
阿里雙十一大促,技術準備只做了這兩件事情?
雙十一的技術準備在做兩件事情:第一是系統的準備儘可能的接近真實,包括容量確定性和資源的確定性;第二是整個過程中的效率,包括人和單位資源效率。僅憑這兩件事情,就能撐起這場大促嗎?
本文整理自蔣江偉在ArchSummit 2016 北京站上的演講。
後臺回覆關鍵詞「雙十一」,下載本文完整PPT。
親歷雙十一
從2009年到2016年,參與了8屆雙十一技術備戰工作。2009年的雙十一,印象並不深刻,主要原因是當時整個淘寶的體量已經很大,每天的交易額已經有幾億的規模,而當時的淘寶商城雙十一交易額只有5000萬左右,和幾億比體量還是非常小的,所以感覺還沒開始就過去了。
到了後面幾年,每年都要花費好幾個月的時間去精心準備,要做監控、報警的梳理,要做容量的規劃,要做整個依賴的治理等等,也整理了各種各樣的方法論。這是一個過程,當然在這個過程裡面也沉澱出了很多非常有意義的事情。今天有人問我怎麼做雙十一,怎麼做大促活動,我會告訴他一個非常簡單的方法,就是做好容量規劃,做好限流降級。
2008年,我加入淘寶,直接參與淘寶商城的研發工作。淘寶商城就是後來的天貓,當時整個淘寶商城的技術體系,和淘寶網是完全不一樣的,是完全獨立的體系。它的會員、商品、營銷、推薦、積分、論壇,都和淘寶網沒有任何的關係。兩套體系是完全獨立的,唯一有關係的是整個會員的資料是共享的。
2008年末啟動了「五彩石專案」,把兩套體系的資料打通、業務打通,最核心的點就是業務的發展變得非常靈活。這個專案的完成給淘寶商城的發展帶來非常大的飛躍,後來淘寶商城也升級品牌為天貓。
另外,這個專案裡還有一個很大的意義,就是比較優雅的實現了架構的擴充套件性、業務的擴充套件性和技術的擴充套件性。我們實現了整個服務的全部服務化,抽取了所有與電商相關的公共元素,包括會員體系、商品中心、交易中心、營銷、店鋪、推薦等。基於這個體系,構建後來像聚划算、電器城、航旅等的業務就非常快了。打破原來的架構,將整個公共的服務抽取出來之後,上層的業務跑得非常快,這就解決了業務擴充套件性的問題。
第一次大規模使用中介軟體是在這個專案裡,中介軟體3劍客,HSF、Notify、TDDL得到了很大的創新沉澱,並被大規模的使用。分散式帶來的問題是一個系統被拆成了很多的系統,這其中也涉及到了擴充套件性的問題。這個專案也帶來了技術的進步,從業務的發展到技術的擴充套件性,都達成了非常好的目標。
為什麼要做容量規劃?
