對應2個Subtask,所以並行度為2,而Sink Operator的Subtask只有1個,故而並行度為1。
Task & Operator Chain 在Flink分散式執行環境中,會將多個Operator Subtask串起來組成一個Operator Chain,實際上就是一個執行鏈,每個執行鏈會在TaskManager上一個獨立的執行緒中執行,如下圖所示:
上圖中上半部分表示的是一個Operator Chain,多個Operator通過Stream連線,而每個Operator在執行時對應一個Task;圖中下半部分是上半部分的一個並行版本,也就是對每一個Task都並行化為多個Subtask。
Time & Window Flink支援基於時間視窗操作,也支援基於資料的視窗操作,如下圖所示:
上圖中,基於時間的視窗操作,在每個相同的時間間隔對Stream中的記錄進行處理,通常各個時間間隔內的視窗操作處理的記錄數不固定;而基於資料驅動的視窗操作,可以在Stream中選擇固定數量的記錄作為一個視窗,對該視窗中的記錄進行處理。
有關視窗操作的不同型別,可以分為如下幾種:傾斜視窗(Tumbling Windows,記錄沒有重疊)、滑動視窗(Slide Windows,記錄有重疊)、會話視窗(Session Windows),具體可以查閱相關資料。
在處理Stream中的記錄時,記錄中通常會包含各種典型的時間欄位,Flink支援多種時間的處理,如下圖所示:
上圖描述了在基於Flink的流處理系統中,各種不同的時間所處的位置和含義,其中,Event Time表示事件建立時間,Ingestion Time表示事件進入到Flink Dataflow的時間 ,Processing Time表示某個Operator對事件進行處理事的本地系統時間(是在TaskManager節點上)。這裡,談一下基於Event Time進行處理的問題,通常根據Event Time會給整個Streaming應用帶來一定的延遲性,因為在一個基於事件的處理系統中,進入系統的事件可能會基於Event Time而發生亂序現象,比如事件來源於外部的多個系統,為了增強事件處理吞吐量會將輸入的多個Stream進行自然分割槽,每個Stream分割槽內部有序,但是要保證全域性有序必須同時兼顧多個Stream分割槽的處理,設定一定的時間視窗進行暫存資料,當多個Stream分割槽基於Event Time排列對齊後才能進行延遲處理。所以,設定的暫存資料記錄的時間視窗越長,處理效能越差,甚至嚴重影響Stream處理的實時性。
有關基於時間的Streaming處理,可以參考官方文件,在Flink中借鑑了Google使用的WaterMark實現方式,可以查閱相關資料。
基本架構 Flink系統的架構與Spark類似,是一個基於Master-Slave風格的架構,如下圖所示:
Flink叢集啟動時,會啟動一個JobManager程序、至少一個TaskManager程序。在Local模式下,會在同一個JVM內部啟動一個JobManager程序和TaskManager程序。當Flink程式提交後,會建立一個Client來進行預處理,並轉換為一個並行資料流,這是對應著一個Flink Job,從而可以被JobManager和TaskManager執行。在實現上,Flink基於Actor實現了JobManager和TaskManager,所以JobManager與TaskManager之間的資訊交換,都是通過事件的方式來進行處理。
如上圖所示,Flink系統主要包含如下3個主要的程序:
JobManager JobManager是Flink系統的協調者,它負責接收Flink Job,排程組成Job的多個Task的執行。同時,JobManager還負責收集Job的狀態資訊,並管理Flink叢集中從節點TaskManager。JobManager所負責的各項管理功能,它接收到並處理的事件主要包括:
-
RegisterTaskManager
-
SubmitJob
-
CancelJob
-
UpdateTaskExecutionState
-
RequestNextInputSplit
-
JobStatusChanged
