
hbase SQL 框架phoenix使用
1 簡介
hbase 提供很方便的shell指令碼以及java API等方式對Hbase進行操作,但是對於很對已經習慣了關係型資料庫操作的開發來說,有一定的學習成本,如果可以像操作mysql等一樣通過sql實現對Hbase的操作,那麼很大程度降低了Hbase的使用成本。Apache Phoenix 元件就完成了這種需求,官方註解為 “Phoenix -we put the SQL back in NoSql”,通過官方說明,Phoenix 的效能很高,相對於 hbase 原生的scan 並不會差多少,而對於類似的元件 hive、Impala等,效能有著顯著的提升,詳細請閱讀https://phoenix.apache.org/performance.html。
Apache Phoenix 官方站點:https://phoenix.apache.org/
Phoenix支援的sql語句: https://phoenix.apache.org/language/index.html
Phoenix 支援的DataTypes:https://phoenix.apache.org/language/datatypes.html
Phoenix 支援的函式:https://phoenix.apache.org/language/functions.html
2 安裝配置
2.1 環境說明
Hbase使用兩臺主機,主機名和IP分別為:
master 172.18.68.119
slave01 172.18.68.88
master作為主節點,slave01作為從節點,即作為Hbase的HRegionServer。
hbase的安裝位置:/home/hadoop/hbase
2.2 下載
在官網http://www.apache.org/dyn/closer.lua/phoenix/中選擇提供的映象站點中下載與安裝的HBase版本對應的版本。本地使用的1.3.1,故下載的apache-phoenix-4.11.0-HBase-1.3/的tar.gz包。

2.3 安裝配置
2.3.1 上傳phoenix到master
使用secureCRT或者其他傳輸工具將下載的tar包上傳到hbase叢集的master結點中。
$cd /home/hadoop/
$mkdir phoenix
$cd phoenix
$rz
$tar -zxvf apache-phoenix-4.11.0-HBase-1.3-bin.tar.gz
$mv apache-phoenix-4.11.0-HBase-1.3-bin/ phoenix
2.3.2 拷貝phoenix-core-4.11.0-HBase-1.3.jar到RegionServer
將phoenix-core-4.11.0-HBase-1.3.jar拷貝到hbase叢集中的所有region server的hbase的lib目錄下。在測試環境下,master和slave01均作為regionserver。
$cd /home/hadoop/phoenix/phoenix
$cp phoenix-core-4.11.0-HBase-1.3.jar /home/hadoop/hbase/lib 拷貝到master
$scp -r [email protected]:/home/hadoop/hbase/lib 拷貝到slave01
2.3.3 重啟hbase
$cd /home/hadoop/hbase/bin
$./stop-hbase.sh
$./start-hbase.sh
3 phoenix命令列使用
3.1 進入命令列
$cd /home/hadoop/phoenix/phoenix/bin進入phoenix的bin目錄
$./sqlline.py master 其中的master為Zookeeper所在節點的主機名
3.2 sqlline.py執行sql指令碼
可以使用sqlline.py命令執行sql指令碼檔案,如下:
$ cd/home/hadoop/phoenix/phoenix
$ bin/sqlline.py masterexamples/STOCK_SYMBOL.sql
STOCK_SYMBOL.sql檔案內容如下:
CREATE TABLE IF NOT EXISTS STOCK_SYMBOL (SYMBOL VARCHAR NOT NULL PRIMARY KEY, COMPANY VARCHAR);
UPSERT INTO STOCK_SYMBOL VALUES ('CRM','SalesForce.com');
SELECT * FROM STOCK_SYMBOL;
3.3 psql.py執行sql指令碼
可以通過phoenix的bin目錄下的psql.py指令碼載入CSV資料或者執行包含sql指令碼的檔案,如下:
$cd /home/hadoop/phoenix/phoenix
$bin/psql.py master ../examples/WEB_STAT.sql ../examples/WEB_STAT.csv ../examples/WEB_STAT_QUERIES.sql
其中WEB_STAT.sql、WEB_STAT.csv、WEB_STAT_ QUERIES.sql是phoenix提供的samples下的檔案,檔案內容如下:
WEB_STAT.sql 為建立表的sql指令碼檔案
CREATE TABLE IF NOT EXISTS WEB_STAT (
HOST CHAR(2) NOT NULL,
DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,
DATE DATE NOT NULL,
USAGE.CORE BIGINT,
USAGE.DB BIGINT,
STATS.ACTIVE_VISITOR INTEGER
CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)
);
WEB_STAT.csv 為資料檔案
NA,Salesforce.com,Login,2013-01-01 01:01:01,35,42,10
EU,Salesforce.com,Reports,2013-01-02 12:02:01,25,11,2
EU,Salesforce.com,Reports,2013-01-02 14:32:01,125,131,42
NA,Apple.com,Login,2013-01-01 01:01:01,35,22,40
NA,Salesforce.com,Dashboard,2013-01-03 11:01:01,88,66,44
NA,Salesforce.com,Login,2013-01-04 06:01:21,3,52,1
EU,Apple.com,Mac,2013-01-01 01:01:01,35,22,34
NA,Salesforce.com,Login,2013-01-04 11:01:11,23,56,45
EU,Salesforce.com,Reports,2013-01-05 03:11:12,75,22,3
EU,Salesforce.com,Dashboard,2013-01-06 05:04:05,12,22,43...
