
Apache Flink:流處理中Window的概念
Apache Flink–DataStream–Window
什麼是Window?有哪些用途?
下面我們結合一個現實的例子來說明。
我們先提出一個問題:統計經過某紅綠燈的汽車數量之和?
假設在一個紅綠燈處,我們每隔15秒統計一次通過此紅綠燈的汽車數量,如下圖: 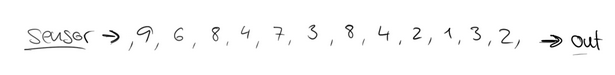
可以把汽車的經過看成一個流,無窮的流,不斷有汽車經過此紅綠燈,因此無法統計總共的汽車數量。但是,我們可以換一種思路,每隔15秒,我們都將與上一次的結果進行sum操作(滑動聚合),如下: 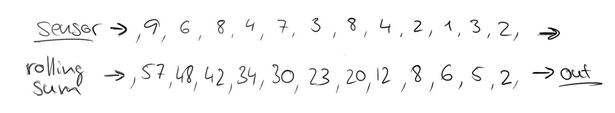
這個結果似乎還是無法回答我們的問題,根本原因在於流是無界的,我們不能限制流,但可以在有一個有界的範圍內處理無界的流資料。
因此,我們需要換一個問題的提法:每分鐘經過某紅綠燈的汽車數量之和?
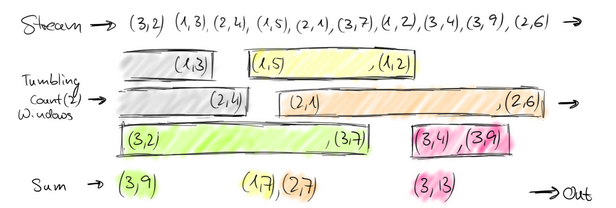
這個問題,就相當於一個定義了一個Window(視窗),window的界限是1分鐘,且每分鐘內的資料互不干擾,因此也可以稱為翻滾(不重合)視窗,如下圖:
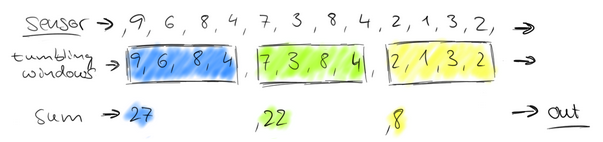
第一分鐘的數量為8,第二分鐘是22,第三分鐘是27。。。這樣,1個小時內會有60個window。
再考慮一種情況,每30秒統計一次過去1分鐘的汽車數量之和: 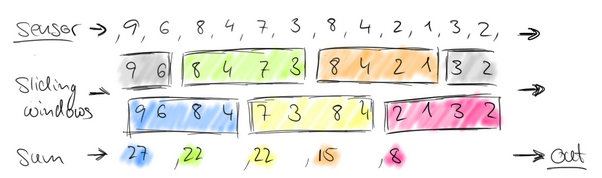
此時,window出現了重合。這樣,1個小時內會有120個window。
擴充套件一下,我們可以在某個地區,收集每一個紅綠燈處汽車經過的數量,然後每個紅綠燈處都做一次基於1分鐘的window統計,即並行處理:
通常來講,Window就是用來對一個無限的流設定一個有限的集合,在有界的資料集上進行操作的一種機制。window又可以分為基於時間(Time-based)的window以及基於數量(Count-based)的window。
Flink DataStream API提供了Time和Count的window,同時增加了基於Session的window。同時,由於某些特殊的需要,DataStream API也提供了定製化的window操作,供使用者自定義window。
下面,主要介紹Time-Based window以及Count-Based window,以及自定義的window操作,Session-Based Window操作將會在後續的文章中講到。
1、Time-Based Window
1.1、Tumbling window(翻滾)
此處的window要在keyed Stream上應用window操作,當輸入1個引數時,代表Tumbling window操作,每分鐘統計一次,此處用scala語言實現:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling time window of 1 minute length
.timeWindow(Time.minutes(1))
// compute sum over carCnt
.sum(1) 1.2、Sliding window(滑動)
當輸入2個引數時,代表滑動視窗,每隔30秒統計過去1分鐘的數量:
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding time window of 1 minute length and 30 secs trigger interval
.timeWindow(Time.minutes(1), Time.seconds(30))
.sum(1)Note:Flink中的Time概念共有3個,即Processing Time(wall clock),Event Time以及Ingestion Time,我會在後續的文章中講到。(國內目前wuchong以及Vinoyang都有講過).