2012年,我開始帶中介軟體產品線和高可用架構的團隊。那麼為什麼要做容量規劃呢?雙十一推動了阿里巴巴技術上非常大的創新,容量規劃也是雙十一在這個過程中非常好的創新。
今年做雙十一的時候,老闆問我今年還有什麼風險?我告訴他風險肯定很多,但是最終如果系統出問題了,肯定發生在交易相關的系統裡。阿里巴巴的系統分兩部分:一部分系統是促進交易的,比如推薦、導購、搜尋、頻道等都是促進交易的,會做各種各樣的營銷;另外一部分系統做交易、紅包、優惠等相關係統。
原因非常簡單,導購類的系統留給你足夠的時間去做判斷,它流量的上漲不是瞬間上漲,而是一個曲線慢慢上升,它留給你30分鐘做出判斷。但是交易系統沒有留出任何時間判斷,一旦流量開始,沒有給人反應時間,沒有任何決策的時間,所有的行為只有系統會自動化執行。這個過程裡面容量規劃變的非常重要。
在早些年的時候,我們業務的自然增長本身就非常快。印象非常深刻的是,當時大家購物的時候開啟的商品詳情頁面,有一段時間這個頁面的負載比較高,公司召集了一些對於虛擬機器調優、效能優化比較擅長的人來進行優化,調優了幾天之後系統終於掛掉了。還好也在做一些擴容的準備,擴容完成,重啟之後系統恢復了。這說明了什麼?在早些年的時候,淘寶網也是一樣,對容量的準備和預估是沒有概念的,不知道多少容量能支撐整個系統需要的能力。
新業務不斷地上線,業務運營、促銷類的活動也非常頻繁,記得有一次做一個促銷規模非常大。會員系統非常重要,因為所有的業務基本上都會訪問會員中心使用者的資料,包括買家的資料還有賣家的資料。那時物理機單機快取的能力大概在每秒處理八萬請求的規模,今天來看是遠遠不止。但當時還沒有到高峰期的時候就達到了六萬,這是非常大的一個數字。
我們就把所有訪問會員的系統全部拉出來,看哪些與交易無關就通知需要停掉,或者停掉一半。比如把與商家相關的,與開放相關的,與社群相關的系統停掉。在這個過程裡面發生了各種各樣的問題,總結來說就是我們根本不知道容量怎麼去做,或者說根本就沒有概念需要去做容量。所以容量規劃歸根結底就是:在什麼時候什麼樣的系統需要多少伺服器?需要給出有確定性,量化的數字。
容量規劃的三個階段
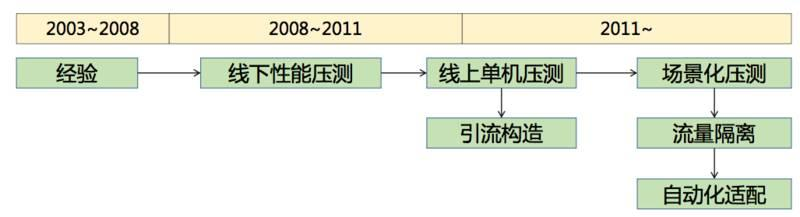
容量規劃整個過程大概經歷了七八年的時間,總共三個階段。
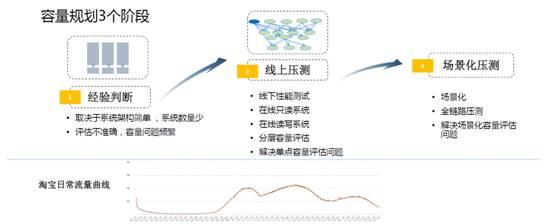
第一個階段在非常早期,我們評估的方法就是「拍腦袋」(經驗判斷)。根據負載的情況、系統的響應時間,各種各樣的表現去拍一個數字出來。當時我問一個高管,到底怎麼去判斷伺服器夠還是不夠,要支撐多少流量?他告訴我一個經驗值,每臺伺服器支援100萬的PV。
當時一天的流量曲線會有三個峰值,九點到十點,中午兩、三點到五點,晚上八點到十點之間都是峰值。為什麼是100萬呢?這也是一個經驗值,當然也有一點科學根據。我們希望做到一半的伺服器停下來後能夠去支撐線上的流量,同時在峰值的情況下,全部能夠支撐住。實際上單機能支撐320萬的PV,這是當時的經驗值。