WEB_STAT_ QUERIES.sql為查詢指令碼檔案
SELECT DOMAIN, AVG(CORE) Average_CPU_Usage, AVG(DB) Average_DB_Usage
FROM WEB_STAT
GROUP BY DOMAIN
ORDER BY DOMAIN DESC;
-- Sum, Min and Max CPU usage by Salesforce grouped by day
SELECT TRUNC(DATE,'DAY') DAY, SUM(CORE) TOTAL_CPU_Usage, MIN(CORE) MIN_CPU_Usage, MAX(CORE) MAX_CPU_Usage
FROM WEB_STAT
WHERE DOMAIN LIKE 'Salesforce%'
GROUP BY TRUNC(DATE,'DAY');
-- list host and total active users when core CPU usage is 10X greater than DB usage
SELECT HOST, SUM(ACTIVE_VISITOR) TOTAL_ACTIVE_VISITORS
FROM WEB_STAT
WHERE DB > (CORE * 10)
GROUP BY HOST;
3.4 phoenix表操作
3.4.1 建立表
CREATE TABLE IF NOT EXISTS us_population (
stateCHAR(2) NOT NULL,
cityVARCHAR NOT NULL,
populationBIGINT
CONSTRAINTmy_pk PRIMARY KEY (state, city));在phoenix中,預設情況下,表名等會自動轉換為大寫,若要小寫,使用雙引號,如"us_population"。
3.4.2 顯示所有表
!table或
!tables
3.4.3 插入記錄
upsert into us_population values('NY','NewYork',8143197);
3.4.4 查詢記錄
select * from us_population ;
select * from us_population wherestate='NY';
3.4.5 刪除記錄
delete from us_population wherestate='NY';
3.4.6 刪除表
drop table us_population;
3.4.7 退出命令列
!quit
具體語法參照官網
https://phoenix.apache.org/language/index.html#upsert_select
3.5 phoenix表對映
預設情況下,直接在hbase中建立的表,通過phoenix是檢視不到的,如圖1和圖2,US_POPULATION是在phoenix中直接建立的,而test是在hbase中直接建立的,預設情況下,在phoenix中是檢視不到test的。
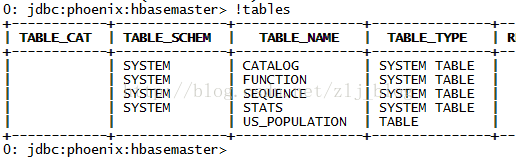
圖1 phoenix命令列中檢視所有表

圖2 hbase命令列中檢視所有表
如果需要在phoenix中操作直接在hbase中建立的表,則需要在phoenix中進行表的對映。對映方式有兩種:檢視對映和表對映。
hbase 中test的表結構如下,兩個列簇name、company.

