
Elasticsearch之資料如何在叢集中分佈和獲取。
- 路由文件到分片
當你索引一個文件,它被儲存在單獨一個主分片上。Elasticsearch是如何知道文件屬於哪個分片的呢?當你建立一個新文件,它是如何知道是應該儲存在分片1還是分片2上呢?
程序不能是隨機的,因為我們將來要檢索文件。事實上,他根據一個簡單的演算法決定:
shard = hash(routing) % number_of_primary_shards
routing值是一個任意字串,它預設是_id,但也可以自定義。這個routing字串通過雜湊函式生成一個數字,然後除以主切片的數量得到一個餘數(remainder),餘數的範圍永遠是0到number_of_primary_shards - 1,這個數字就是特定文件所在的分片。
這也解釋了為什麼主分片的數量只能在建立索引時定義且不能修改:如果主分片的數量在未來改變了,所有先前的路由值就失效了,文件也就永遠找不到了。
注:有時使用者認為固定數量的主分片會讓之後的擴充套件變得困難。現實中,有些技術會在你需要的時候讓擴充套件變得容易。
所有的文件API(get、index、delete、bulk、update、mget)都接收一個routing引數,它用來自定義文件到分片的對映。自定義路由值可以確保所有相關文件——例如屬於同一個人的文件——被儲存在同一個分片上。
- 主分片和複製分片如何互動
為了闡述意圖,我們假設有三個節點的叢集。它包含一個叫做bblogs的索引並擁有兩個主分片。每個主分片有兩個複製分片。相同的分片不會放在同一個節點上,所以我們的叢集是這樣的:
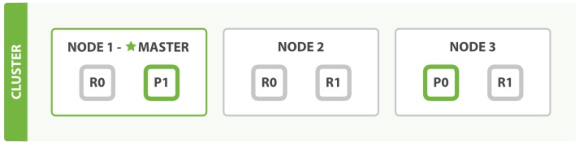
我們能夠傳送請求給叢集中任意一個節點。每個節點都有能力處理任意請求。每個節點都知道任意文件所在的節點,所以也可以將請求轉發到需要的節點。下面的例子中,我們將傳送所有請求給 Node 1,這個節點我們將會稱之為請求節點(requesting node)。
提示:當我們傳送請求,最好的做法是迴圈通過所有節點請求,這樣可以平衡負載。
- 新建、索引和刪除文件
新建、索引和刪除請求都是寫(write)操作,它們必須在主分片上成功完成才能複製到相關的複製分片上。
下面我們羅列在主分片和複製分片上成功新建、索引或刪除一個文件必要的順序步驟:
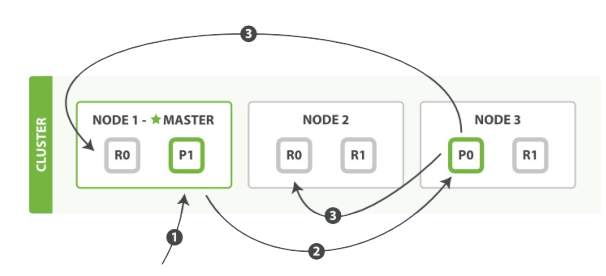
1、客戶端給 Node 1 傳送新建、索引或刪除請求。
2、節點使用文件的_id確定文件屬於分片0.它轉發請求到 Node 3,分片 0 位於這個節點上。
3、Node 3在主分片上執行請求,如果成功,它轉發請求到相應的位於 Node 1 和 Node 2 的複製節點。當所有的複製節點報告成功, Node 3報告成功到請求的節點,請求的節點再報告給客戶端。
客戶端接收到成功響應的時候,文件的修改已經被應用於主分片和所有的複製分片,你的修改生效了。
有很多可選的請求引數允許你更改這一過程。你可能想犧牲一些安全來提高效能。這一選項很少使用是因為Elasticsearch已經足夠快,不過為了內容的完整我們將做一些闡述。
replication
複製預設的值是sync。這將導致主分片得到複製分片的成功響應後才返回。
如果你設定replication為async,請求在主分片上被執行後就會返回給客戶端。它依舊會轉發請求給複製節點,但你將不知道複製節點成功與否。
上面的這個選項不建議使用。預設的sync複製允許Elasticsearch強制反饋傳輸。async複製可能會因為在不等待其他分片就緒的情況下發送過多的請求而使Elasticsearch過載。
consistency
預設主分片在嘗試寫入時需要規定數量(quorum)或過半的分片(可以是主節點或複製節點)可用。這是防止資料被寫入到錯的網路分割槽。規定的數量計算公式如下:
int ( ( primary + number_of_replicas ) / 2 ) + 1
consistency允許的值為one(只有一個主分片),all(所有主分片和複製分片)或者預設的 quorum (過半分片)。