當然這個經驗值當時是起作用的,原因非常簡單,因為當時的系統架構簡單。可以理解為把整個淘寶所有的邏輯和模組都集中在一個系統裡面,所以各個模組之間的熱點有時間差,通過一臺伺服器內部CPU的搶佔或者排程在OS層面就解決了。
到了第二個階段是線上壓測階段。因為一旦到了分散式之後,就會出現問題。舉個例子,本來是會員的呼叫和交易的呼叫在一臺伺服器上,但是分開之後,流量比例就不清楚了。所以必須要引入一些壓測機制,我們引入一些商業的壓測工具來做壓測。
當時有兩個目的:第一個是系統上線之前要做壓測,判斷響應時間、負載能否達到上線的要求;第二個目的是希望能夠根據線下的壓測情況,準確地評估出線上大概需要多少伺服器。第二個目的做起來就比較困難一些,記得當時效能壓測團隊還做了一個專案,叫線下線上容量之間的關係。因為線上的環境和資料與線下完全不一樣,這裡面沒有規律可尋,沒辦法通過線下壓測的指標反饋到線上去。
這時候怎麼辦?首先是直接在線上壓測。當時來看我們做這個決定是非常瘋狂的,因為沒有一家公司,包括阿里巴巴自己也沒有人在線上直接做過壓測。我們寫了一個工具,拉取出前一天的日誌直接在線上做回放。比如,根據響應時間和負載設定一個的預值,達到預值觸發的時候看它QPS的多少值。
其次我們做了一個分流。因為阿里整個架構還是比較統一的,全部是基於一整套的中介軟體,所以通過軟負載,通過調整配比,比如把線上的流量按照權重調整到一臺伺服器上,通過調整到應用端和服務端不斷地調整到一臺伺服器上去,增加其權重,這時候它的負載也會上升,QPS也會上升,把這個過程記錄下來。
這裡已經是兩種場景了,一種是模擬,回放日誌。第二種是真實的流量,把做成自動化讓它每天自動跑產生資料。這個事情做完之後,它從一個維度來說,替代了線下效能壓測的過程。因為它可以讓每個系統每天自己獲得性能的表現情況。專案釋出,或是日常需求的釋出的效能有沒有影響的指標都可以直接看出來。後來效能測試團隊就解散了。
這裡有個問題,它還沒有基於場景化。場景化非常重要,比如我買一件衣服,平時買東西的流程可能是在購物的搜尋框裡面搜尋,或者是在類目的導航裡搜尋,從搜尋到購物車,再到下單這樣的一個過程。雙十一推的是商品的確定性,很多頻道頁面會把賣家比較好的促銷商品直接拿出來作為一個頻道頁。雙十二的時候推的是店鋪,KPI不一樣,推的東西也不一樣。
雙十一商品相關的伺服器系統的流量會高,它所需要的伺服器也會更多一些。雙十二和店鋪相關的系統伺服器所需要也會更多一些。這與平時的流量表現是不一樣的,用平時的容量去計算場景化流量,這也是不準確的。
我們也做了一件非常重要的事情:全鏈路壓測。這是我們在2013年完成的事情,之前從沒有對外講過,這是一個核武器,它有個分界線。2009年是最順利的一次雙十一,因為沒有什麼流量,我們忽略不計。2010年、2011年、2012年,其實每年的雙十一總是有那麼一些小問題,其實心裡也沒底。
在2013年的時候,我們做了全鏈路壓測這個產品之後,發生了一個本質的變化。2013年的表現非常好,2014年也非常好,這就是一個核武器的誕生。對於做營銷和促銷類的,它是有峰值的,在這個時間點之前峰值非常低,這個時間點之後峰值突然上去了。這就是處理這種情況非常有效的一種方法。
