
深度學習目標檢測模型全面綜述:Faster R-CNN、R-FCN和SSD
選自medium
機器之心編輯部
Faster R-CNN、R-FCN 和 SSD 是三種目前最優且應用最廣泛的目標檢測模型,其他流行的模型通常與這三者類似。本文介紹了深度學習目標檢測的三種常見模型:Faster R-CNN、R-FCN 和 SSD。

圖為機器之心小編家的邊牧「Oslo」被 YOLO 識別為貓
隨著自動駕駛汽車、智慧監控攝像頭、面部識別以及大量對人有價值的應用出現,快速、精準的目標檢測系統市場也日益蓬勃。這些系統除了可以對影象中的每個目標進行識別、分類以外,它們還可以通過在該目標周圍繪製適當大小的邊界框(bounding box)來對其進行定位。這讓目標檢測技術較傳統計算機視覺處理技術——影象分類而言,難度上升了不少。
然而,幸運的是,目前最成功的目標檢測方法是對影象分類模型的擴充套件。幾個月前,Google 為 Tensorflow 釋出了一個新的目標檢測 API。與其同時釋出的還有針對一些特定模型預構建的框架和權重。
-
基於 MobileNets 框架的 Single Shot Multibox Detector(SSD)模型。
-
基於 Inception V2 框架的 SSD 模型。
-
使用 ResNet-101 框架的基於 Region 的全卷積網路(R-FCN)模型。
-
基於 ResNet-101 框架的 Faster RCNN 模型。
-
基於 Inception ResNet v2 的 Faster RCNN 模型。
在以前的文章中,機器之心曾梳理了 Xception、Inception 和 ResNet 等基本網路的架構和背後的設計思路。在本文中,我們會對 Tensorflow 的目標檢測模型 Faster R-CNN、R-FCN 以及 SSD 做同樣的介紹。希望在結束本文的閱讀之後,你可以瞭解到以下兩點:
1、深度學習是如何在目標檢測中得到應用的。
2、這些目標檢測模型的設計是如何在相互之間獲得靈感的同時也有各自的特點。
FASTER R-CNN 模型
Faster R-CNN 模型現在是一個典型的基於深度學習的目標檢測模型。在它的啟發下,出現了很多目標檢測與分割模型,比如本文中我們將會看到的另外兩個模型。然而,要真正開始瞭解 Faster R-CNN 我們需要理解其之前的 R-CNN 和 Fast R-CNN。所以,現在我們快速介紹一下 Faster R-CNN 的來龍去脈。
R-CNN 模型
如果要擬人化比喻,那 R-CNN 肯定是 Faster R-CNN 的祖父了。換句話說,R-CNN 是一切的開端。
R-CNN,或稱 Region-based Convolutional Neural Network,其工作包含了三個步驟:
-
藉助一個可以生成約 2000 個 region proposal 的「選擇性搜尋」(Selective Search)演算法,R-CNN 可以對輸入影象進行掃描,來獲取可能出現的目標。
