
【論文閱讀】Non-local Neural Networks
Non-local Neural Networks
Non-local Neural Networks是何凱明大佬組最近發表的一篇文章。一作Xiaolong Wang,本科畢業於華南農業大學,研究生是中山大學,博士去了CMU,然後做出了這麼好的工作,可以說非常勵志了。
類似於Batch Normalization,這篇文章也提出了一種不改變輸入輸出大小的層,可以直接整合到現有的網路結構中。思想非常簡單,卻在各大資料集上都取得了良好的效果。
簡介
捕捉大範圍內資料相互之間的依賴關係是一個很重要的問題。對於序列化的資料,比如語音、視訊等等,使用迴圈神經網路一直是比較主流的做法。對於圖片來說,我們通常使用較大的卷積核來捕捉較遠距離的畫素之間的關係。
然而,迴圈神經網路或者傳統的卷積神經網路都只是在其時間或空間的很小的鄰域內進行捕捉,卻很難捕獲到更遠的位置的資料的依賴關係。
這篇論文中,作者提出了一種Non-local層,可以很好地捕捉到較遠位置的畫素點之間的依賴關係。Non-local mean其實是一種傳統計算機視覺方法。作者將其擴充套件到了神經網路中。

上圖是該層訓練後的一個效果圖。箭頭指向的點就是演算法認為和箭尾的點關聯度最高的一些點。可以看出,對於視訊分類任務,人物的動作、球的位置等點的資訊之間是有依賴關係的,而這種依賴關係被Non-local層很好的捕捉到了。
演算法簡介
Non-local的思想十分簡單。以一個視訊片段為例,假設我們要考慮的某一個幀中的某一個點為
這裡的 可以看作是兩點之間的關聯絡數, 可以看作是 點中包含的資訊。即以 為權重,將資訊 進行加權求和。 為其歸一化係數。
到這裡已經介紹完了Non-local的最重要的思想。接下來就是確定 和 的形式了。文章中列舉了幾種不同的 。
例項
可以直接用一個線性函式來編碼,即
實現時只要應用 卷積核就可以解決。關鍵是 的形式。下面列舉幾種。
| 函式 | 表示式 |
|---|---|
| Gaussian | |
| Embedded Gaussian | |
| Dot product | |
| Concatenation |
不過論文也指出,最終的結果對於
的選擇並不敏感。
None-local塊的實現
res的結構是一定要有的,所以在之前的
算出來以後,我們最終的輸出要滿足:
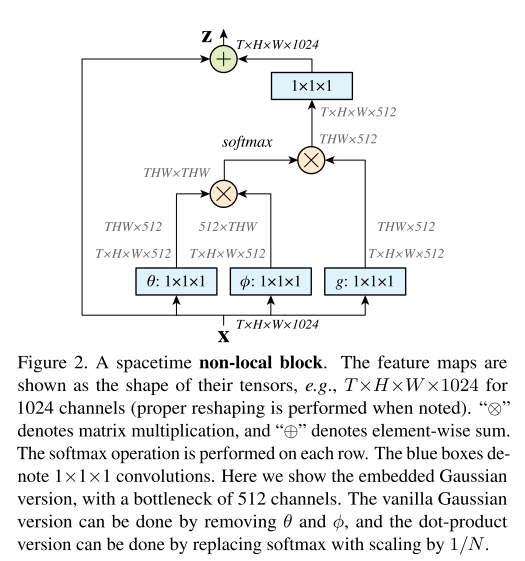
所以Non-local層的結構如圖2所示。
實現時,通道數先減半最後再還原,遵從了bottleneck的設計思想,降低了一半的計算量。同時, 可以被降取樣後的資料 代替,從而進一步降低計算量。
視訊分類模型
作者在介紹視訊分類實驗介紹之前,先介紹了視訊分類的常用方法。由於我對這塊兒不太熟悉,所以這部分內容也記錄下來。
2D卷積基準(2D ConvNet baseline)
這個網路是個鹹魚網路。因為要比較Non-local和I3D中時間序列的表現,所以構建這樣一個基準網路。時間資訊僅僅通過pooling來使用。
膨脹3D卷積(Inflated 3D ConvNet)
這裡的膨脹指的是把卷積層膨脹成為3D的。使用2D卷積層初始化,然後再將每層縮放 。
要注意的是,3D卷積是非常消耗計算資源的,因此每隔兩個res層才會使用一次3D卷積。提出I3D的人表示他們的方法要比CNN+LSTM方法好。
Non-local network
在C2D和I3D中加入Non-local塊。

實現細節
網路現在imagenet上訓練,然後使用視訊微調。
首先是資料,從視訊中取樣連續的64幀,再從這64幀中間隔取32幀作為資料集;空域上隨機從[256,320]上擷取一塊224X224大小的區域。訓練時,每個GPU上放8段視訊,一次用8塊GPU,也就是說一個minibatch是64個clips(再次說明了多卡的重要性)。然後就是常規設定了,迭代40萬次。(抱歉,有卡真的是可以為所欲為的)
值得注意的是他們在微調網路時激活了BN層,而ResNet訓練時BN是關閉的。因為他們使用BN減少了過擬合。
在Non-local layer中,只有在最後一個1X1X1層的後面使用了BN,並且將BN的初始化引數設為0,從而保證網路的初始行為和預訓練的網路一樣。
inference時,從一個視訊裡取10段分別做前向,再將結果做softmax後再取平均。
在視訊分類上的實驗