從線下到線上:單機壓測的容量評估
重點分析一下線上壓測和場景化的全鏈路壓測。
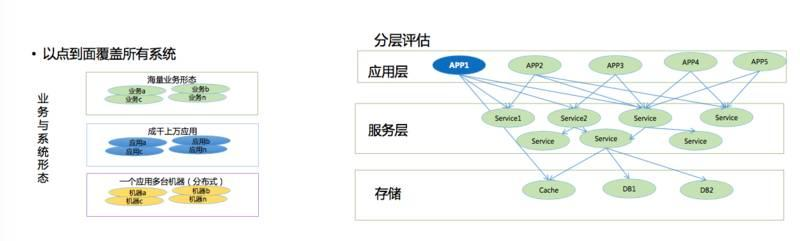
線上壓測主要是由於淘寶的業務形態多樣化。分散式之後各種各樣的業務都出現了,它幫助解放了生產力。以前一百多個人在做一個系統,非常糟糕,但是通過分散式改造之後,整個業務服務抽象出來之後,生產力被解放了。
其次,每個業務的機器規模非常大,每個業務應用數量非常大。我們其實是做了一個分層,根據一個系統具備的容量不斷計算,最後計算出來阿里巴巴的叢集容量。我們先做一個應用系統,通過分流,流量通過負載匯入,把負載跑到最高之後計算。把這個APP整個叢集,比如100臺伺服器能支撐多少量計算出來。當然資料庫非常難算,資料庫都是提前規劃的,一般來說資料庫分庫分表之後,都是留了好幾年的量,比較困難一些。
通過這樣把整個叢集的量和規模全部做出來是有問題的,為什麼呢?因為系統一旦開始拆分之後一發而不可收拾,拆得越來越多。系統的依賴關係雖然是有工具能夠梳理出來的,但是我們沒有經歷看到底哪些系統會因為這個場景下面什麼原因導致整個叢集出現了一個小問題。一旦出現了一個小問題,整個叢集全部崩潰掉,這種問題是沒法避免的。
在2013年之前都是基於這套體系去做,想想也是挺合理的,每個系統算出容量,一個個叢集算出來,再算出整個大叢集也是可以的,但是它還不是一個非常好的解決方案。它非常好的一點是可以自動化執行,可以每天跑出系統的容量,並且可以保證系統不腐化,日常的效能、指標不腐化。
壓測平臺的架構
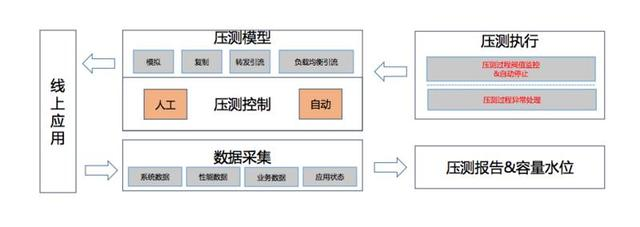
2013年的雙十一是通過這套系統做的。通過幾種方式,通過模擬以及流量的複製,轉發的引流,還有負載均衡的流量去實現。整個系統做成自動化,每週都會跑,根據釋出前後的一天跑出來資料之後生成一個報表反饋效能有沒有下降可以得出。根據計算值準備整個活動流量大概要多少。這裡有一些資料,每個月有5天自動做壓測,這種情況下靠人工做效能壓測是做不到的,因為它是自動化的。
剛才也講了一些缺陷,它是以點到面,通過一個點的容量評估,擴充套件到一條線,擴充套件到一個面。最大的問題是沒有一個人搞得清楚整個架構到底怎麼樣,整個系統依賴關係裡有遺漏之後會形成整體的崩潰。

為什麼要做場景化的容量評估?
我們需要場景化壓測的另外一個原因是因為整個背景的流量大部分用的是分流,分流意味著是用真實的流量去做的,所謂真實的流量其實是很低的,和做活動相比流量非常低,沒有背景流量整個機房的網路裝置和交換機的流量無法跑滿,所以這些問題是沒辦法暴露出來的。第二個問題是場景化的確定性,每個人購物流程是不一樣的,在不同的流程下面整個系統的資源必須確定下來,要用最少的伺服器支撐最大的量。
基於此,當時有一套爭論,要怎麼做場景化壓測這個事情?第一種方法,把整個淘寶網隔離出一個小的環境裡面布100多個系統。整個流量引進來,把叢集跑滿,流量跑滿。它比較好地解決了依賴關係的問題,如果依賴出現問題的時候,在這個環境是能夠驗證的。但是沒辦法解決環境的問題,那一年我們公司有一個業務,就是因為沒有采用這套方案,採用了類似於小環境的流量去驗證的方案,導致入口交換機的整個流量跑滿。