注意number_of_replicas是在索引中的設定,用來定義複製分片的數量,而不是現在活動的複製節點的數量。如果你定義了索引有3個複製節點,那規定數量是:
int ( ( primary + 3 replicas ) / 2) + 1 = 3
但如果你只有2個節點,那你的活動分片不夠規定數量,也就不能索引或刪除任何文件。
timeout
當分片副本不足時會怎樣?Elasticsearch會等待更多的分片出現。預設等待一分鐘。如果需要,你可以設定timeout引數讓它終止的更早:100表示100毫秒,30s表示30秒。
注意:新索引預設有1個複製分片,這意味著為了滿足quorum的要求需要兩個活動的分片。當然這個預設設定將阻止我們在單一節點叢集中進行操作。為了避免這個問題,規定數量只有在number_of_replicas大於一時才生效。
- 檢索文件
文件能夠從主分片或任意一個複製分片被檢索。
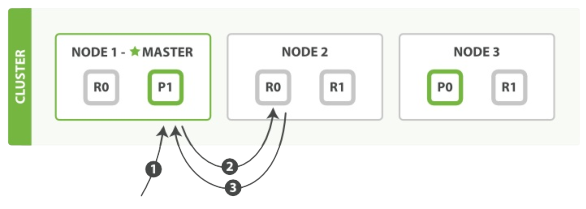
下面我們羅列在主分片或複製分片上檢索一個文件必要的順序步驟:
1、客戶端給 Node 1傳送get請求。
2、節點使用文件的_id確定文件屬於分片0。分片0對應的複製分片在三個節點上都有。此時它轉發請求到Node 2。
3、Node 2 返回 endangered給 Node 1然後返回給客戶端。
對於讀請求,為了平衡負載,請求節點會為每個請求選擇不同的分片——它會迴圈所有分片副本。
可能的情況是,一個被索引的文件已經存在於主分片上卻還沒來得及同步到複製分片上。這時複製分片會報告文件未找到,主分片會成功返回文件。一旦索引請求成功返回給使用者,文件則在主分片和複製分片都是可用的。
- 區域性更新文件
update API結合了之前提到的讀和寫的模式。
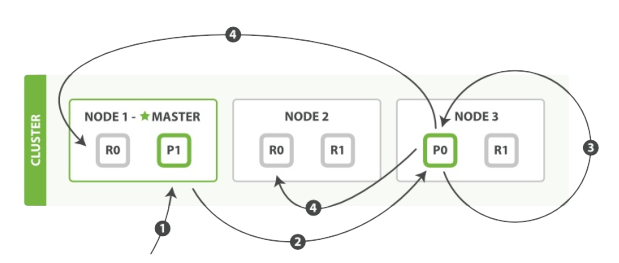
下面我們羅列執行區域性更新必要的順序步驟:
1、客戶端給Node 1傳送更新請求。
2、它轉發請求到主分片所在節點Node 3。
3、Node 3 從主分片檢索出文檔,修改_source欄位的JSON,然後在主分片上重建索引。如果有其他程序修改了文件,它以retry_on_conflict設定的次數重複步驟3,都未成功則放棄。
4、如果Node 3 成功更新文件,它同時轉發文件的新版本到Node 1 和 Node 2上的複製節點以重建索引。當所有複製節點報告成功,Node 3 返回成功給請求節點,然後返回給客戶端。
update API還接受routing、replication、consistency和timeout引數。
注:基於文件的複製,當主分片轉發更改給複製分片時,並不是轉發更新請求,而是轉發整個文件的新版本。記住這些修改轉發到複製節點時非同步的,他們並不能保證到達的順序與傳送相同。如果Elasticsearch轉發的僅僅是修改請求,修改的順序可能是錯誤的,那得到的就是損壞的文件。
- 多文件模式
mget 和 bulk API與單獨的文件類似。差別是請求節點知道每個文件所在的分片。它把多文件請求拆成每個分片的對文件請求,然後轉發給每個參與的節點。
一旦接收到每個節點的應答,然後整理這些響應組合為一個單獨的響應,最後返回給客戶端。

下面我們羅列通過一個mget請求檢索多個文件的順序步驟:
1、客戶端向 Node 1 傳送 mget 請求。
2、Node 1 為每個分片構建一個多條資料檢索請求,然後轉發到這些請求所需的主分片或複製分片上。當所有回覆被接收,Node 1 構建響應並返回給客戶端。
routing引數可以被docs中的每個文件設定。
下面我們將羅列使用一個bulk執行多個create、index、delete和update請求的順序步驟:
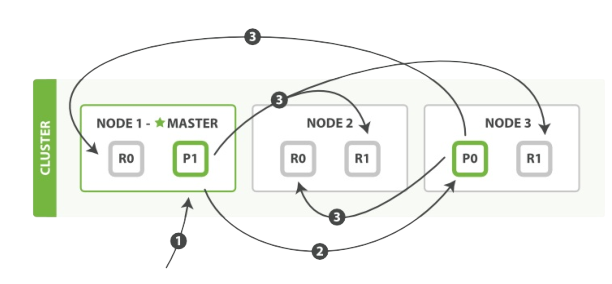
1、客戶端向Node 1 傳送 bulk請求。
2、Node 1為每個分片構建批量請求,然後轉發到這些請求所需的主分片上。
3、主分片一個接一個的按序執行操作。當一個操作執行完,主分片轉發新文件(或者刪除部分)給對應的複製節點,然後執行下一個操作。複製節點為報告所有操作完成,節點報告給請求節點,請求節點整理響應並返回給客戶端。
