
Non-local Neural Networks 原理詳解及自注意力機制思考
Author:Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He (CMU, FAIR)
1 創新點
這篇文章非常重要,個人認為應該算是cv領域裡面的自注意力機制的核心文章,語義分割裡面引入的各種自注意力機制其實都可以認為是本文的特殊化例子。分析本文的意義不僅僅是熟悉本文,而是瞭解其泛化思想。
不管是cv還是NLP任務,都需要捕獲長範圍依賴。在時序任務中,RNN操作是一種主要的捕獲長範圍依賴手段,而在CNN中是通過堆疊多個卷積模組來形成大感受野。目前的卷積和迴圈運算元都是在空間和時間上的區域性操作,長範圍依賴捕獲是通過重複堆疊,並且反向傳播得到,存在3個不足:
(1) 捕獲長範圍依賴的效率太低;
(2) 由於網路很深,需要小心的設計模組和梯度;
(3) 當需要在比較遠位置之間來回傳遞訊息時,這是區域性操作是困難的.
故作者基於圖片濾波領域的非區域性均值濾波操作思想,提出了一個泛化、簡單、可直接嵌入到當前網路的非區域性操作運算元,可以捕獲時間(一維時序訊號)、空間(圖片)和時空(視訊序列)的長範圍依賴。這樣設計的好處是:
(1) 相比較於不斷堆疊卷積和RNN運算元,非區域性操作直接計算兩個位置(可以是時間位置、空間位置和時空位置)之間的關係即可快速捕獲長範圍依賴,但是會忽略其歐式距離,這種計算方法其實就是求自相關矩陣,只不過是泛化的自相關矩陣
(2) 非區域性操作計算效率很高,要達到同等效果,只需要更少的堆疊層
(3) 非區域性操作可以保證輸入尺度和輸出尺度不變,這種設計可以很容易嵌入到目前的網路架構中。
2 核心思想
由於我主要做2d圖片的CV需求,故本文的大部分分析都是針對圖片而言,而不是時間序列或者視訊序列。
本文的非區域性操作運算元是基於非區域性均值操作而提出的,故很有必要解釋下非區域性均值操作。我們在CNN或者傳統圖片濾波運算元中涉及的都是區域性操作,例如Sobel運算元,均值濾波運算元等等,其計算示意圖如下:
 圖片來源:吳恩達深度學習課程
圖片來源:吳恩達深度學習課程
可以看出每個位置的輸出值都是kernel和輸入的區域性卷積計算得到的,而非區域性均值濾波操作是: computes a weighted mean of all pixels in an image,非常簡單。核心思想是在計算每個畫素位置輸出時候,不再只和鄰域計算,而是和影象中所有位置計算相關性,然後將相關性作為一個權重表徵其他位置和當前待計算位置的相似度。可以簡單認為採用了一個和原圖一樣大的kernel進行卷積計算。下圖表示了高斯濾波,雙邊濾波和非區域性均值處理過程:

可以看出對於待計算的中心紅色點,前兩種區域性操作都是在鄰域計算,而非區域性均值是和整個圖片進行計算的。但是實際上如果採用逐點計算方式,不僅計算速度非常慢,而且抗干擾能力不太好,故非區域性均值操作是採用Block的思想,計算block和block之間的相關性。

可以看出,待計算的畫素位置是p,故先構造block,然後計算其他位置block和當前block的相關性,可以看出q1和q2區域和q非常相似,故計算時候給予一個大權重,而q3給予一個小的權重。這樣的做法可以突出共性(關心的區域),消除差異(通常是噪聲)。
 上圖可以看出非區域性操作的優點,每一個例子中左圖是待計算畫素點的位置,右圖是基於NL均值操作計算出來的權重分佈圖,看(c)可以非常明顯看出,由於待計算點位置是在邊緣處,通過非區域性操作後突出了全部邊緣。
上圖可以看出非區域性操作的優點,每一個例子中左圖是待計算畫素點的位置,右圖是基於NL均值操作計算出來的權重分佈圖,看(c)可以非常明顯看出,由於待計算點位置是在邊緣處,通過非區域性操作後突出了全部邊緣。
上面的所有分析都是基於非區域性操作來講的,但是實際上在深度學習時代,可以歸為自注意力機制Self-attention。在機器翻譯中,自我注意模組通過關注所有位置並在嵌入空間中取其加權平均值來計算序列(例如,句子)中的位置處的響應,在CV中那就是通過關注圖片中(可以是特徵圖)所有位置並在嵌入空間中取其加權平均值來表示圖片中某位置處的響應。嵌入空間可以認為是一個更抽象的圖片空間表達,目的是匯聚更多的資訊,提高計算效率。聽起來非常高階的樣子,到後面可以看出,是非常簡單的。
3 網路結構
下面開始給出非區域性操作的具體公式。首先在深度學習中非區域性操作可以表達為:

i是輸出特徵圖的其中一個位置,通用來說這個位置可以是時間、空間和時空。j是所有可能位置的索引,x是輸入訊號,可以是影象、序列和視訊,通常是特徵圖。y是和x尺度一樣的輸出圖,f是配對計算函式,計算第i個位置和其他所有位置的相關性,g是一元輸入函式,目的是進行資訊變換,C(x)是歸一化函式,保證變換前後整體資訊不變。以上是一個非常泛化的公式,具體細節見下面。在區域性卷積運算元中,一般的

由於f和g都是通式,故結合神經網路特定,需要考慮其具體形式。
首先g由於是一元輸出,比較簡單,我可以採用1x1卷積,代表線性嵌入,其形式為:

對於f,前面我們說過其實就是計算兩個位置的相關性,那麼第一個非常自然的函式是Gaussian。
(1) Gaussian

對兩個位置進行點乘,然後通過指數對映,放大差異。
(2) Embedded Gaussian

前面的gaussian形式是直接在當前空間計算,而(2)更加通用,在嵌入空間中計算高斯距離。這裡:


前面兩個:

仔細觀察,如果把C(x)考慮進去,那麼

其實就是softmax形式,完整考慮是:

這個就是目前常用的位置注意力機制的表示式,所以說語義分割中大部分通道注意力機制都是本文的特殊化。
(3) Dot product
考慮一種最簡單的非區域性操作形式:

其中C(x)=N,畫素個數。可以看出(2) (3)的主要區別是是否含有啟用函式softmax。
(4) Concatenation
參考 Relation Networks可以提出:

前面是基本的非區域性操作運算元,利用這些運算元,下面開始構造成模組。

可以看出,上面構造成了殘差形式。上面的做法的好處是可以隨意嵌入到任何一個預訓練好的網路中,因為只要設定W_z初始化為0,那麼就沒有任何影響,然後在遷移學習中學習新的權重。這樣就不會因為引入了新的模組而導致預訓練權重無法使用。
下面結合具體例項分析:

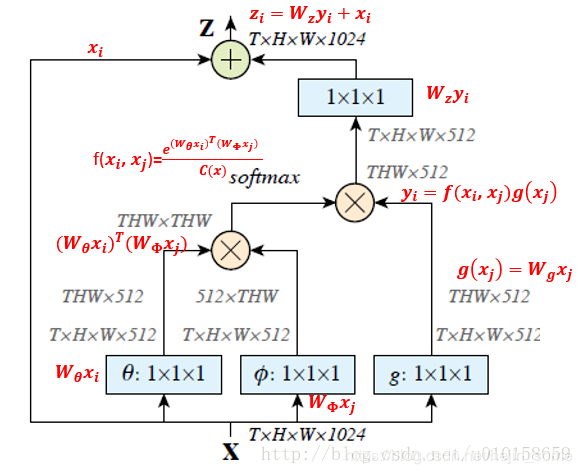
由於我們考慮的是圖片,故可以直接設定T=1,或者說不存在。首先網路輸入是X= (batch, h, w, 1024) ,經過Embedded Gaussian中的兩個嵌入權重變換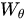 ,
, 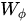 得到(batch, h, w, 512), (batch, h, w, 512), 其實這裡的目的是降低通道數,減少計算量;然後分別對這兩個輸出進行reshape操作,變成(batch, hw, 512),後對這兩個輸出進行矩陣乘(其中一個要轉置),計算相似性,得到(batch, hw, hw),
得到(batch, h, w, 512), (batch, h, w, 512), 其實這裡的目的是降低通道數,減少計算量;然後分別對這兩個輸出進行reshape操作,變成(batch, hw, 512),後對這兩個輸出進行矩陣乘(其中一個要轉置),計算相似性,得到(batch, hw, hw),
然後在第2個維度即最後一個維度上進行softmax操作,得到(batch, hw, hw), 意這樣做就是通道注意力,相當於找到了當前圖片或特徵圖中每個畫素與其他所有位置畫素的歸一化相關性;然後將g也採用一樣的操作,先通道降維,然後reshape;然後和 (batch, hw, hw)進行矩陣乘,得到(batch, h, w, 512), 即將通道注意力機制應用到了所有通道的每張特徵圖對應位置上,本質就是輸出的每個位置值都是其他所有位置的加權平均值,通過softmax操作可以進一步突出共性。最後經過一個1x1卷積恢復輸出通道,保證輸入輸出尺度完全相同。
4 核心程式碼實現

拷貝的程式碼來源:https://github.com/AlexHex7/Non-local_pytorch
可以看出,具體實現非常簡單,就不細說了。
5 擴充套件
通讀全文,你會發現思路非常清晰,模組也非常簡單。其背後的思想其實是自注意力機制的泛化表達,準確來說本文只提到了位置注意力機制(要計算位置和位置之間的相關性,辦法非常多)。
個人認為:如果這些自注意模組的計算開銷優化的很小,那麼應該會成為CNN的基礎模組。既然位置和位置直接的相關性那麼重要,那我是不是可以認為graph CNN才是未來?因為圖卷積網路是基於畫素點和畫素點之間建模,兩者之間的權重是學習到的,效能肯定比這種自監督方式更好,後面我會寫文章分析。
本文設計的模組依然存在以下的不足:
(1) 只涉及到了位置注意力模組,而沒有涉及常用的通道注意力機制
(2) 可以看出如果特徵圖較大,那麼兩個(batch,hxw,512)矩陣乘是非常耗記憶體和計算量的,也就是說當輸入特徵圖很大存在效率底下問題,雖然有其他辦法解決例如縮放尺度,但是這樣會損失資訊,不是最佳處理辦法。
6 實驗
Non-local Blocks的高效策略。我們設定Wg,Wθ,Wϕ的channel的數目為x的channel數目的一半,這樣就形成了一個bottleneck,能夠減少一半的計算量。Wz再重新放大到x的channel數目,保證輸入輸出維度一致。
還有一個subsampling的trick可以進一步使用,就是將(1)式變為:yi=1C(x^)∑∀jf(xi,x^j)g(x^j),其中x^是x下采樣得到的(比如通過pooling),我們將這個方式在空間域上使用,可以減小1/4的pairwise function的計算量。這個trick並不會改變non-local的行為,而是使計算更加稀疏了。這個可以通過在圖2中的ϕ和g後面增加一個max pooling層實現。
我們在本文中的所有non-local模組中都使用了上述的高效策略。
6.1. 視訊分類模型
為了理解non-local networks的操作,我們在視訊分類任務上進行了一系列的ablation experiments。
2D ConvNet baseline (C2D)。為了獨立開non-local nets中時間維度的影響vs 3D ConvNets,我們構造了一個簡單的2D baseline結構。
Table 1給出了ResNet-50 C2D backbone。輸入的video clip是32幀,大小為224*224。Table 1中的所有卷積都是用的2D的kernel,即逐幀對輸入視訊進行計算。唯一和temporal有關的計算就是pooling,也就是說這個baseline模型簡單地在時間維度上做了一個聚合的操作。 
Inflated 3D ConvNet (I3D)。 Table 1中的C2D模型可以通過inflate的操作轉換成一個3D卷積的結構。具體地,一個2D k*k大小的kernel可以inflate成3D t*k*k大小的kernel,只要將其權重重複t次,再縮小t倍即可。
我們討論2種inflate的方式。一種是將residual block中的3*3的kernel inflate成3*3*3的,另一種是將residual block中的1*1的kernel inflate成3*1*1的。這兩種形式我們分別用I3D3∗3∗3和I3D3∗1∗1表示。因為3D conv的計算量很大,我們只對每2個residual blocks中的1個kernel做inflate。對更多的kernel做inflate發現效果反而變差了。另外conv1層我們inflate成5*7*7。
Non-local network。 我們將non-local block插入到C2D或I3D中,就得到了non-local nets。我們研究了插入1,5,10個non-local blocks的情況,實現細節將在後面給出。
6.2 Non-local Network實現細節
Training。 我們的模型是在ImageNet上pretrain的,沒有特殊說明的話我們使用32幀的輸入。32幀是通過從原始長度的視訊中隨機選擇1個位置取出64個連續幀,然後每隔1幀取1幀得到的最終的32幀。spatial size是224*224大小,是將原始視訊rescale到短邊為[256,320]區間的隨機值,然後再random crop 224*224大小。我們在8卡GPU上進行訓練,每卡上有8 clips(也就是說總的batchsize是64 clips)。我們一共迭代了400k iterations,初始lr為0.01,然後每150k iterations lr下降1/10。momentum設為0.9,weight decay設為0.0001。dropout在global pooling層後面使用,dropout ratio設為0.5。
我們finetune模型的時候 BN是開啟的,這和常見的finetune ResNet的操作不同,它們通常是frozen BN。我們發現在我們的實驗中enable BN有利於減少過擬合。
在最後一個1*1*1 conv層(表示Wz)的後面我們加了一個BN層,其他位置我們沒有增加BN。這個BN層的scale引數初始化為0,這是為了保證整個non-local block的初始狀態相當於一個identity mapping,這樣插入到任何預訓練網路中在一開始都能保持其原來的表現。
Inference。 推理時,在我們將視訊rescale到短邊256進行推理。時域上我們從整個視訊中平均取樣10個clip,然後分別計算他們的softmax scores,最後做平均得到整個視訊的score。
6.3 實驗
關於視訊分類的實驗,我們在Kinetics上進行全面的實驗,另外也給出了Charades上的實驗結果,顯示出我們的模型的泛化性。這裡只給出Kinetics上的結果,更多的請看原文。
Table 2給出了ablation results。 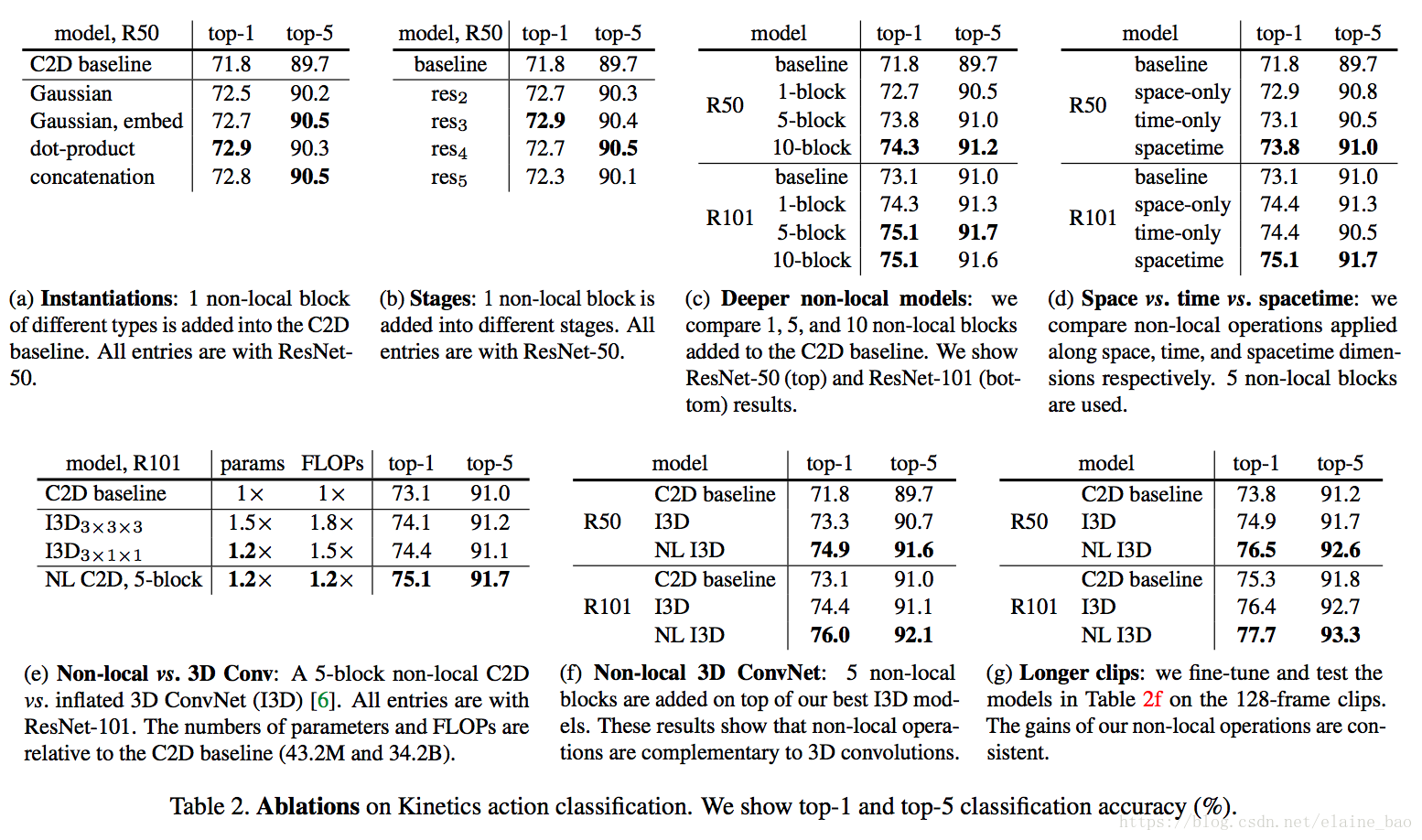
f的表現形式的影響。表2a比較了不同的non-local block的形式插入到C2D得到的結果(插入位置在res4的最後一個residual block之前)。發現即使只加一個non-local block都能得到~1%的提高。
有意思的是不同的non-local block的形式效果差不多,說明是non-local block的結構在起作用,而對具體的表達方式不敏感。本文後面都採用embedded Gaussian進行實驗,因為這個版本有softmax,可以直接給出[0,1]之間的scores。
哪個階段加入non-local blocks?表2b比較了一個non-local block加在resnet的不同stage的效果,具體加在不同stage的最後一個residual block之前。發現在res2,res3,res4層上加non-local block效果類似,加在res5上效果稍差。這個的可能原因是res5的spatial size比較小,只有7*7,可能無法提供精確的spatial資訊了。
加入更多的non-local blocks。表2c給出了加入更多non-local block的結果,我們在resnet-50上加1 block(在res4),加5 block(3個在res4,2個在res3,每隔1個residual block加1個non-local block),加10 block(在res3和res4每個residual block都加non-local block)。在resnet101的相同位置加block。發現更多non-local block通常有更好的結果。我們認為這是因為更多的non-local block能夠捕獲長距離多次轉接的依賴。資訊可以在時空域上距離較遠的位置上進行來回傳遞,這是通過local models無法實現的。
另外需要提到的是增加non-local block得到的效能提升並不只是因為它給base model增加了深度。為了說明這一點,表2c中resnet50 5blocks能夠達到73.8的acc,而resnet101 baseline是73.1,同時resnet50 5block只有resnet101的約70%的引數量和80%的FLOPs。說明non-local block得到的效能提升並不只是因為它增加了深度。
時空域上做non-local。我們的方法也可以處理時空域的資訊,這一特性非常好,在視訊中相關的物體可能出現在較遠的空間和較長的時間,它們的相關性也可以被我們的模型捕獲。表2d給出了在時間維度,空間維度和時空維度分別做non-local的結果。僅在空間維度上做就相當於non-local的依賴僅在單幀影象內部發生,也就是說在式(1)上僅對index i的相同幀的index j做累加。僅在時間維度上做也類似。表2d顯示只做時間維度或者只做空間維度的non-local,都比C2D baseline要好,但是沒有同時做時空維度的效果好。
Non-local net vs. 3D ConvNet。表2e比較了我們的non-local C2D版本和inflated 3D ConvNets的效能。Non-local的操作和3D conv的操作可以看成是將C2D推廣到時間維度的兩種方式。
表2e也比較了param的數量,FLOPs等。我們的non-local C2D模型比I3D更加精確(75.1 vs 74.4),並且有更小的FLOPs(1.2x vs 1.5x)。說明單獨使用時non-local比3D conv更高效。
Non-local 3D ConvNet. 不管上面的比較,其實non-local操作和3D conv各有各的優點:3D conv可以對區域性依賴進行建模。表2f給出了在I3D3∗1∗1上插入5個non-local blocks的結果。發現NL I3D都能夠在I3D的基礎上提升1.6個點的acc,說明了non-local和3D conv是可以相互補充的。
更長的輸入序列。 最後我們也實驗了更長輸入序列的情況下模型的泛化性。輸入clip包含128幀連續幀,沒有做下采樣,是一般情況下取的32幀的4倍長度。為了將這個模型放入視訊記憶體中,每個GPU上只能放下2 clips。因為這麼小的batchsize的原因,我們freeze所有的BN層。我們從32幀訓練得到的模型作為初始化模型,然後用128幀進行finetune,使用相同的iterations數目(雖然batchsize減小了),初始lr為0.0025,其他設定和之前保持一致。
表2g給出了128幀的實驗結果,和表2f的32幀的結果相比,所有模型都表現得更好,說明我們的模型在長序列上的效果也很好。
和state-of-the-art的比較。表3給出了Kinetics上各個方法的結果。 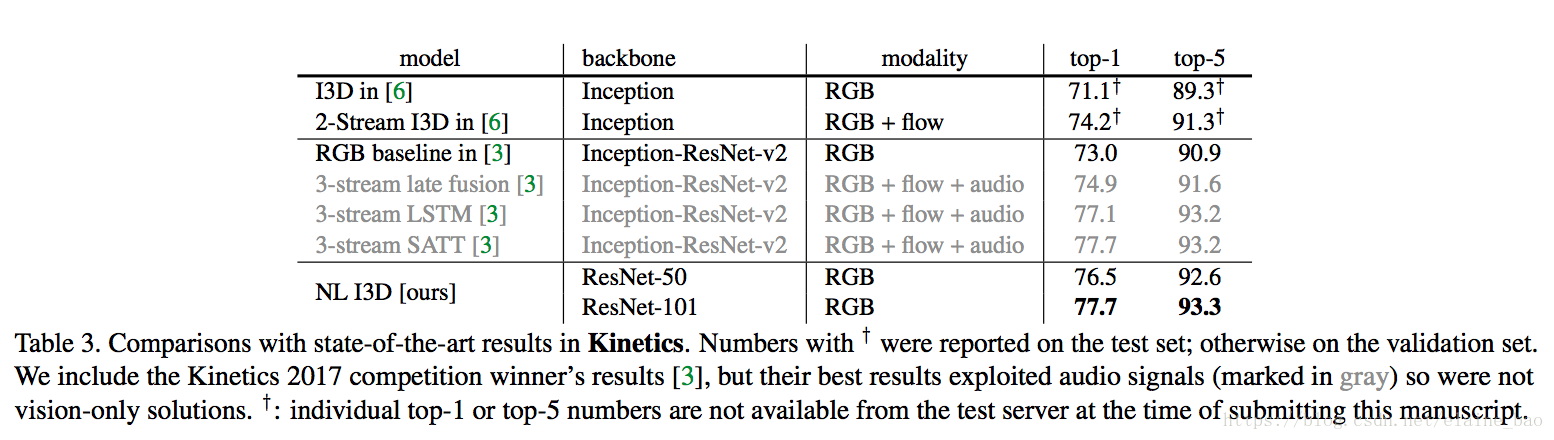
來源: https://blog.csdn.net/elaine_bao/article/details/80821306
https://www.jianshu.com/p/a9771abedf50
https://blog.csdn.net/u010158659/article/details/78635219
&nbs