
讀書筆記10:Non-local Neural Networks
摘要中,作者開門見山,強調卷積神經網路和迴圈神經網路的操作都是局域化的操作,在本文中,我們提出非局域化的操作(non-local operation),作為抓取長程相互關係的一個一般性的模組(a generic family of building bolcks for capturing long-range dependenices)。也即第一句話給出問題的背景,第二句話概述自己的方法。之後便是進一步更加具體的對自己的方法進行介紹:受到計算機視覺經典的非局域化方法(classical non-local means means method)的啟發,我們的非局域化方法在計算某一個位置的響應的時候,是通過對所有位置的特徵進行加權求和得到的。這個模組可以被插入到很多計算機視覺的框架中。在視訊分類的任務中,即使沒有什麼修飾,non-local模型也能在Kinetics和Charades資料集上取得和現有方法相當或者更勝一籌的結果;在靜態圖片的識別任務中,我們的non-local模型在COCO資料集上提升了物體檢測/分割和姿態估計的表現。後面這一部分,首先用一句話將演算法的核心描述出來了,然後從應用的角度對演算法進行分析,能夠插入到計算機視覺的任務中、在什麼什麼任務上,在什麼什麼資料集上,模型的表現如何等等,都是模型的應用方面的描述。總結:第一句背景介紹,然後由淺入深簡介模型,最後介紹模型的應用,構成了本文的摘要。
introduction第一段介紹了long-range dependencies是深度神經網路的核心內容,CNN通過堆疊網路增加receptive field實現目的,RNN通過recurrent operation(指的應該是上一hidden state的傳入)來實現。第二段介紹了這些方法的侷限性,具體說到:convolutional和recurrent操作都是對一個local neighborhood進行處理,CNN對空間上的local neighborhood,RNN是對時間上的咯local neighborhood進行操作,這種局域化的操作導致想獲得long-range dependencies就要對神經網路進行層層堆疊,但這種層層堆疊會帶來一些相應的侷限性包括降低計算效率、造成優化的困難、以及資訊不能方便的在兩個相距較遠的位置之間來回的傳播。第三段介紹自己的模型,和abstract中的介紹類似,還是先說模型的一些特點:我們提出一個non-local operation,它是抓取long-range dependencies的高效的、簡單的、一般性的元件。然後一句話是介紹是什麼啟發了作者提出這個模型:我們的模型是計算機視覺中經典的non-local mean operation的推廣。之後是簡單的描述演算法是如何操作的:每個位置的計算都是對所有位置特徵的加權求和,位置是分佈在時間維度上,可以是分佈在空間維度上,也可以是同時分佈在時空兩個維度上,這使得本文提出的模型既可以應用在圖片、序列,也可以應用在視訊上。第四段進一步介紹non-local operation的好處:不論兩個位置相距多遠,模型都能直接抓取他們之間的dependencies;non-local operation更高效,只需幾層網路就可以達到最好的效果;可以處理不同尺寸的輸入,也可以和其他操作例如卷積相結合。第五段從實驗的角度進一步介紹模型,介紹說自己的模型在視訊分類任務上體現出了優越性,單獨的non-local block就能抓取視訊序列中的長程dependencies,多個blocks就能在精度上超越CNN,在兩個資料集上還做了ablation study,最後提到本文的模型只需要使用RGB資料而不需要optical flow或者multi-scale testing等修飾手段就能和這兩個資料集上最好的模型打成平手或者超過他們。