
數學篇----引數估計之最大似然估計法[概率論]
前言
引數估計問題分:點估計、區間估計。
點估計是適當地選擇一個統計量作為未知引數的估計(稱為估計量),若已取得一樣本,將樣本值代入估計量,得到估計量的值,以估計量的值作為未知引數的近似值(稱為估計值)。(另一種解釋:依據樣本估計總體分佈中所含的未知引數或未知引數的函式。)
有很多求點估計的方法:最大似然估計法、矩估計法、最小二乘法、貝葉斯估計法。重點就是最大似然法。
最大似然估計法的基本思想:若已觀察到樣本(X1,X2,··· ,Xn)的樣本值(x1,x2,...,xn),而取得這一樣本值得概率為p(在離散型的情況),或(X1,X2,··· ,Xn)落在這一樣本值(x1,x2,...,xn)的鄰域內的概率為p(在連續型的情況),而p與未知引數有關,我們就取θ的估計值使概率p取得最大。
說說區間估計,因為點估計不能反映估計的精度,所有才用。
1 基本概念
似然:可以理解為“可能性”,這樣就有“概率”的意思了。
符號
符號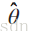
估計量:
估計值:
注:(X1,X2,··· ,Xn)是一個樣本,(x1,x2,...,xn)是相應的樣本值。
概念如下圖:

2 為什麼叫“最大”
費希爾(R.A.Fisher)的想法:固定樣本觀察值x1,x2,...,xn,在θ取值的可能範圍
為了使似然函式的結果最大,所選的引數θ一定也要大,記為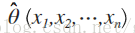
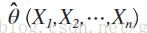
3 求解過程
會遇到兩類求解:總體X是連續型,總體X是離散型。但是差不多,連續型的求解可以變成離散型的。
已知條件:總體X屬連續型,概率密度 f(x;θ),θ∈
設X1,X2,··· ,Xn是來自X的一個樣本,則X1,X2,··· ,Xn的聯合密度為:
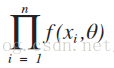
設x1,x2, ... ,xn是相應於樣本X1,X2,··· ,Xn的一個樣本值,則隨機點(X1,X2,··· ,Xn)落在點(x1,x2, ... ,xn)的領域內的概率近似地為:
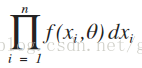
與離散型的情況一樣,我們取θ的估計值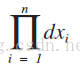
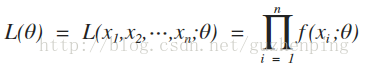
若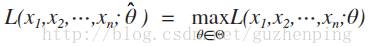
則稱
====================分割性===================================分割性====================================分割性=====================
到這,確定最大似然估計量的問題就歸結為微分學中的求最大值問題。
若 f(x;θ) 關於θ可微,這時
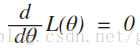
因為L(θ)與 lnL(θ) 在同一θ處取得極值,因此,θ的最大似然估計θ也可以從下面的方程解得:
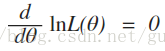
(我也不太懂大牛們為什麼取對數求解,需要學習。)
附:
其他同學的總結,最大似然估計法的一般步驟:
- 寫出似然函式;
- 對似然函式取對數,並整理;
- 求導數;
- 解似然方程。
參考資料:《概率論與數理統計(第四版)》 浙江大學 盛驟 謝式千 潘承毅 編
內容來自:谷震平的部落格,希望尊重版權,尊重原創。
連結:http://blog.csdn.net/guzhenping