使用了Kinetics資料集和Charades資料集。
Kinetics資料集上的實驗
Kinetics dataset包含了246K個訓練視訊和20k個驗證視訊,包含400種人的常見行為。
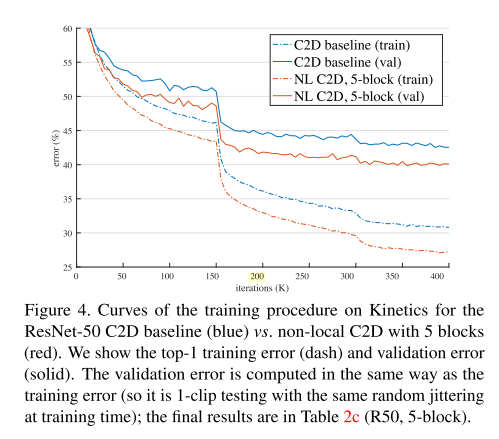
圖4說明加入NL之後的模型在整個訓練過程中都力壓沒加過的。
圖1和圖3說明模型學到了很多有意義的關聯點。
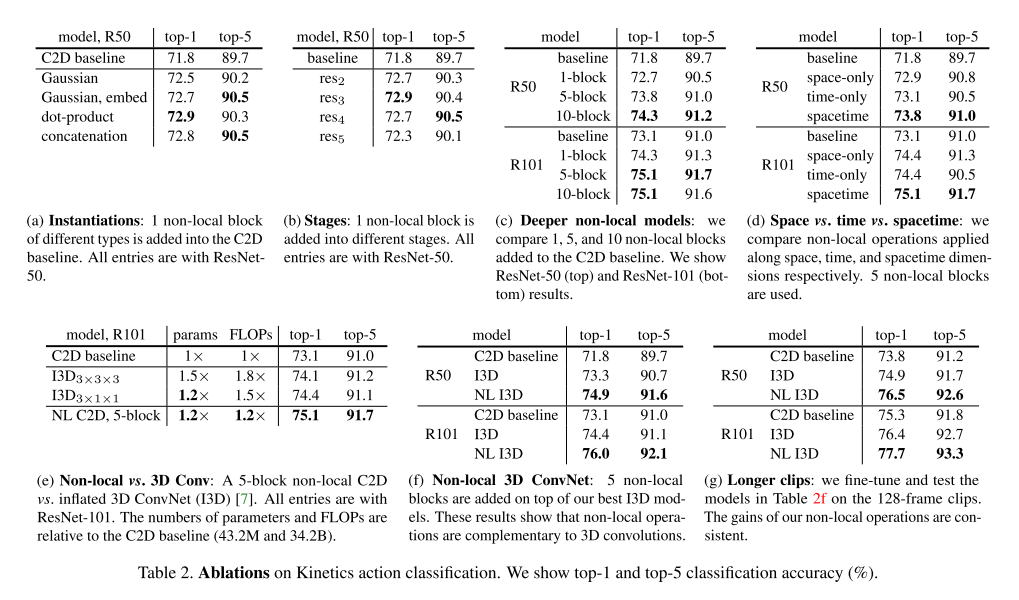
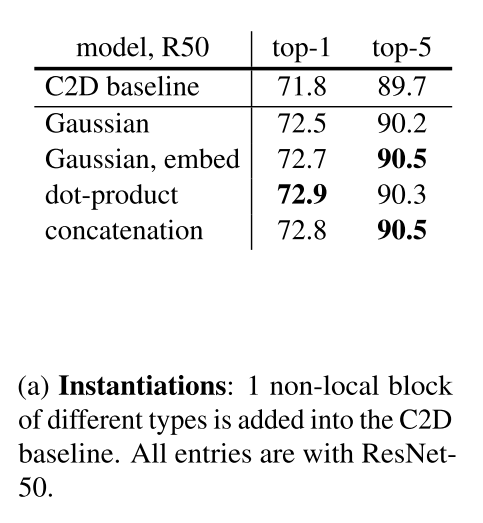
表2的資訊量有點大。。。
表2a對比了不同的 對結果的影響。不管怎麼選,只加一層Non-local都可以提高1個點。同時表格說明不同的 對結果影響不大。因此,接下來的實驗都選擇了Gaussian,因為他們的輸出落在0~1之間,便於視覺化。
表2b比較了在不同的位置新增Non-local層的影響。在res234新增的效果差不多,但在res5新增會有降低。一種可能的解釋是越往後圖越小,空間資訊就越不明顯。
表2c比較了不同數量的Non-local的影響。越多越準。值得注意的是,五層Nonlocal的ResNet-50比ResNet100還要準,但引數數量和計算量都比ResNet100小,因此其效果的提升並不是僅僅通過加深網路實現的。另外,作者還嘗試把Non-local換成普通的Res層,結果精度並沒有提高,說明Non-Local的確是增強了網路的能力。
表2d比較了Non-local用在時間、空間、時空上的結果。雖然都有提高,但是在時空上最好。
表2e比較了加了Non-local的C2D和I3D的效果。這兩種操作可以看成是將C2D擴充套件到時間維度的不同方法。可以看出Non-local使用的計算力和引數都更小,卻取得了更高的精度。
表2f比較了加了Non-local的I3D和I3D的