3.5.1 hbase命令列中建立表
$ cd /home/hadoop/hbase/bin
$ ./hbase shell 進入hbase命令列
create 'test','name','company' 建立表,如下圖
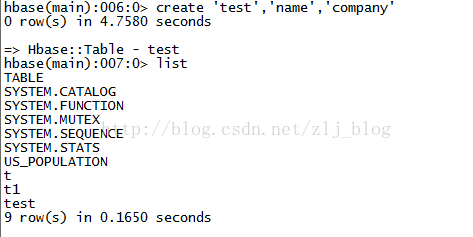
下面的檢視對映和表對映均基於該表。
3.5.2 檢視對映
Phoenix建立的檢視是隻讀的,所以只能用來做查詢,無法通過檢視對源資料進行修改等操作。而且相比於直接建立對映表,檢視的查詢效率會低,原因是:建立對映表的時候,Phoenix會在表中建立一些空的鍵值對,這些空鍵值對的存在可以用來提高查詢效率。
1)建立檢視
create view"test"(empid varchar primarykey,"name"."firstname" varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);2)刪除檢視
drop view "test";
3.5.3 表對映
使用Apache Phoenix建立對HBase的表對映,有兩種方法:
1) 當HBase中已經存在表時,可以以類似建立檢視的方式建立關聯表,只需要將create view改為create table即可。
2)當HBase中不存在表時,可以直接使用create table指令建立需要的表,並且在建立指令中可以根據需要對HBase表結構進行顯示的說明。
第1)種情況下,如在之前的基礎上已經存在了test表,則表對映的語句如下:
create table "test"(empid varchar primarykey,"name"."firstname"varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
第2)種情況下,直接使用與第1)種情況一樣的create table語句進行建立即可,這樣系統將會自動在Phoenix和HBase中建立person_infomation的表,並會根據指令內的引數對錶結構進行初始化。
使用create table建立的關聯表,如果對錶進行了修改,源資料也會改變,同時如果關聯表被刪除,源表也會被刪除。但是檢視就不會,如果刪除檢視,源資料不會發生改變。
4 SQuirrel使用
如果希望通過客戶端以圖形化的介面操作Phoenix的話,可以下載並安裝SQuirrel。
SQuirrel SQL Client是一個用Java寫的資料庫客戶端,可以通過一個統一的使用者介面來操作MySQL 、PostgreSQL 、MSSQL、 Oracle等任何支援JDBC訪問的資料庫。使用起來非常方便。
SQuirrel下載頁面:http://squirrel-sql.sourceforge.net/#installation。
SQuirrel的安裝步驟(參考https://phoenix.apache.org/installation.html):
1)移除SQuirrel的lib資料夾下的phoenix-[oldversion]-client.jar(如果有的話),然後拷貝phoenix-[newversion]-client.jar到SQuirrel的lib資料夾下,phoenix-[newversion]-client.jar須與欲連線的hbase的lib下的phoenix版本一致。
2)windows下,執行squirrel-sql.bat啟動SQuirrel,在啟動介面下,切換到Drivers選項卡,點選+號新增新的驅動。
3)在新增驅動對話方塊中,設定name為Phoenix,設定Example URL為 jdbc:phoenix:localhost,其中的localhost為hbase使用的Zookeeper主機名。
4)設定Class Name文字框的內容為 “org.apache.phoenix.jdbc.PhoenixDriver”, 如圖4.1,然後點選“OK”關閉。
5)切換到Aliases選項卡,點選+新建一個alias。
6)在對話方塊中,name:任何名稱,Driver:選擇phoenix,username、password可省略,或者填任意值均可。
7)URL的內容為:jdbc:phoenix: zookeeperquorum server,例如,要連線本機的hbase,URL為:jdbc:phoenix:localhost,如圖4.2。
8)點選Test,在新對話方塊中選擇connect,如果一切設定正確的話,應該連線成功,然後點選OK關閉對話方塊。
9)雙擊新建的phoenix alias,點選connect,然後就可以通過phoenix的sql語句操作hbase了,如圖4.3。
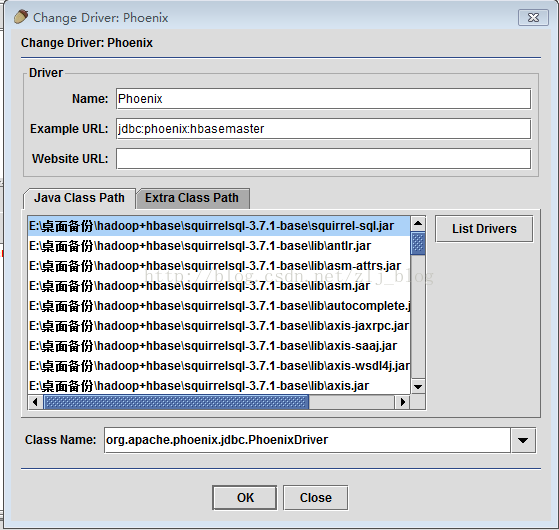
圖4.1 新建Driver

圖4.2 新建Alias
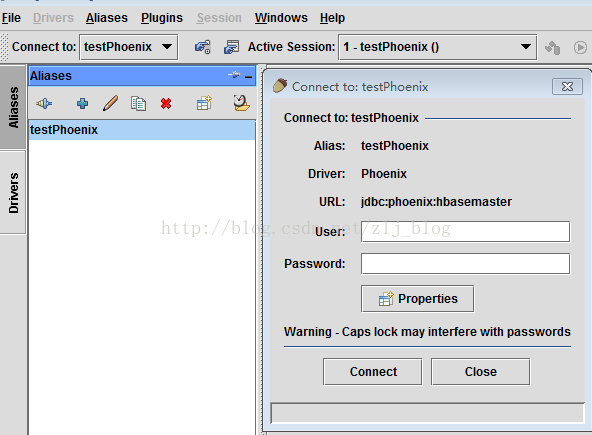
圖 4.3 建立連線