最後一段介紹了用object detection/segmentation和pose estimation任務來檢驗模型的結果,最後一句話強調本文模型的有效性。總結來說,introduction部分的思路是這樣的:首先介紹處理我們關注的問題(long-range dependencies)的背景現狀,第二段介紹這些手段的侷限性,第三段簡介自己的模型,第四段指出模型的優勢,五六段結合實驗結果進一步強調模型的優勢。
related work介紹了六個相關的方向。non-local image processing:non-local means也是通過計算所有畫素的加權求和得到卷積結果的演算法,距離較遠的畫素可以基於patch appearance similarity來產生貢獻。這個想法後來被髮展出BM3D(block-matching 3D),這個演算法即使和深度網路相比,都是很好的影象去噪的工具。Graphical model:這部分提到了conditional random field這種graphical model,這一部分沒太看懂,應該是對graphical model知之甚少,可以去看一看相關內容。Feed-forward modeling for sequences:最近出現的通過很深的1D卷積網路來處理語言序列的模型,這些feedforward模型適用於平行計算,並且可以比常用的recurrent models更加高效。self-attention:本文的模型和這個密切相關,self-attention是對序列使用的,在序列的每一個位置計算相響應(response)的時候都是通過所有位置的加權求和得到的。Interaction networks:一開始是為了模擬物理系統提出來的,也就是處理由一些存在相互作用的物體構成的graph,它的變體還有relation networks。Video classification architectures:主要強調了使用3D卷積核來處理視訊的模型。
接下來是技術部分,技術部分的思路是先給一個一般性的定義,再給具體的例子(比如指定函式具體形式等等具體化)。non-local operation的形式化定義很簡單直接:
輸出y和輸入x是相同尺寸的,i和j都是標記位置的,可以表示輸入或輸出的任何一個位置,x是輸入,C(x)是一個標準化因子,f的輸出是一個標量,表示位置i和位置j之間的關係,例如密切程度或者別的什麼衡量兩者關係的量。g是一個unary function(輸入只有一個值),它是用來計算輸入訊號在位置j的一個表示的,也就是對位置j原始的資料進行了一個處理,可能是線性對映或者別的什麼。由於j是遍歷輸入的所有位置,也就是所有位置的訊號都參與加權求和,因此是non-local的操作。與此相對,RNN一般是計算當前位置和時間維度上前一個位置的訊號,CNN是卷積核覆蓋區域的訊號。non-local operation和全連線也是不一樣的,因為全連線在加權所有資訊的時候用的權重不是基於兩兩之間的關係的,而是直接學習的權重,此外,fc layer需要固定尺寸的輸入,non-local layer不需要。作者在這強調道,這種non-local層可以和CNN或RNN結合起來,non-local層可以用在深度網路的前面幾層(和fc相反),這樣能夠同時抓取non-local和local資訊,能建立更豐富的結構(放在前面是不是因為深度網路前面幾層receptive field還不夠大,不能抓取長程資訊,所以在這加non-local,而後面幾層已經有大的receptive field了,就不是那麼需要non-local層了?但是應該也不是一點用沒有?畢竟前面說到non-local能使資訊方便的在相距較遠的兩個位置間傳遞,深度網路就算receptive field大,也不能做到這麼方便的傳遞)