場景化容量評估
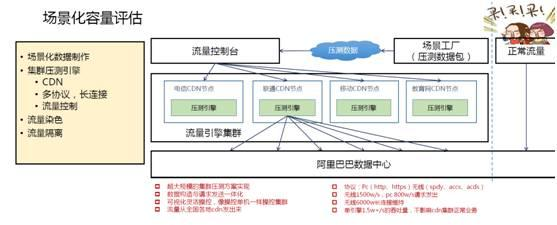
所以需要有一個更簡單可靠的評估工具,這就是基於場景化的全鏈路壓測。2013年之後我們全部基於這套體系在做,首先要造資料,流量希望能夠更接近真實的情況造出來。剛才提到臨近峰值是沒辦法做決策的,唯一能做的是什麼?能夠提前模擬一次零點的峰值是什麼樣子的嗎?我們希望把整個流量模擬出來,這是一個理想的架構,但是它也有很多困難的地方。
我們要儘可能把資料造得精確,各種場景都要模擬出來,比如優惠券如何使用,購物車裡商品比例是多少,一次下單有多少商品,最後多少商品提交到支付寶等等。資料量每年越來越大,比如以2015年為例,資料量接近1T,把這1T的資料傳到中心,通過中心傳到壓測節點上去,這就是壓測叢集。它是一個壓測工具,但是它本身又是一個叢集性的壓測工具,它可以產生非常巨大的流量,與雙11一模一樣規模的資料。
把叢集部署到CDN節點上,產生巨大的流量。這裡有一些技術點,壓測的工具要支援多種協議,比如HTTPS協議,需要提升效能。還要做流量的控制,根據業務場景的不同調節流量。第三點流量需要染色,右圖反映了真實的流量,這些全部是線上跑的,沒辦法線上下模擬這個環境,否則會影響線上正常的流量,所以要把正常的流量和壓測的流量完全區分開來。第四點是流量的隔離。沒有流量隔離之前,我們只能在零點以後流量很低的時候,每個人都盯著自己的系統有沒有出現什麼問題,非常辛苦。第二年提了一個目標,希望能改善大家的幸福指數,所以我們推出了流量隔離。
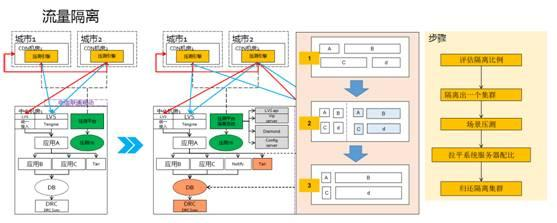
流量隔離是把整個叢集從原來線上的叢集,比較快地通過負載均衡隔離出一個叢集出來。當然隔離出的叢集規模是非常大的,它可以佔原來叢集的從90%到10%。比如原來有10萬臺伺服器,可以隔離到9萬臺伺服器。因為準備做大促的時候,比如雙十一的流量是平時的20倍以上,所以平時流量非常低是可以隔離出來的,並且不會影響現有的流量。
整個過程是怎麼樣的?以圖為例,ABCD這4個系統是日常的流量,原始的場景C所需要的伺服器多,但是壓測之後發現B和D需要的伺服器比較多。整個過程都是自動化的,如果C不需要這麼多伺服器,它的伺服器就會被下線,這些伺服器就被自動加到B和D。由於都是自動化跑,效率非常高,而且不需要到凌晨跑。最後需要把隔離出來的叢集還到原來線上的叢集,變成伺服器的比例,就可以準備第二天的大考了。
流量評估的流程
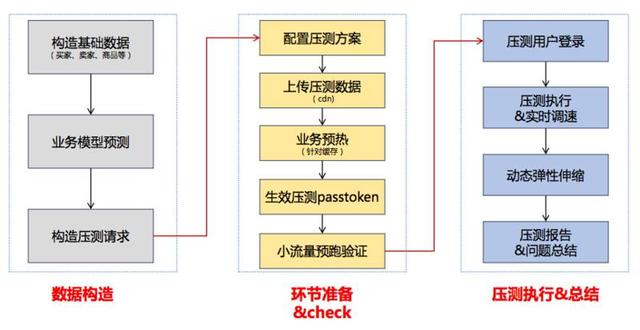
整個容量評估的流程,從資料構造到流量環節,我們都有一個指揮部。比如我們要做一次活動,這次活動大概要5萬筆每秒的交易量,輸入5萬筆每秒這個數字之後,整套系統開始運作,做壓測、做彈性排程、做隔離,這就是整個自動化的過程。容量是可以預測的,但是沒辦法規劃,只能做限流。我們可以非常精確地預測出雙十一大概會來多少量,會來多少使用者,以及當時的峰值,都可以完全精確預測出來。
