
Elasticsearch 之 資料索引
對於提供全文檢索的工具來說,索引時一個關鍵的過程——只有通過索引操作,才能對資料進行分析儲存、建立倒排索引,從而讓使用者查詢到相關的資訊。
本篇就ES的資料索引操作相關的內容展開:
索引操作
最簡單的用法就是指定索引操作的index索引、type型別、ID(需要區分動詞的索引和名次的索引),參考下面的例子:
$ curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{ "user" : "kimchy", "post_date" : "2009-11-15T14:12:12", "message" : "trying out Elasticsearch" }'
這樣就在索引twitter中的tweet型別中儲存了id為1的資料。
索引操作的結果為:
{ "_shards" : { "total" : 10, "failed" : 0, "successful" : 10 }, "_index" : "twitter", "_type" : "tweet", "_id" : "1", "_version" : 1, "created" : true }
上面的_shards中描述了分片相關的資訊,即當前一共有10個分片(5個主分片,5個副分片,並且均可用);以及index、type、id、version相關的資訊。
自動建立索引
如果上面執行操作前,ES中沒有twitter這個索引,那麼預設會直接建立這個索引;並且type欄位也會自動建立。也就是說,ES並不需要像傳統的資料庫事先定義表的結構。
每個索引中的型別都有一個mapping對映,這個對映是動態生成的,因此當增加新的欄位時,會自動增加mapping的設定。
通過在配置檔案中設定action.auto_create_index為false,可以關閉自動建立index這個功能。
自動建立索引功能,也可以設定黑名單或者白名單,比如:
設定action.auto_create_index為 +aaa*,-bbb*,'+'號意味著允許建立aaa開頭的索引,'-'號意味著不允許建立bbb開頭的索引
關於版本號
版本號維護了一個文件的狀態,我們只會針對最高版本號的文件進行操作。
文件號不僅可以在文件中進行儲存,也可以在外部維護版本號,具體的參考官方文件吧....
操作型別op_type
ES通過引數op_type提供“缺少即加入”的功能,即如果ES中沒有該文件,就進行索引;如果有了,則報錯返回。
如果已經存在id為1的文件,則會報錯,直接使用_create API,效果一樣:
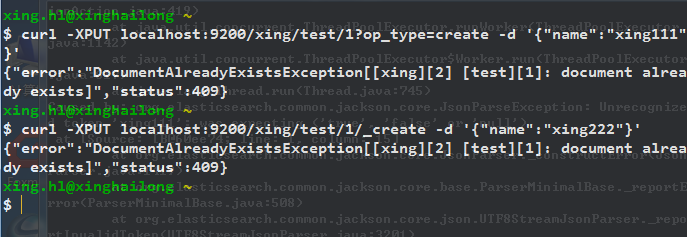
自動建立ID:
按照最上面的例子來說,ES會把我們指定的文件id做為ID。如果不指定ID,那麼就會隨機分配一個:

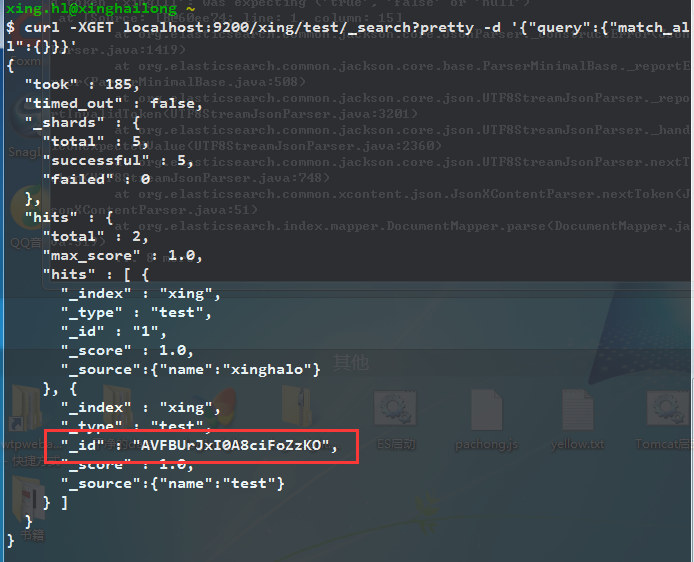
路由routing
ES是通過路由來進行查詢的,一般一個查詢會經過下面的過程:
1 節點接收請求,廣播給每個分片
2 分片接收請求,進行計算,返回結果
3 合併訊息,返回
如果我們設定了路由資訊,就相當於告訴了ES,該去哪個分片查詢資料,也就取消了廣播合併這個過程,從而提高了查詢的效率。使用方法:
$ curl -XPOST 'http://localhost:9200/twitter/tweet?routing=kimchy' -d '{ "user" : "kimchy", "post_date" : "2009-11-15T14:12:12", "message" : "trying out Elasticsearch" }'
路由是通過雜湊來實現的,如果我們在索引的時候直接指定routing的值,就會按照這個值計算雜湊值,分配分片;如果不指定,就會根據ID來分配。由於一般情況下ID都是隨機生成的,這樣就可以保證預設情況下分片的資料負載是相同的。如果我們需要在特定的分片儲存特定的內容,就可以使用路由指定分片。不過這樣做,日後隨著資料量的增加,也可能會導致某個分片壓力過大。