2、Count-Based Window
2.1、Tumbling Window
和Time-Based一樣,Count-based window同樣支援翻滾與滑動視窗,即在Keyed Stream上,統計每100個元素的數量之和:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling count window of 100 elements size
.countWindow(100)
// compute the carCnt sum
.sum(1)2.2、Sliding Window
每10個元素統計過去100個元素的數量之和:
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding count window of 100 elements size and 10 elements trigger interval
.countWindow(100, 10)
.sum(1)3、Advanced Window(自定義window)
自定義的Window需要指定3個function。
3.1、Window Assigner:負責將元素分配到不同的window。
// create windowed stream using a WindowAssigner
var windowed: WindowedStream[IN, KEY, WINDOW] = keyed
.window(myAssigner: WindowAssigner[IN, WINDOW])WindowAPI提供了自定義的WindowAssigner介面,我們可以實現WindowAssigner的public abstract Collection<W> assignWindows(T element, long timestamp)方法。同時,對於基於Count的window而言,預設採用了GlobalWindow的window assigner,例如:
keyValue.window(GlobalWindows.create())3.2、Trigger
Trigger即觸發器,定義何時或什麼情況下Fire一個window。
我們可以複寫一個trigger方法來替換WindowAssigner中的trigger,例如:
// override the default trigger of the WindowAssigner
windowed = windowed
.trigger(myTrigger: Trigger[IN, WINDOW])對於CountWindow,我們可以直接使用已經定義好的Trigger:CountTrigger
trigger(CountTrigger.of(2))3.3、Evictor(可選)
驅逐者,即保留上一window留下的某些元素。
// specify an optional evictor
windowed = windowed
.evictor(myEvictor: Evictor[IN, WINDOW])Note:最簡單的情況,如果業務不是特別複雜,僅僅是基於Time和Count,我們其實可以用系統定義好的WindowAssigner以及Trigger和Evictor來實現不同的組合:
例如:基於Event Time,每5秒內的資料為界,以每秒的滑動視窗速度進行operator操作,但是,當且僅當5秒內的元素數達到100時,才觸發視窗,觸發時保留上個視窗的10個元素。
keyedStream
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(1))
.trigger(CountTrigger.of(100))
.evictor(CountEvictor.of(10));val countWindowWithoutPurge = keyValue.window(GlobalWindows.create()).
trigger(CountTrigger.of(2))最後,給出一個完整的例子,說明Window的用法:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.triggers.{CountTrigger, PurgingTrigger}
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
object Window {
def main(args: Array[String]) {
// set up the execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.socketTextStream("localhost",9000)
val values = source.flatMap(value => value.split("\\s+")).map(value => (value,1))
val keyValue = values.keyBy(0)
// define the count window without purge
val countWindowWithoutPurge = keyValue.window(GlobalWindows.create()).
trigger(CountTrigger.of(2))
val countWindowWithPurge = keyValue.window(GlobalWindows.create()).
trigger(PurgingTrigger.of(CountTrigger.of[GlobalWindow](2)))
countWindowWithoutPurge.sum(1).print()
countWindowWithPurge.sum(1).print()
env.execute()
// execute program
env.execute("Flink Scala API Skeleton")
}
}相關推薦
Apache Flink:流處理中Window的概念
Apache Flink–DataStream–Window 什麼是Window?有哪些用途? 下面我們結合一個現實的例子來說明。 我們先提出一個問題:統計經過某紅綠燈的汽車數量之和? 假設在一個紅綠燈處,我們每隔15秒統計一次通過此紅綠燈的汽車數量,如下圖: 可
【雲星資料---Apache Flink實戰系列(精品版)】:Apache Flink實戰基礎002--flink特性:流處理特性介紹
第二部分:flink的特性 一、流處理特性 1.高吞吐,低延時 有圖有真相,有比較有差距。且看下圖: 1.flink的吞吐量大 2.flink的延時低 3.flink的配置少
Apache Flink:特性、概念、元件棧、架構及原理分析
Apache Flink是一個面向分散式資料流處理和批量資料處理的開源計算平臺,它能夠基於同一個Flink執行時(Flink Runtime),提供支援流處理和批處理兩種型別應用的功能。現有的開源計算方案,會把流處理和批處理作為兩種不同的應用型別,因為他們它們所提供的SLA是完全不相同的:流處理一般需要支
Apache Flink:特性、概念、元件棧、架構及原理分析(全)
Apache Flink是一個面向分散式資料流處理和批量資料處理的開源計算平臺,它能夠基於同一個Flink執行時(Flink Ru
Apache Flink 如何正確處理實時計算場景中的亂序資料
## 一、流式計算的未來 在谷歌發表了 GFS、BigTable、Google MapReduce 三篇論文後,大資料技術真正有了第一次飛躍,Hadoop 生態系統逐漸發展起來。 Hadoop 在處理大批量資料時表現非常好,主要有以下特點: 1、計算開始之前,資料必須提前準備好,然後才可以開始計算; 2
[Essay] Apache Flink:十分可靠,一分不差
pac 資源 模型設計 end AD 抽象 pan 市場 mage Apache Flink:十分可靠,一分不差 Apache Flink 的提出背景 我們先從較高的抽象層次上總結當前數據處理方面主要遇到的數據集類型(types of datasets)以及在處理數據時可供
java8 函數式編程入門官方文檔中文版 java.util.stream 中文版 流處理的相關概念
編寫 被調用 side 執行 style pat 基本類型 ems 容易 前言 本文為java.util.stream 包文檔的譯文 極其個別部分可能為了更好理解,陳述略有改動,與原文幾乎一致 原文可參考在線API文檔 https://docs.oracle.
