
深入搜尋引擎--查詢(Query)
1.Query的資料分析
Query即使用者在搜尋引擎輸入查詢條件。在通用搜索引擎中,一般是指輸入的關鍵詞。而在各類行業或者垂直搜尋引擎,還可以輸入類目,如優酷網站中可以選擇“電影”、“電視劇”這樣的類目。在電子商務網站中,各種產品品牌、型號、款式、價格等也是常見的查詢條件。
要分析query中每個term的內容,分詞是必不可少的工具。分詞演算法從最簡單的最大正向、最大反向分詞演算法,到複雜的隱馬爾科夫、CRF模型。CRF模型是一種序列標註的機器學習方法。分詞演算法最關鍵的是如何得到足夠的標註準確的語料庫,足夠的訓練語料是模型成功的基礎條件。
Query按照PV從高到低排序之後。橫座標為query編號,縱座標是query的PV。從下圖可以明顯看出,query的PV分佈是一個長尾分佈。
每種搜尋引擎的query 都有自己的特點。根據query的特點來設計自己的演算法和相應產品是非常必要的。例如:百度有很多查詢“從A到B怎麼走”,“××怎麼樣”。相信百度正是研究了這些查詢,才力推百度“貼吧”和“知道”,“百科”等產品的。通用搜索引擎和電子商務網站的query區別一定很大。例如joyo噹噹一定有大量書籍名稱的查詢。而在電子商務網站,有大量類目+屬性的查詢方式。如何組合的輸入條件,準確分析使用者意圖,保證搜尋引擎結果的召回率和準確率是一個挑戰。
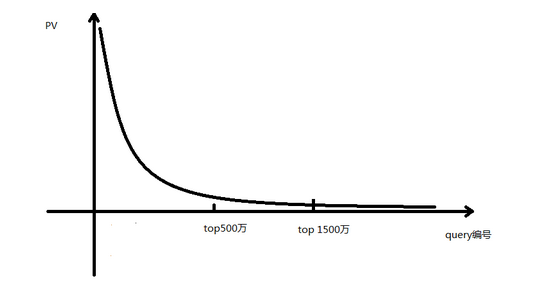
20-80定律:query 和cache
我們發現20%的top query,佔據了80%的PV流量。如果解決了這20%的query的分析和排序問題,我們就解決了絕大多數流量的問題。
針對20%的query,我們可以優化搜尋引擎的索引結構,儘量直接返回使用者需要的資訊。在query分析的模組,我們可以儲存query的分詞、詞性標註以及query分類等結果。總之高效利用記憶體,用記憶體換取效能的極大提升。
query的分類和“框計算”
query分類是目前通用搜索引擎必須解決的問題。當你在百度或者google上面輸入“××市天氣”,會顯示天氣狀態圖片、溫度等;輸入“中石油”直接顯示出中石油的股價;輸入“航班”直接從航班起點和終點的選擇。這也是百度所謂的“框計算”,也就是直接在搜尋框完成解析,直達具體的應用。
如何做分類呢?
假設搜尋引擎已經對網頁分類,那麼統計每個query下點選的頁面分類,把頁面類別的概率按照從高到低排列,也就是query的分類。也就可以知道這個query的分類。但是這種只能用在當query的點選數量足夠的時候。
另外一種辦法是通過頁面分類,用貝葉斯的方法,反推每個query可能屬於那些類別。
query的導航
query的分類其實是導航的一個基本條件。只有當你對query的分類準確,對query中每個term的詞性理解準確的時候,導航才真正開始。
在電子商務網站,如Amazon、京東等網站。準確的導航是非常必要的。
而準確的導航是第一步。根據使用者輸入,在導航中體現相關熱門推薦,或者個性化推薦,是對導航的更進一步的要求。
在淘寶搜尋產品上,當用戶輸入關鍵詞,會自動提示相應的類目和屬性,並且把熱門的類目屬性展示在前面,而把相對冷門的類目和屬性摺疊起來。最大利用網頁有限的展示空間。
query與個性化
說到個性化,必然涉及到對使用者資料的收集。根據使用者的行為或者設定,分析使用者的年齡、性別、偏好等。同樣是搜尋“咖啡館”,你在北京和上海搜尋得到結果可能差異很大。
而這些分析資料來源於對每個使用者在搜尋引擎的行為日誌。搜尋引擎都會分析每個使用者的搜尋和點選等行為。儲存的時候存在在分散式key-value記憶體資料庫中。
使用者行為不僅僅對個別使用者本身有用。大量使用者的行為日誌,被廣泛用於推薦系統的資料探勘。例如使用者在噹噹joyo上面購買的書籍,就來自於大量使用者的購買和瀏覽記錄。推薦系統從常見的關聯規則分析,已經進化到各種複雜的圖關係分析演算法。