bulk API還可以在最上層使用replication和consistency引數,routing引數則在每個請求的元資料中使用。
相關推薦
Elasticsearch之資料如何在叢集中分佈和獲取。
路由文件到分片 當你索引一個文件,它被儲存在單獨一個主分片上。Elasticsearch是如何知道文件屬於哪個分片的呢?當你建立一個新文件,它是如何知道是應該儲存在分片1還是分片2上呢? 程序不能是隨機的,因為我們將來要檢索文件。事實上,他根據
Hive之資料傾斜的原因和解決方法
資料傾斜 在做Shuffle階段的優化過程中,遇到了資料傾斜的問題,造成了對一些情況下優化效果不明顯。主要是因為在Job完成後的所得到的Counters是整個Job的總和,優化是基於這些Counters得出的平均值,而由於資料傾斜的原因造成map處理資料量的差異過大,使得這些
Android深入學習之各種隱私許可權判斷和獲取方法總結
Android深入學習之各種隱私許可權判斷和獲取方法總結 從Android SDK 23 開始, Android就改變了許可權的管理模式。對於一些涉及使用者隱私的許可權則需要使用者的授權才可以使用。在此之前,開發者只需要在AndroidManifest.xml中註冊,如網路許可權、w
Elasticsearch 之 資料索引
對於提供全文檢索的工具來說,索引時一個關鍵的過程——只有通過索引操作,才能對資料進行分析儲存、建立倒排索引,從而讓使用者查詢到相關的資訊。 本篇就ES的資料索引操作相關的內容展開: 索引操作 最簡單的用法就是指定索引操作的index索引、type型別、ID(需要區分動詞的索引和名次的索引),
做出一段資料的概率分佈和概率密度?
就是將提問所說的“關於這個隨機變數的一組資料”進行分組(至於如何分組就看實際情況了,你應該會的吧?),得到一系列的組,例如32.5-42.5,42.5-52.5………,組數就是n。觀察數以y表示,例如yi(i為下標)=28,37,……。p的值,例如:p(u<42.5)=p[y<(42
Elasticsearch之四種查詢型別和搜尋原理
Elasticsearch Client傳送搜尋請求,某個索引庫,一般預設是5個分片(shard)。 它返回的時候,由各個分片彙總結果回來。 官網API https://www.elastic.co/guide/en/elasticsea
pandas 之資料的簡單處理和排序輸出
import pandas as pd from pandas import DataFrame, Series #要排序,需新增 data_4= pd.read_csv('(result-4)句網綜合-pandas.csv',usecols=[0,3],heade
資料結構中排序和查詢各種時間複雜度
(1)氣泡排序 氣泡排序就是把小的元素往前調或者把大的元素往後調。比較是相鄰的兩個元素比較,交換也發生在這兩個元素之間。所以相同元素的前後順序並沒有改變,所以氣泡排序是一種穩定排序演算法。 (2)選擇排序 選擇排序是給每個位置選擇當前元
Flask框架(flask中設定和獲取session)
1. session 資料是儲存到後端的資料庫中 2.session中的從狹義和廣義上分: (1)session,廣義上 : 是一種機制:在前端當中存一個session_id ,在後端當中去儲存
R語言開發之平均值,中位數和眾數了解下
R中的統計分析通過使用許多內建函式來執行的,這些函式大部分是R基礎包的一部分,並且它們將R向量與引數一起作為輸入,並在執行計算後給出結果。 先來看如何求平均值。 平均值是通過取數值的總和併除以資料序列中的值的數量來計算,函式mean()用於在R中計算平均值,語法如下:
Java泛型應用之打造Android中ListView和GridView萬能介面卡【CommonAdapter】--超簡潔寫法
在android中使用最多的就是ListView,GridView,用到這兩個控制元件那麼肯定要用到介面卡,那就是定義一個類繼承BaseAdapter,讓後覆寫它裡面的getCount()
在大資料學習中Hadoop和Spark哪個更好就業?