Flink之流處理基礎
目錄 Chapter 1. Introduction to Stateful Stream Processing Traditional Data Infrastructures Stateful Stream Processing The Evolution of Op
Apache Flink-資料流之上的有狀態的計算
官網給出的Flink應用場景圖: 1.狀態計算。 2.從上圖看出的應用場景有? -----事件驅動式的流處理 -----ETL管道 -----資料分析 3.一般性架構 從架構上來說與一般的流式架構沒有太大的不同,任務排程和資源管理可以放在我們熟悉的yarn上進
使用Apache Flink開始批處理
如果您最近一直在關注軟體開發新聞,那麼您可能聽說過名為Apache Flink的新專案。我已經在這裡和這裡寫了一些內容,但如果您不熟悉它,Apache Flink是新一代大資料處理工具,可以處理有限的資料集(這也稱為批處理)或潛在的無限的資料流(流處理)。在新功能方面,許多人認為Apache Fli
影象處理中的概念總結
本問儘量追求以說人話的方法把所謂的高深概念概括清楚 此篇博文會動態更新 1.Gamma 校正 一句話總結:Gamma 校正其實就是冪指數校正,目的是將灰度較窄的區域拉伸為較寬的區域,如圖,紅框內的輸入區間,對映之後變成了綠框的區間。 2. 直方圖均衡化 一句
java1.8實戰學習(二)——總結:流處理、行為引數化、並行與共享
上一篇:java1.8實戰學習(一) 下一篇:java1.8實戰學習(三) 我們繼續來看 預設方法 在加入所有這些新玩意兒改進Java 的時候, Java 8 設計者發現的一個現實問題就是現有的介面也在改進。比如, Collections.sort方法真的應該屬於Lis
java1.8實戰學習(一)——總結:流處理、行為引數化、並行與共享
筆者這段時間在學習java8的新特性,發現有好多新的特點,特寫此部落格用於梳理記錄學習,不用每次都抱著pdf《java8實戰》去看,也供大家參考 下一篇:java1.8實戰學習(二) 知識點概括 總結了Java的主要變化(Lambda表示式、方法引用、流和預設方法),併為學習後面的內
OpenCV入門:平滑處理 — 中值濾波
平滑處理 — 中值濾波 相關函式: C++: void GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY=0, int borderType=
[零]java8 函數語言程式設計入門官方文件中文版 java.util.stream 中文版 流處理的相關概念
如果行為引數確實有副作用,除非顯式地宣告,否則就無法保證這些副作用對其他執行緒的可見性,也不能保證在同一條管道內的“相同”元素上的不同操作在相同的執行緒中執行。此外,這些影響的排序可能出乎意料。即使管道被限制生成一個與stream源的處理順序一致的結果(例如,IntStream.range(0,5).para
Apache Flink:詳細入門
Apache Flink是一個面向分散式資料流處理和批量資料處理的開源計算平臺,它能夠基於同一個Flink執行時(Flink Runtime),提供支援流處理和批處理兩種型別應用的功能。現有的開源計算方案,會把流處理和批處理作為兩種不同的應用型別,因為他們它們所提供的SL
Spark Streaming、Storm、Flink對比分析,以及為什麼選擇Flink作為流處理框架
隨著大資料技術的不斷髮展和成熟,無論是傳統企業還是網際網路公司都已經不再滿足於離線批處理,實時流處理的需求和重要性日益增長。17年底公司就著力打造實時計算平臺,探索實時流計算引擎和 API,例如這幾年火爆的 Storm、Spark Streaming、Kafka
關於Post請求流處理中的gzip格式的json資料處理
今天遇到一個問題,就是關於遠端服務呼叫返回json資料一致為亂碼的問題,各種常規的處理亂碼的辦法都試了,就是不行,最後看了一篇大神的博文終於得以解決,在這表示感謝! 問題描述: 1、使用URLConnection傳送post請求,請求遠端伺服器中的json資料,一直返回亂
DPDK(10):報文處理中的指令預取(prefetcht0)
在DPDK的例子中報文處理時讀取報文內容時添加了指令預取命令(prefetcht0): /* * Read packet from RX queues */ for (i = 0; i < qconf->n_rx_port; i++) {
Spark流處理中的DStrem.foreachRDD()方法
Spark資料處理 Spark作為分散式資料處理的一個開源框架,因其計算的高效性和簡潔的API而廣受歡迎。一般來說,Spark大部分時候被用來進行批處理。但現在Spark通過其SparkStreaming模組也實現了一定的流處理的功能。 Spark流處理