但預測出來也沒有太多的意義,能做的就是限流筆數,比如2016年我們做到了17.5萬筆,限流的值設定到了17.2萬,所有的系統先設定到這個值。這也是沒辦法的,因為真實的流量比這個大得多,要支援真實的流量成本會非常高。
日常佔有的伺服器是非常低的,在大促的時候我們基本上都採用阿里雲的伺服器,所以成本下降明顯。所以說整個容量規劃限定了一個值,比如說17萬,明年可能是20萬,或者25萬,在這個值的基礎上,通過基於場景化的全鏈路壓測工具,然後把整個系統的容量壓測出來,計算出來,把整個伺服器資源佔用拉平。這樣做的好處是用了最少的資源做了一次最成功的活動。
場景化容量評估的表現

從2013年開始,我們通過這套技術發現了大量的問題,而且這些問題經過日常的測試,功能測試,或者一些工具的測試,是沒辦法發現這些問題。硬體、網路、作業系統的問題,從來沒有發現的問題全部暴露出來,在大負載情況下表現出各種詭異的問題。
任何一個問題在雙十一發生,可能都是災難性的。2013年我們做完這些事情之後,回頭看2012年、2011年,不出問題還怪,肯定會出問題。凡是峰值流量是平時峰值超過多少倍以上的活動肯定會出問題,因為很多的問題沒辦法通過一些邏輯,通過一些思考找出來的,它必須藉助一個真實的環境,模擬出所有場景的流量把它營造出來。
容量評估的總結
容量規劃是一個領域、一個長時間的過程。最初利用商業軟體做效能壓測,當時覺得這個軟體應用挺好的,也能夠支撐整個容量的一些計算,甚至今天很多的公司還在用類似的軟體做效能的評估,它也是不斷引進的過程。後來發現,其實與真實壓測評估的容量還相差非常遠,所以我們引入了線上的壓測,引入了分流、複製流量、及日誌的回放,通過一個個節點把自己的流量評估出來。
當時覺得這套系統很厲害,因為當時做了這套系統獲得了整個技術部的創新大獎,所以覺得有了這套系統以後,以後做雙十一就不用愁了,做任何活動就不用愁了,覺得這是非常了不起的系統。實際情況還是需要不斷地發展,做了全鏈路壓測,整個鏈路基於場景化的真實場景模擬,把整個叢集壓測出來。
回過頭來看,在一個領域裡面,當自己滿足於當前現狀的時候,比如說CSP“日常的壓測平臺”能夠完全滿足於當前現狀,而且已經領先於國內很多產品的時候,其實你還是可以繼續往前走一步。
我們只是做了雙十一創新裡容量規劃這個點。阿里巴巴整個技術架構非常統一,因為做了全鏈路壓測之後,很多的業務單元,像支付寶等等都可以採用這種方式做,它可以非常簡單地複製出去,這也給我們帶來了非常低的成本。從研發開始到學習,以及運維的過程,運維的產品線,帶給了我們非常低的成本。所以我們整個團隊人非常少,做全線路壓測就4、5個人,但是它服務了整個集團100多個業務方,這也是因為整個架構的統一性。
今年雙十一做完了之後,我們的CTO也給我們提出了新的挑戰:雙十一的整個過程可以投入更少的成本,全鏈路壓測是對日常系統的一種驗證,而不是找問題本身,同時希望我們的系統更加的自動化和智慧化。我們正在思考如何實現。