TaskManager TaskManager也是一個Actor,它是實際負責執行計算的Worker,在其上執行Flink Job的一組Task。每個TaskManager負責管理其所在節點上的資源資訊,如記憶體、磁碟、網路,在啟動的時候將資源的狀態向JobManager彙報。TaskManager端可以分成兩個階段:
-
註冊階段
-
可操作階段
Client 當用戶提交一個Flink程式時,會首先建立一個Client,該Client首先會對使用者提交的Flink程式進行預處理,並提交到Flink叢集中處理,所以Client需要從使用者提交的Flink程式配置中獲取JobManager的地址,並建立到JobManager的連線,將Flink Job提交給JobManager。Client會將使用者提交的Flink程式組裝一個JobGraph, 並且是以JobGraph的形式提交的。一個JobGraph是一個Flink Dataflow,它由多個JobVertex組成的DAG。其中,一個JobGraph包含了一個Flink程式的如下資訊:JobID、Job名稱、配置資訊、一組JobVertex等。
元件棧
Flink是一個分層架構的系統,每一層所包含的元件都提供了特定的抽象,用來服務於上層元件。Flink分層的元件棧如下圖所示:
下面,我們自下而上,分別針對每一層進行解釋說明:
-
Deployment層
瞭解YARN的話,對上圖的原理非常熟悉,實際Flink也實現了滿足在YARN叢集上執行的各個元件:Flink YARN Client負責與YARN RM通訊協商資源請求,Flink JobManager和Flink TaskManager分別申請到Container去執行各自的程序。通過上圖可以看到,YARN AM與Flink JobManager在同一個Container中,這樣AM可以知道Flink JobManager的地址,從而AM可以申請Container去啟動Flink TaskManager。待Flink成功執行在YARN叢集上,Flink YARN Client就可以提交Flink Job到Flink JobManager,並進行後續的對映、排程和計算處理。
-
Runtime層
-
API層
-
Libraries層
內部原理 容錯機制 Flink基於Checkpoint機制實現容錯,它的原理是不斷地生成分散式Streaming資料流Snapshot。在流處理失敗時,通過這些Snapshot可以恢復資料流處理。理解Flink的容錯機制,首先需要了解一下Barrier這個概念:
Stream Barrier是Flink分散式Snapshotting中的核心元素,它會作為資料流的記錄被同等看待,被插入到資料流中,將資料流中記錄的進行分組,並沿著資料流的方向向前推進。每個Barrier會攜帶一個Snapshot ID,屬於該Snapshot的記錄會被推向該Barrier的前方。因為Barrier非常輕量,所以並不會中斷資料流。帶有Barrier的資料流,如下圖所示:
基於上圖,我們通過如下要點來說明:
- 出現一個Barrier,在該Barrier之前出現的記錄都屬於該Barrier對應的Snapshot,在該Barrier之後出現的記錄屬於下一個Snapshot
- 來自不同Snapshot多個Barrier可能同時出現在資料流中,也就是說同一個時刻可能併發生成多個Snapshot
-
當一箇中間(Intermediate)Operator接收到一個Barrier後,它會發送Barrier到屬於該Barrier的Snapshot的資料流中,等到Sink Operator接收到該Barrier後會向Checkpoint Coordinator確認該Snapshot,直到所有的Sink Operator都確認了該Snapshot,才被認為完成了該Snapshot
Operator的狀態包含兩種:一種是系統狀態,一個Operator進行計算處理的時候需要對資料進行緩衝,所以資料緩衝區的狀態是與Operator相關聯的,以視窗操作的緩衝區為例,Flink系統會收集或聚合記錄資料並放到緩衝區中,直到該緩衝區中的資料被處理完成;另一種是使用者自定義狀態(狀態可以通過轉換函式進行建立和修改),它可以是函式中的Java物件這樣的簡單變數,也可以是與函式相關的Key/Value狀態。