一提到大資料,人們就會想到Hadoop,然而,最近又有個Spark似乎成了後起之秀,也變得很火,似乎比Hadoop更具優勢,更有前景,那麼,想要學習大資料的學員就要問了,在大資料學習中Hadoop和Spark哪個更好就業? 其實正如學員們所瞭解的那樣,Spark的確是大
UDP之資料報校驗和
由於目前很多網絡卡裝置是支援對L4層資料包進行校驗和的計算和驗證的,所以在L4協議軟體的實現中,會根據網絡卡的支援情況作不同的處理,為此核心在struct sk_buff結構和struct net_device中增加了校驗和相關的引數,如下: struct sk
Java面試題總結之資料結構、演算法和計算機基礎(劉小牛和絲音的愛情故事1)
Java面試題總結之資料結構、演算法和計算機基礎(劉小牛和絲音的愛情故事1)mp.weixin.qq.com 全文字數: 1703 閱讀時間: 大約6 分鐘 劉小牛是一名Java程式設計師,
微信小程式中資料的儲存和獲取
/儲存資料 try { wx.setStorageSync('key',this.data.radioCheckVal2) //key表示data中的引數
Linux 中檔案和資料夾獲取 MySQL 許可權(SELinux)
今天在 Linux 系統上移動 MySQL 的資料庫目錄 配置如下: /etc/my.cnf [mysqld]datadir=/home/mysqlsocket=/var/lib/mysql/mysql.sock 更改完配置檔案重啟MYSQL的時候出現
資料結構和演算法之——散列表中
散列表的查詢效率並不能籠統地說成是 ,它和雜湊函式、裝載因子、雜湊衝突等都有關係。如果雜湊函式設計得不好,或者裝載因子過高,都可能會導致雜湊衝突發生的概率升高,查詢效率下降。 1. 如何設計雜湊函式? 雜湊函式設計的好壞,決定了雜湊衝突發生的概率,也直接決定了散列表的效能。那什麼才是好的雜湊函式
TensorFlow走過的坑之---資料讀取和tf中batch的使用方法
首先介紹資料讀取問題,現在TensorFlow官方推薦的資料讀取方法是使用tf.data.Dataset,具體的細節不在這裡贅述,看官方文件更清楚,這裡主要記錄一下官方文件沒有提到的坑,以示"後人"。因為是記錄踩過的坑,所以行文混亂,見諒。 I 問題背景 不感興趣的可跳過此節。 最近在研究ENAS的程式
資料結構之線索二叉樹的前序,中序和後序遍歷
BinaryTree線索化二叉樹> 二叉樹是一種非線性結構,在之前實現的二叉樹遍歷中不管是遞迴還是非遞迴用二叉樹作為儲存結構時只能取到該結點的左孩子和右孩子,不能得到該結點的前驅和後繼。為了儲存這種在遍歷中需要的資訊,同時也為了充分利用結點中的空指標域,我們
Redis——10叢集—— 10.1Redis叢集之資料分佈理論
10.1.1 資料分佈理論分散式資料庫首先要解決把整個資料集按照分割槽規則對映到多個節點的問題, 即把資料集劃分到多個節點上, 每個節點負責整體資料的一個子集。如圖10-1所示。需要重點關注的是資料分割槽規則。 常見的分割槽規則有雜湊分割槽和順序分割槽兩種, 表10-1對這兩