接下來具體介紹幾種函式g和f的選取,但是作者一開始就說,non-local模型對這些函式的選擇並不敏感,說明模型的行為主要是由non-local的操作導致的,而不是具體函式決定的。為了簡化,g只取做線性函式,若是空間二維的情況,這就相當於1x1的一個卷積,若是時空三維的情況,就是1x1x1的卷積,接下來就只是考慮函式f的選擇了。
第一個選擇是高斯函式,此時
。將高斯函式延伸一下就是embedded Gaussian函式
,意思是先embed,再應用高斯函式,
、
。為了證明模型的行為和softmax函式的行為沒有太大的關係,第三種函式設計為簡單的dot product
,此時
,由於輸入的尺寸不固定,因此normalization項是必須的。第四種函式是連線(concatenation),
,這裡[]是連線在一起的標記,
是將連線在一起的vector對映到一個標量的矩陣,這時也是
。
為了能夠將non-local operation新增到各種不同現存的模型中,單獨定義了non-local block為這裡面yi是
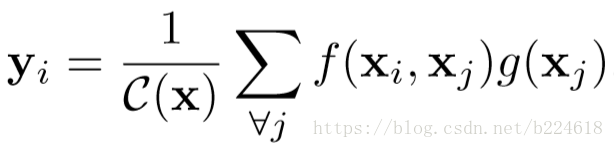
,這樣可以在預訓練好的模型上加入non-local機制而不影響原來的模型的行為,因為如果
全都初始化為0的話,那麼就相當於沒有加上這一項。non-local block示意圖如下
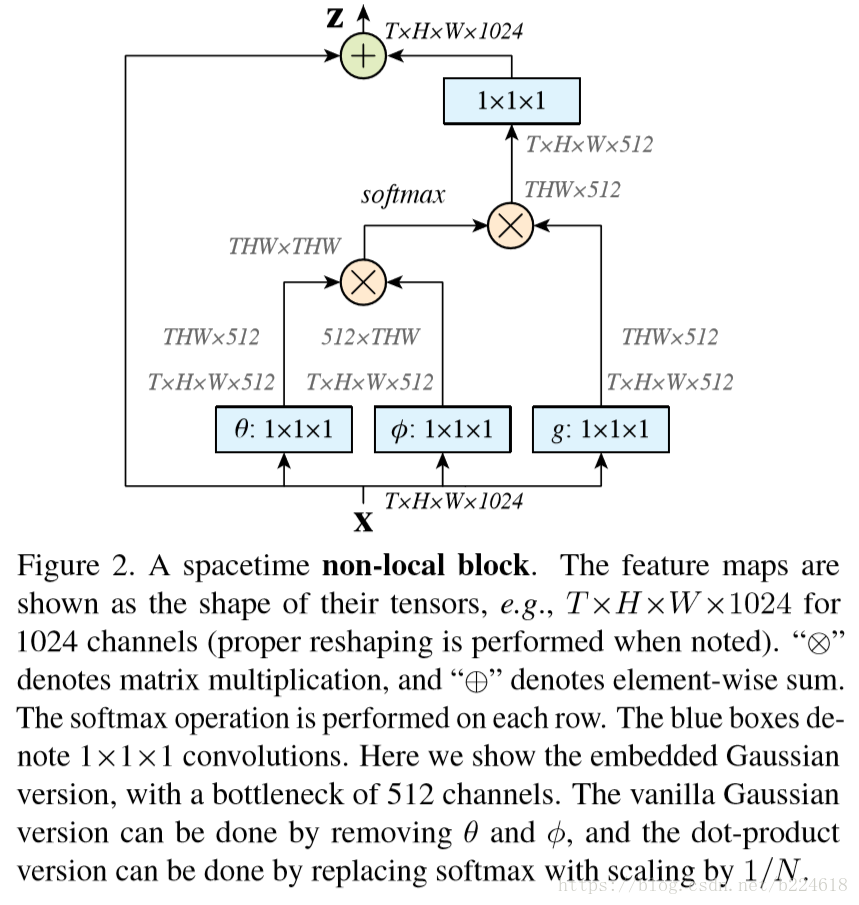
圖中有一個細節,就是在進行non-local項計算的時候,首先用將輸入的channel數變為一半,然後進行計算,最後輸出的時候再用矩陣embedding回原來的channel數,這是為了節約計算資源而設計的bottleneck設計。此外為了進一步節約計算資源,還可以在計算non-local項的時候進行一下subsampling(例如pooling),然後再進行加權求和,減少參與計算的位置數量。本文將在所有的non-local block中使用這些提高計算效率的方法。
之後的一個部分作者介紹瞭如何利用non-local block搭建video classification model。一共有兩個基準模型,一個是C2D模型,這個是為了分離出non-local網路的temporal effect,在C2D模型中,時間維度上只進行pooling操作,也就是隻是簡單的加和,沒有複雜的操作。另一個是inflated 3D convnet(I3D)模型,這是將2D的k×k的kernel在時間維度上延展t幀。最終non-local net就是在這兩個基準模型上加入non-local block。
整個技術部分的結構大概是這樣的:首先給出模型的一般性描述,然後給出幾個模型的具體化的instantiation,然後介紹了在具體的視訊分類的任務上,模型是怎麼設計的,總體來看是一個由一般到具體的過程。
最後就是實驗部分了,整體分兩個部分,第一部分是對視訊資料分類,第二部分是對靜態的圖片的處理。在視訊分類的部分,作者進行了十分詳細的ablation study,對比了non-local block數目,C2D vs I3D,時間空間維度對比等等。還討論了在什麼階段加入non-local block比較合適。對靜態圖片分類的處理,作者進行了物體識別,例項分割和關鍵點檢測的任務。