對於具有輕微狀態的Streaming應用,會生成非常輕量的Snapshot而且非常頻繁,但並不會影響資料流處理效能。Streaming應用的狀態會被儲存到一個可配置的儲存系統中,例如HDFS。在一個Checkpoint執行過程中,儲存的狀態資訊及其互動過程,如下圖所示:
在Checkpoint過程中,還有一個比較重要的操作——Stream Aligning。當Operator接收到多個輸入的資料流時,需要在Snapshot Barrier中對資料流進行排列對齊,如下圖所示:
具體排列過程如下:
- Operator從一個incoming Stream接收到Snapshot Barrier n,然後暫停處理,直到其它的incoming Stream的Barrier n(否則屬於2個Snapshot的記錄就混在一起了)到達該Operator
- 接收到Barrier n的Stream被臨時擱置,來自這些Stream的記錄不會被處理,而是被放在一個Buffer中
- 一旦最後一個Stream接收到Barrier n,Operator會emit所有暫存在Buffer中的記錄,然後向Checkpoint Coordinator傳送Snapshot n
-
繼續處理來自多個Stream的記錄
排程機制 在JobManager端,會接收到Client提交的JobGraph形式的Flink Job,JobManager會將一個JobGraph轉換對映為一個ExecutionGraph,如下圖所示:
通過上圖可以看出:
JobGraph是一個Job的使用者邏輯視圖表示,將一個使用者要對資料流進行的處理表示為單個DAG圖(對應於JobGraph),DAG圖由頂點(JobVertex)和中間結果集(IntermediateDataSet)組成,其中JobVertex表示了對資料流進行的轉換操作,比如map、flatMap、filter、keyBy等操作,而IntermediateDataSet是由上游的JobVertex所生成,同時作為下游的JobVertex的輸入。
而ExecutionGraph是JobGraph的並行表示,也就是實際JobManager排程一個Job在TaskManager上執行的邏輯檢視,它也是一個DAG圖,是由ExecutionJobVertex、IntermediateResult(或IntermediateResultPartition)組成,ExecutionJobVertex實際對應於JobGraph圖中的JobVertex,只不過在ExecutionJobVertex內部是一種並行表示,由多個並行的ExecutionVertex所組成。另外,這裡還有一個重要的概念,就是Execution,它是一個ExecutionVertex的一次執行Attempt,也就是說,一個ExecutionVertex可能對應多個執行狀態的Execution,比如,一個ExecutionVertex執行產生了一個失敗的Execution,然後還會建立一個新的Execution來執行,這時就對應這個2次執行Attempt。每個Execution通過ExecutionAttemptID來唯一標識,在TaskManager和JobManager之間進行Task狀態的交換都是通過ExecutionAttemptID來實現的。
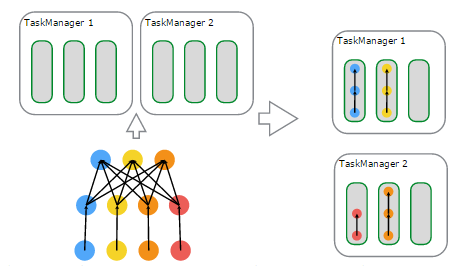
下面看一下,在物理上進行排程,基於資源的分配與使用的一個例子,來自官網,如下圖所示:
說明如下:
- 左上子圖:有2個TaskManager,每個TaskManager有3個Task Slot
- 左下子圖:一個Flink Job,邏輯上包含了1個data source、1個MapFunction、1個ReduceFunction,對應一個JobGraph
- 左下子圖:使用者提交的Flink Job對各個Operator進行的配置——data source的並行度設定為4,MapFunction的並行度也為4,ReduceFunction的並行度為3,在JobManager端對應於ExecutionGraph
- 右上子圖:TaskManager 1上,有2個並行的ExecutionVertex組成的DAG圖,它們各佔用一個Task Slot
- 右下子圖:TaskManager 2上,也有2個並行的ExecutionVertex組成的DAG圖,它們也各佔用一個Task Slot
-