-
在每個 region proposal 上都執行一個卷積神經網路(CNN)。
-
將每個 CNN 的輸出都輸入進:a)一個支援向量機(SVM),以對上述區域進行分類。b)一個線性迴歸器,以收縮目標周圍的邊界框,前提是這樣的目標存在。
下圖具體描繪了上述 3 個步驟:
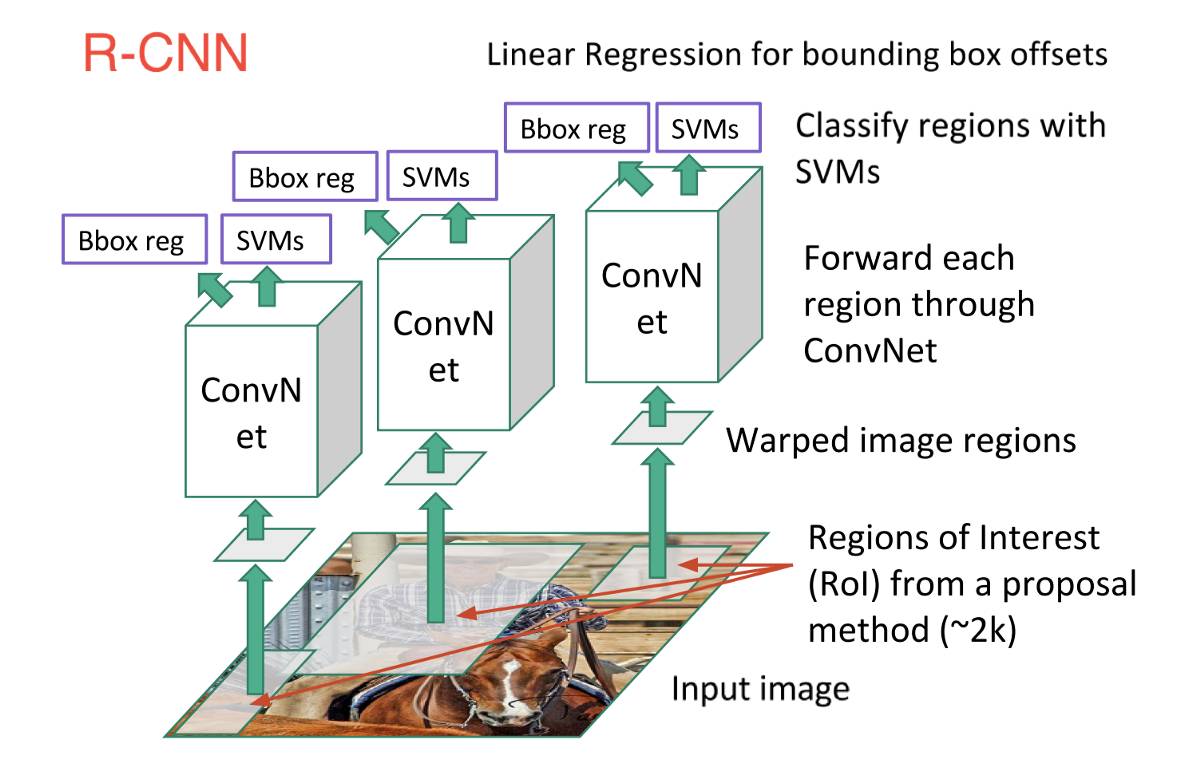
換句話說,首先,我們給出一些建議區域,然後,從中提取出特徵,之後,再根據這些特徵來對這些區域進行分類。本質而言,我們將目標檢測轉化成了影象分類問題。R-CNN 模型雖然非常直觀,但是速度很慢。
Fast R-CNN
直接承接 R-CNN 的是 Fast R-CNN。Fast R-CNN 在很多方面與 R-CNN 類似,但是,憑藉兩項主要的增強手段,其檢測速度較 R-CNN 有所提高:
-
在推薦區域之前,先對影象執行特徵提取工作,通過這種辦法,後面只用對整個影象使用一個 CNN(之前的 R-CNN 網路需要在 2000 個重疊的區域上分別執行 2000 個 CNN)。
-
將支援向量機替換成了一個 softmax 層,這種變化並沒有建立新的模型,而是將神經網路進行了擴充套件以用於預測工作。
Fast R-CNN 模型結構示意圖:

如圖所見,現在我們基於網路最後的特徵圖(而非原始影象)建立了 region proposals。因此,我們對整幅圖只用訓練一個 CNN 就可以了。
此外,我們使用了一個 softmax 層來直接輸出類(class)的概率,而不是像之前一樣訓練很多不同的 SVM 去對每個目標類(object class)進行分類。現在,我們只用訓練一個神經網路,而之前我們需要訓練一個神經網路以及很多 SVM。
就速度而言,Fast R-CNN 提升了許多。
然而,存在一大未解決的瓶頸:用於生成 region proposal 的選擇搜尋演算法(selective search algorithm)。
FASTER R-CNN
到現在為止,我們完成了對 Faster R-CNN 兩大早期模型的溯源。下面我們開始研究 Faster R-CNN。Faster R-CNN 的主要創新是,它用一個快速神經網路代替了之前慢速的選擇搜尋演算法(selective search algorithm)。具體而言,它引入了一個 region proposal 網路(RPN)。
RPN 工作原理:
-
在最後卷積得到的特徵圖上,使用一個 3x3 的視窗在特徵圖上滑動,然後將其對映到一個更低的維度上(如 256 維),
-
在每個滑動視窗的位置上,RPN 都可以基於 k 個固定比例的 anchor box(預設的邊界框)生成多個可能的區域。
-
每個 region proposal 都由兩部分組成:a)該區域的 objectness 分數。b)4 個表徵該區域邊界框的座標。
換句話說,我們會觀察我們最後特徵圖上的每個位置,然後關注圍繞它的 k 個不同的 anchor box:一個高的框、一個寬的框、一個大的框等等。對於每個這些框,不管我們是否認為它包含一個目標,以及不管這個框裡的座標是什麼,我們都會進行輸出。下圖展示了在單個滑動框位置上發生的操作:
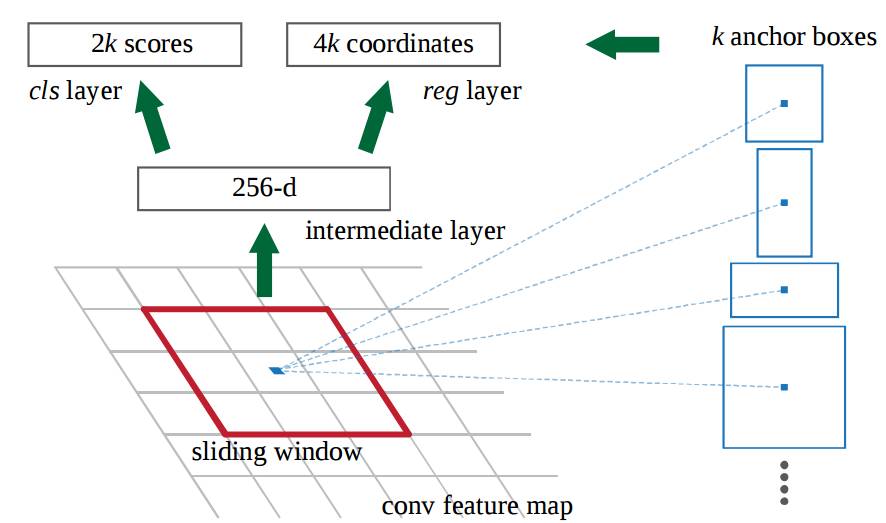
圖中 2k 分數代表了 k 中每一個邊界框正好覆蓋「目標」的 softmax 概率。這裡注意到,儘管 RPN 輸出了邊界框的座標,然而它並不會去對任何可能的目標進行分類:它惟一的工作仍然是給出物件區域。如果一個 anchor box 在特定閾值之上存在一個「objectness」分數,那麼這個邊界框的座標就會作為一個 region proposal 被向前傳遞。
一旦我們有了 region proposal,我們就直接把他們輸入一個本質上是 Fast R-CNN 的模型。我們再新增一個池化層、一些全連線層以及最後,一個 softmax 分類層和邊界框迴歸器(bounding box regressor)。所以在某種意義上,Faster R-CNN=RPN+Fast R-CNN。

總體而言,Faster R-CNN 較 Fast R-CNN 在速度上有了大幅提升,而且其精確性也達到了最尖端的水平。值得一提的是,儘管未來的模型能夠在檢測速度上有所提升,但是幾乎沒有模型的表現能顯著超越 Faster R-CNN。換句話說,Faster R-CNN 也許不是目標檢測最簡單、最快的方法,但是其表現還是目前最佳的。例如,Tensorflow 應用 Inception ResNet 打造的 Faster R-CNN 就是他們速度最慢,但卻最精準的模型。
也許 Faster R-CNN 看起來可能會非常複雜,但是它的核心設計還是與最初的 R-CNN 一致:先假設物件區域,然後對其進行分類。目前,這是很多目標檢測模型使用的主要思路,包括我們接下來將要提到的這個模型。
R-FCN
還記得 Fast R-CNN 是如何通過在所有 region proposal 上共享同一個 CNN,來改善檢測速度的嗎?這也是設計 R-FCN 的一個動機:通過最大化共享計算來提升速度。
R-FCN,或稱 Region-based Fully Convolutional Net(基於區域的全卷積網路),可以在每個輸出之間完全共享計算。作為全卷積網路,它在模型設計過程中遇到了一個特殊的問題。
一方面,當對一個目標進行分類任務時,我們希望學到模型中的位置不變性(location invariance):無論這隻貓出現在圖中的哪個位置,我們都想將它分類成一隻貓。另一方面,當進行目標檢測任務時,我們希望學習到位置可變性(location variance):如果這隻貓在左上角,那麼我們希望在影象左上角這個位置畫一個框。所以,問題出現了,如果想在網路中 100% 共享卷積計算的話,我們應該如何在位置不變性(location invariance)和位置可變性(location variance)之間做出權衡呢?
R-FCN 的解決方案:位置敏感分數圖
每個位置敏感分數圖都代表了一個目標類(object class)的一個相關位置。例如,只要是在影象右上角檢測到一隻貓,就會啟用一個分數圖(score map)。而當系統看見左下角出現一輛車時,另一個分數圖也將會被啟用。本質上來講,這些分數圖都是卷積特徵圖,它們被訓練來識別每個目標的特定部位。
以下是 R-FCN 的工作方式:
-
在輸入影象上執行一個 CNN(本例中使用的是 ResNet)。
-
新增一個全卷積層,以生成位置敏感分數圖的 score bank。這裡應該有 k²(C+1) 個分數圖,其中,k²代表切分一個目標的相關位置的數量(比如,3²代表一個 3x3 的空間網格),C+1 代表 C 個類外加一個背景。
-
執行一個全卷積 region proposal 網路(RPN),以生成感興趣區域(regions of interest,RoI)。
-
對於每個 RoI,我們都將其切分成同樣的 k²個子區域,然後將這些子區域作為分數圖。
-
對每個子區域,我們檢查其 score bank,以判斷這個子區域是否匹配具體目標的對應位置。比如,如果我們處在「上-左」子區域,那我們就會獲取與這個目標「上-左」子區域對應的分數圖,並且在感興趣區域(RoI region)裡對那些值取平均。對每個類我們都要進行這個過程。
-
一旦每個 k²子區域都具備每個類的「目標匹配」值,那麼我們就可以對這些子區域求平均值,得到每個類的分數。
-
通過對剩下 C+1 個維度向量進行 softmax 迴歸,來對 RoI 進行分類。
下面是 R-FCN 的示意圖,用 RPN 生成 RoI:
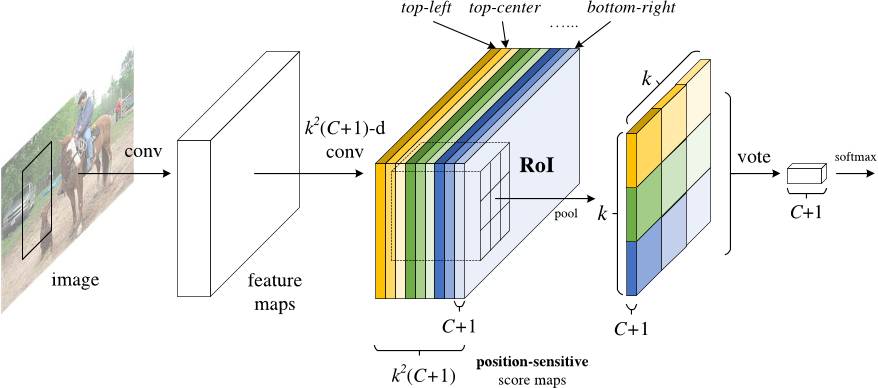
當然,即便有上述文字以及圖片的解釋,你可能仍然不太明白這個模型的工作方式。老實說,當你可以實際看到 R-FCN 的工作過程時,你會發現理解起來會更加簡單。下面就是一個在實踐中應用的 R-FCN,它正在從圖中檢測一個嬰兒:

我們只用簡單地讓 R-FCN 去處理每個 region proposal,然後將其切分成子區域,在子區域上反覆詢問系統:「這看起來像是嬰兒的『上-左』部分嗎?」,「這看起來像是嬰兒的『上-中』部分嗎?」,「這看起來像是嬰兒的『上-右』部分嗎?」等等。系統會對所有類重複這個過程。如果有足夠的子區域表示「是的,我的確匹配嬰兒的這個部分!」那麼 RoI 就會通過對所有類進行 softmax 迴歸的方式被分類成一個嬰兒。」
藉助這種設定,R-FCN 便能同時處理位置可變性(location variance)與位置不變性(location invariance)。它給出不同的目標區域來處理位置可變性,讓每個 region proposal 都參考同一個分數圖 score bank 來處理位置不變形。這些分數圖應該去學習將一隻貓分類成貓,而不用管這隻貓在在那個位置。最好的是,由於它是全卷積的,所以這意味著網路中所有的計算都是共享的。
因此,R-FCN 比 Faster R-CNN 快了好幾倍,並且可以達到類似的準確率。
SSD
我們最後一個模型是 SSD,即 Single-Shot Detector。和 R-FCN 一樣,它的速度比 Faster R-CNN 要快很多,但其工作方式卻和 R-FCN 存在顯著不同。
我們前兩個模型分兩個步驟執行 region proposal 和 region classification。首先,它們使用一個 region proposal 網路來生成感興趣區域(region of interest);然後,它們既可以用全連線層也可以用位置敏感卷積層來對那些區域進行分類。然而,SSD 可以在單個步驟中完成上述兩個步驟,並且在處理影象的同時預測邊界框和類。
具體而言,給定一個輸入影象以及一系列真值標籤,SSD 就會進行如下操作:
-
在一系列卷積層中傳遞這個影象,產生一系列大小不同的特徵圖(比如 10x10、6x6、3x3 等等。)
-
對每個這些特徵圖中的每個位置而言,都使用一個 3x3 的卷積濾波器(convolutional filter)來評估一小部分預設的邊界框。這些預設邊的界框本質上等價於 Faster R-CNN 的 anchor box。
-
對每個邊界框都同時執行預測: a)邊界框的偏移;b)分類的概率。
-
在訓練期間,用這些基於 IoU(Intersection over Union,也被稱為 Jaccard 相似係數)係數的預測邊界框來匹配正確的邊界框。被最佳預測的邊界框將被標籤為「正」,並且其它邊界框的 IoU 大於 0.5。
SSD 的工作方式聽上去很直接,但是訓練它卻會面臨一個不一般的挑戰。在之前那兩個模型那裡,region proposal 網路可以確保每個我們嘗試進行分類的物件都會有一個作為「目標」的最小概率值。然而,在 SSD 這裡,我們跳過了這個篩選步驟。我們從影象中每個單一位置那裡進行分類並畫出形狀、大小不同的邊界框。通過這種辦法,我們可以生成比別的模型更多的邊界框,但是它們基本上全是負面樣本。
為了解決這個問題,SSD 進行了兩項處理。首先,它使用非極大值抑制(non maximum suppression,NMS)技術來將高度重疊的邊界框整合成一個。換句話說,如果有 4 個形狀、尺寸等類似的邊界框中有同一只狗,那麼 NMS 就會保留信度最高的那個邊界框而拋棄掉其它的。第二,SSD 模型使用了一種被稱為 hard negative mining 的技術以在訓練過程中讓類保持平衡。在 hard negative mining 中,只有那些有最高訓練損失(training loss)的負面樣本(negative example)子集才會在每次訓練迭代中被使用。SSD 的「正負」比一直保持在 1:3。
下圖是 SSD 的架構示意圖:
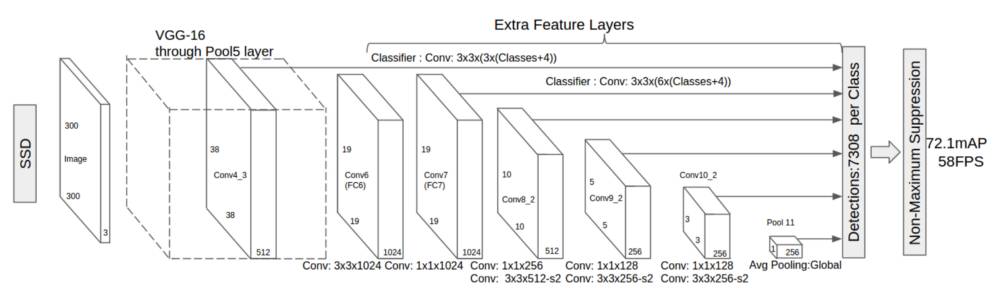
如上所述,最終有可縮小尺寸的「額外特徵層」。這些尺寸變化的特徵圖有助於捕捉不同大小的目標。例如,下面是一個正在執行的 SSD。
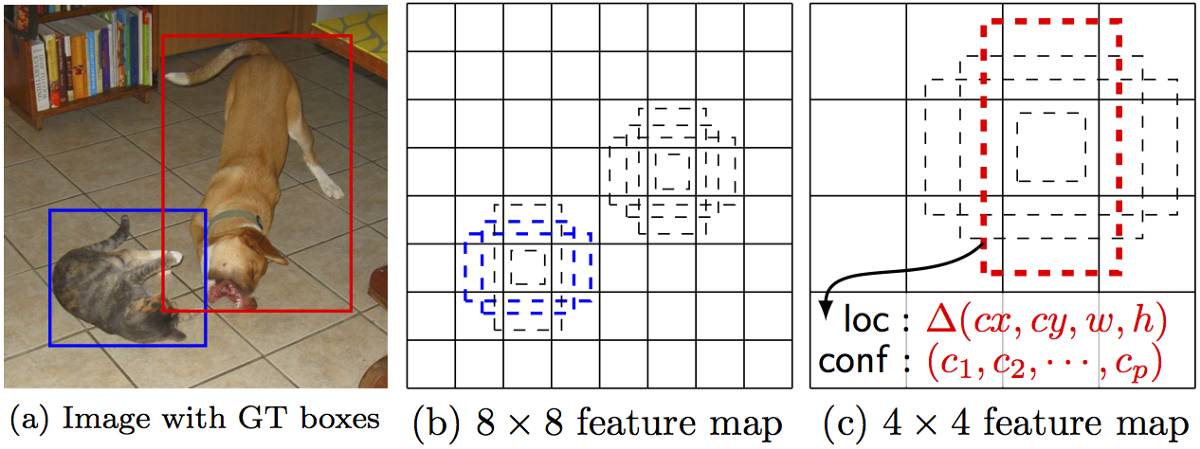
在更小的特徵圖中(比如 4x4),每一單元覆蓋影象的一個更大區域,使其探測更大的目標。region proposal 與分類同時被執行:假設 p 為目標類別,每個邊界框與一個 (4+p)-維度向量相連線,其輸出 4 個框偏移座標和 p 分類概率。在最後一步中,softmax 又一次被用來分類目標。
最終,SSD 與最初的兩個模型並無不同。它簡單跳過「region proposal」這一步,而不是同時考慮影象每個位置的每個邊界及其分類。由於 SSD 一次性完成所有,它是三個模型中最快的,且相對而言依然表現出色。
結論
Faster R-CNN、R-FCN 和 SSD 是三種目前最優且應用最廣泛的目標檢測模型。其他流行的模型通常與這三者類似,都依賴於深度 CNN(如 ResNet、Inception 等)來進行網路初始化,且大部分遵循同樣的 proposal/分類 pipeline。
但是,使用這些模型需要了解 Tensorflow 的 API。Tensorflow 有一份使用這些模型的初學者教程。
原文連結:https://medium.com/towards-data-science/deep-learning-for-object-detection-a-comprehensive-review-73930816d8d9