另外,也可以在定義mapping的時候,直接設定routing的相關值。這樣這個型別中的資料如果不指定routing的值,預設就會使用mapping中定義的那個路由值。
parent設定父子關係
ES中可能會涉及到一些文件的從屬關係,使用parent引數,可以設定這種關係:
$ curl -XPUT localhost:9200/blogs/blog_tag/1122?parent=1111 -d '{ "tag" : "something" }'
_timestamp設定時間戳
時間戳欄位可以也可以在索引操作時指定:
$ curl -XPUT localhost:9200/twitter/tweet/1?timestamp=2009-11-15T14%3A12%3A12 -d '{ "user" : "kimchy", "message" : "trying out Elasticsearch" }'
如果沒有手動指定時間戳,_source中也不存在時間戳,就會設定為索引指定的時間。不過需要指定mapping中的_timestamp設定為enable
PUT my_index { "mappings": { "my_type": { "_timestamp": { "enabled": true } } } }
ttl文件過期
ES中也可以設定文件自動過期,過期是設定一個正的時間間隔,然後以_timestamp為基準,如果超時,就會自動刪除。
如果設定為時間戳:
curl -XPUT 'http://localhost:9200/twitter/tweet/1?ttl=86400000' -d '{ "user": "kimchy", "message": "Trying out elasticsearch, so far so good?" }'
如果設定為日期數學表示式:
curl -XPUT 'http://localhost:9200/twitter/tweet/1?ttl=1d' -d '{ "user": "kimchy", "message": "Trying out elasticsearch, so far so good?" }'
也可以在JSON欄位中指定:
curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{ "_ttl": "1d", "user": "kimchy", "message": "Trying out elasticsearch, so far so good?" }'
手動重新整理
由於ES並不是一個實時索引搜尋的框架,因此資料在索引操作後,需要等1秒鐘才能搜尋到。這裡的搜尋是指進行檢索操作。如果你使用的是get這種API,就是真正的實時操作了。他們之間的不同是,檢索可能還需要進行分析和計算分值相關性排序等操作。
為了在資料索引操作後,馬上就能搜尋到,也可以手動執行refresh操作。只要在API後面新增refresh=true即可。
這種操作僅推薦在特殊情況下使用,如果在大量所以操作中,每個操作都執行refresh,那是很耗費效能的。
Timeout超時
分片並不是隨時可用的,當分片進行備份等操作時,是不能進行索引操作的。因此需要等待分片可用後,再進行操作。這時,就會出現一定的等待時間,如果超過等地時間則返回並丟擲錯誤,這個等待時間可以通過timeout設定:
$ curl -XPUT 'http://localhost:9200/twitter/tweet/1?timeout=5m' -d '{ "user" : "kimchy", "post_date" : "2009-11-15T14:12:12", "message" : "trying out Elasticsearch" }'
以上便是索引操作相關的知識,還有一些高階的知識,比如分片和版本號詳細的用法,由於對ES還是理解的不夠透徹,就先不做過多的講述了,免得錯誤太多。
如有異議,還請多多指正。