在2個TaskManager上執行的4個Execution是並行執行的
迭代機制 機器學習和圖計算應用,都會使用到迭代計算,Flink通過在迭代Operator中定義Step函式來實現迭代演算法,這種迭代演算法包括Iterate和Delta Iterate兩種型別,在實現上它們反覆地在當前迭代狀態上呼叫Step函式,直到滿足給定的條件才會停止迭代。下面,對Iterate和Delta Iterate兩種型別的迭代演算法原理進行說明:
-
Iterate
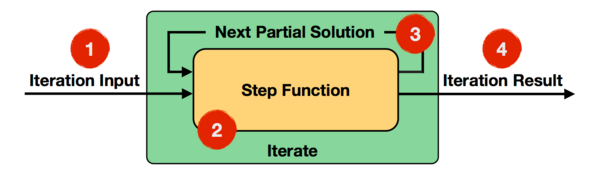
Step函式在每一輪迭代中都會被執行,它可以是由map、reduce、join等Operator組成的資料流。下面通過官網給出的一個例子來說明Iterate Operator,非常簡單直觀,如下圖所示:
上面迭代過程中,輸入資料為1到5的數字,Step函式就是一個簡單的map函式,會對每個輸入的數字進行加1處理,而Next Partial Solution對應於經過map函式處理後的結果,比如第一輪迭代,對輸入的數字1加1後結果為2,對輸入的數字2加1後結果為3,直到對輸入數字5加1後結果為變為6,這些新生成結果數字2~6會作為第二輪迭代的輸入。迭代終止條件為進行10輪迭代,則最終的結果為11~15。
-
Delta Iterate
基於Delta Iterate Operator實現增量迭代,它有2個輸入,其中一個是初始Workset,表示輸入待處理的增量Stream資料,另一個是初始Solution Set,它是經過Stream方向上Operator處理過的結果。第一輪迭代會將Step函式作用在初始Workset上,得到的計算結果Workset作為下一輪迭代的輸入,同時還要增量更新初始Solution Set。如果反覆迭代知道滿足迭代終止條件,最後會根據Solution Set的結果,輸出最終迭代結果。
比如,我們現在已知一個Solution集合中儲存的是,已有的商品分類大類中購買量最多的商品,而Workset輸入的是來自線上實時交易中最新達成購買的商品的人數,經過計算會生成新的商品分類大類中商品購買量最多的結果,如果某些大類中商品購買量突然增長,它需要更新Solution Set中的結果(原來購買量最多的商品,經過增量迭代計算,可能已經不是最多),最後會輸出最終商品分類大類中購買量最多的商品結果集合。更詳細的例子,可以參考官網給出的“Propagate Minimum in Graph”,這裡不再累述。
Backpressure監控 Backpressure在流式計算系統中會比較受到關注,因為在一個Stream上進行處理的多個Operator之間,它們處理速度和方式可能非常不同,所以就存在上游Operator如果處理速度過快,下游Operator處可能機會堆積Stream記錄,嚴重會造成處理延遲或下游Operator負載過重而崩潰(有些系統可能會丟失資料)。因此,對下游Operator處理速度跟不上的情況,如果下游Operator能夠將自己處理狀態傳播給上游Operator,使得上游Operator處理速度慢下來就會緩解上述問題,比如通過告警的方式通知現有流處理系統存在的問題。
Flink Web介面上提供了對執行Job的Backpressure行為的監控,它通過使用Sampling執行緒對正在執行的Task進行堆疊跟蹤取樣來實現,具體實現方式如下圖所示:
JobManager會反覆呼叫一個Job的Task執行所線上程的Thread.getStackTrace(),預設情況下,JobManager會每間隔50ms觸發對一個Job的每個Task依次進行100次堆疊跟蹤呼叫,根據呼叫呼叫結果來確定Backpressure,Flink是通過計算得到一個比值(Radio)來確定當前執行Job的Backpressure狀態。在Web介面上可以看到這個Radio值,它表示在一個內部方法呼叫中阻塞(Stuck)的堆疊跟蹤次數,例如,radio=0.01,表示100次中僅有1次方法呼叫阻塞。Flink目前定義瞭如下Backpressure狀態:
- OK: 0 <= Ratio <= 0.10
- LOW: 0.10 < Ratio <= 0.5
-
HIGH: 0.5 < Ratio <= 1
另外,Flink還提供了3個引數來配置Backpressure監控行為: