
馬爾科夫鏈隨機文字生成器
說明:
有一種基於馬爾可夫鏈演算法的隨機文字生成方法,它利用任何一個現有的某種語言的文字(如一本英文小說),可以構造出由這個文字中的語言使用情況而形成的統計模型,並通過該模型生成的隨機文字將具有與原文字類似的統計性質(即具有類似寫作風格)。
該演算法的基本原理是將輸入看成是由一些互相重疊的短語構成的序列,其將每個短語分割為兩個部分:一部分是由多個詞構成的字首,另一部分是隻包含一個詞的字尾。在生成文字時依據原文字的統計性質(即字首確定的情況下,得到所有可能的字尾),隨機地選擇某字首後面的特定字尾。在此,假設字首長度為兩個單詞,則馬爾可夫鏈(Markov Chain)隨機文字生成演算法如下:
設w1和w2為文字的前兩個詞
輸出w1和w2
迴圈:
隨機地選出w3,它是原文字中w1w2為字首的字尾中的一個
輸出w3
w1 = w2
w2 = w3
重複迴圈
下面將通過一個例子來說明該演算法原理,假設有一個原文如下:
Show your flowcharts and conceal your tables and I will be mystified. Show your tables and your flowcharts will be obvious.
下面是上述原文的一些字首和其後綴(注意只是部分)的統計:
| Prefix |
Suffix |
| Show your |
flowcharts tables |
| your flowcharts |
and will |
| flowcharts and |
conceal |
| flowcharts willl |
be |
| your tables |
and and |
| will be |
mystified. obvious. |
| be mystified. |
Show |
| be obvious. |
(end) |
基於上述文字,按照馬爾可夫鏈(Markov Chain)演算法隨機文字生成文字時,首先輸出的是Show your,然後隨機取出flowcharts或tables。如果為前者,則接下來的字首就變成your flowcharts,而下一個字尾應該是and或will;如果為tables,則接下來的字首就變成your tables,而下一個詞就應該是and。這樣繼續下去,直到產生出足夠多的輸出,或在查詢字尾時遇到了結束標誌。
編寫一個程式從檔案中讀入一個英文文字,利用馬爾可夫鏈(Markov Chain)演算法,基於文字中固定長度的短語的出現頻率,生成一個最大單詞數目不超過N的新文字到給定檔案中。程式要求字首詞的個數為2,最大單詞數目N由標準輸入獲得。
說明:
- 為了得到更好的統計特性,在此標點符號等非字母字元(如’ “ . , ? – ()等)也被看成單詞的一部分,即“words”和“words.”是不同的單詞。因此,在此將“詞”定義為由“空白界定的字串”;
- 對於同一個字首的字尾按出現順序排放(不管該字尾是否已存在);
- 在處理文字時,檔案結束標誌也將作為某一字首的一個字尾,如上面示例(說明:在為檔案最後兩個字首單詞“be obvious.”讀取字尾時,遇到檔案結束,即其沒有相應字尾,此時可用一個特殊標記來表示其後綴,如,可儲存一個自定義的特殊串(如“(end)”)作為其後綴來表示當前狀態,即檔案結束);
- 對於某一字首,按如下方式來隨機選擇其後綴(如果某一字首只有一個字尾,將直接選擇該字尾):
n = (int)(rrand() * N);
在此N為某一字首的所有後綴的總數,n為所確定的字尾在該字首的字尾序列中的序號(從0開始計數,即n為0時選取第一個字尾,為1時選取第二個字尾,以此類推)。在此,隨機數生成函式rrand()的定義如下:
double seed = 997; double rrand() { double lambda = 3125.0; double m = 34359738337.0; double r; seed = fmod(lambda*seed, m); //要包含標頭檔案#include <math.h> r = seed/ m; return r; }
注意:為了保證執行結果的確定性,請務必使用本文提供的隨機數生成函式。
在下面條件滿足時文字生成結束:1)遇到字尾為檔案結束標誌;或2)生成文字的單詞數達到所設定的最大單詞數。在程式實現時,當讀到檔案(結束)尾時,可將一個特殊標誌賦給字尾串suffix變數。
【輸入形式】
建立英文文字檔案“article.txt”進行統計分析,並從標準輸入中讀入一個正整數作為生成文字時的最大單詞數。
【輸出形式】
將生成文字輸出到當前目錄下檔案“markov.txt”中。單詞間以一個空格分隔,最後一個單詞後空格可有可無。
【樣例輸入】
若當前目錄下檔案article.txt中內容如下:
I will give you some advice about life.
Eat more roughage;
Do more than others expect you to do and do it pains;
Remember what life tells you;
do not take to heart every thing you hear.
do not spend all that you have.
do not sleep as long as you want;
Whenever you say "I love you", please say it honestly;
Whevever you say "I am sorry", please look into the other person's eyes;
Whenever you find your wrongdoing, be quick with reparation!
Whenever you make a phone call smil when you pick up the phone, because someone feel it!
Understand rules completely and change them reasonably;
Remember, the best love is to love others unconditionally rather than make demands on them;
Comment on the success you have attained by looking in the past at the target you wanted to achieve most;
In love and cooking, you must give 100% effort - but expect little appreciation.
從標準輸入中輸入的單詞個數為:
1000
【樣例輸出】
當前目錄下所生成的檔案markov.txt中內容如下:
I will give you some advice about life. Eat more roughage; Do more than others expect you to do and do it pains; Remember what life tells you; do not take to heart every thing you hear. do not take to heart every thing you hear. do not spend all that you have. do not sleep as long as you want; Whenever you find your wrongdoing, be quick with reparation! Whenever you find your wrongdoing, be quick with reparation! Whenever you find your wrongdoing, be quick with reparation! Whenever you find your wrongdoing, be quick with reparation! Whenever you say "I am sorry", please look into the other person's eyes; Whenever you say "I am sorry", please look into the other person's eyes; Whenever you make a phone call smil when you pick up the phone, because someone feel it! Understand rules completely and change them reasonably; Remember, the best love is to love others unconditionally rather than make demands on them; Comment on the success you have attained by looking in the past at the target you wanted to achieve most; In love and cooking, you must give 100% effort - but expect little appreciation.
【樣例說明】
按照本文介紹的馬爾可夫鏈(Markov Chain)演算法將生成相關輸出檔案。
【使用什麼資料結構?】
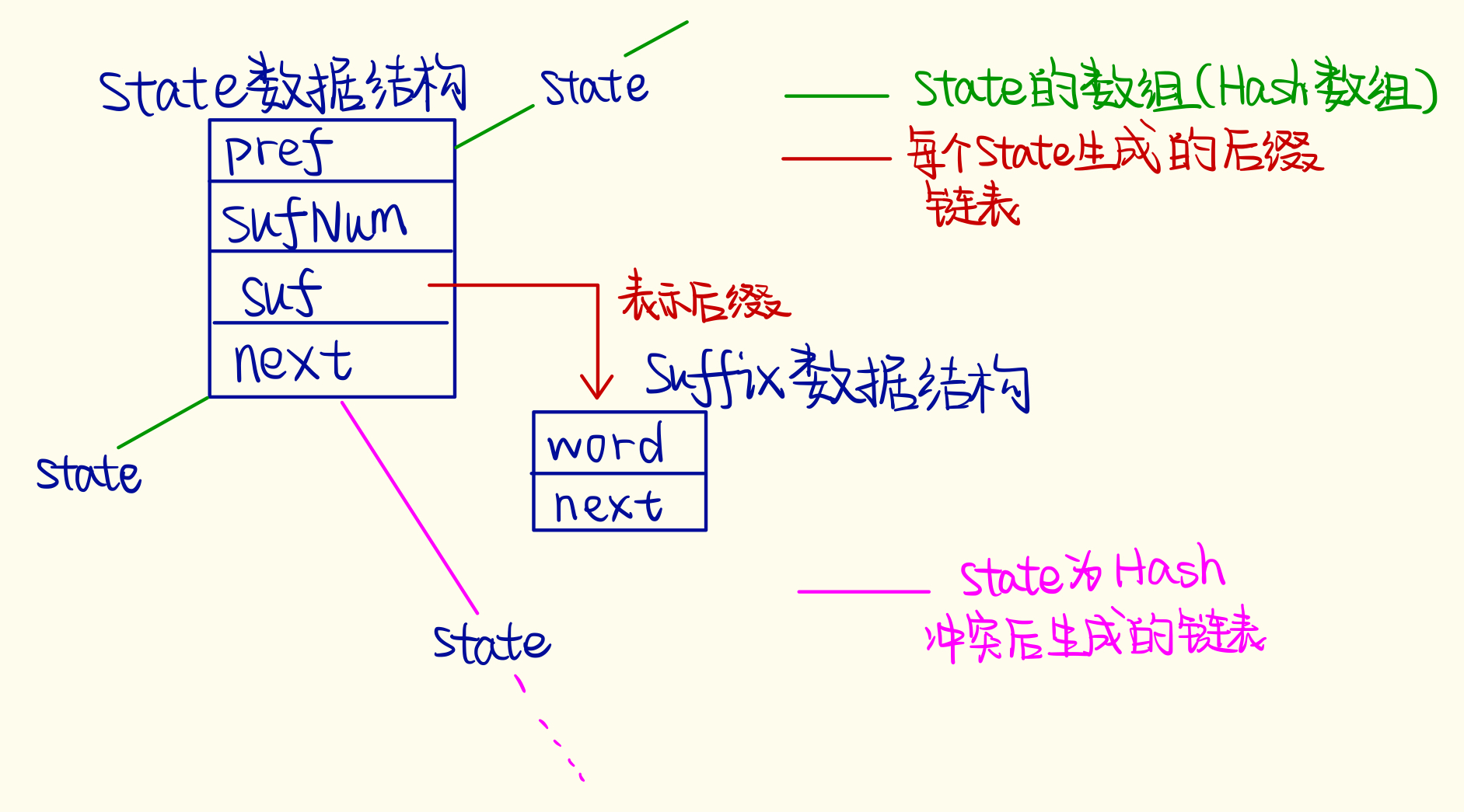
使用如上圖所示的資料結構,建立一個數據結構State儲存狀態和一個字尾連結串列Suffix,這樣建立資料結構的原因是每通過hash找到一個字首pref的State,就可以通過這個這個State的suf連結串列尋找隨機生成的字尾,另外為了加快速度也可以用二叉搜尋樹代替這個這個suf字尾連結串列。這裡為了加快速度用了一些技巧,就是在State加了一個變數SufNum,這個變數的目的就是使插入的時候不用按照傳統連結串列插入到末尾這種方法,而是直接在頭部插入,讀取的時候通過(SufNum-the_index_you_want)次next操作就可以找到所需要的字尾Suf了。
說起來很簡單,但實現起來還是十分的困難,作者在程式碼里加了兩個C語言常用的函式memcpy和strdup
以下是 memcpy() 函式的宣告。
void *memcpy(void *str1, const void *str2, size_t n)
引數
str1 -- 這是指標陣列,其中的內容將被複制到目標,型別強制轉換為void*型別的指標。
str2 -- 這是要複製的資料來源的指標,void*型別的指標型鑄造。
n -- 這是要被複制的位元組數。
返回值
這個函式返回一個指標到目的地,str1。
可參考網址 http://www.cplusplus.com/reference/cstring/memcpy/
Example Code:
#include <stdio.h> #include <string.h> int main () { const char src[50] = "test"; char dest[50]; printf("Before:%s\n", dest); memcpy(dest, src, strlen(src)+1); printf("After: %s\n", dest); return(0); }
結果:
Before:
After: test
而strdup是個字串的複製,這個函式會單獨alloc一塊新的記憶體,不像strcpy函式一樣需要自己準備兩個記憶體。
呼叫之後需要用free()函式釋放掉。
#include <string.h> #include <assert.h> #include <stdlib.h> int main(void) { const char *s1 = "String"; char *s2 = strdup(s1); assert(strcmp(s1, s2) == 0); free(s2); }
部分函式還使用了inline行內函數
inline函式優點:
傳統程式的函式呼叫需要不停的呼叫棧,當有函式需要頻繁呼叫的時候,那就會導致棧溢位或者效率不高等其他問題,用inline函式相當於把函式原始碼直接“嵌入”到函式呼叫點
inline函式缺點:
如果呼叫inline函式的地方過多,也可能造成程式碼膨脹。
有了如上基礎之後我們可以從建立State的hash表,然後編寫增加字尾函式和查詢函式,就可以實現馬爾可夫鏈隨機文字的生成了。
這裡的hash方法使用的是NHASH為5000011的BKDR演算法,寫有很多效率更高的方法,可以上網去尋找替代。
博主的程式碼:
1 #include <math.h> 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <string.h> 5 const int NHASH = 5000011; 6 const int PREFIX_NUM = 2; 7 typedef struct State State; 8 typedef struct Suffix Suffix; 9 struct State { 10 char *pref[PREFIX_NUM]; 11 Suffix *suf; 12 State *next; 13 unsigned int sufNum; 14 }; 15 struct Suffix { 16 char *word; 17 Suffix *next; 18 }; 19 State *statetab[NHASH]; 20 21 /*利用了BKDR HASH方法,這裡還可以使用別的HASH方法減少衝突*/ 22 unsigned int hash(char *s[PREFIX_NUM]) { 23 unsigned int seed = 131; 24 unsigned int hash = 0; 25 unsigned int i; 26 for (i = 0; i < PREFIX_NUM; i++) { 27 char *str = s[i]; 28 while (*str) 29 hash = hash * seed + (*str++); 30 } 31 return hash % NHASH; 32 } 33 34 /*查詢字首陣列prefix[PREFIX_NUM]是否在雜湊表中出現*/ 35 State *lookup(char *prefix[PREFIX_NUM], int isBuild) { 36 /*If isBuild is true,it will be a new node*/ 37 int i, h; 38 h = hash(prefix); 39 State *sp = statetab[h]; 40 while (sp != NULL) { 41 for (i = 0; i < PREFIX_NUM; ++i) { 42 if (strcmp(prefix[i], sp->pref[i])) 43 break; 44 } 45 if (i == PREFIX_NUM) //找到了就返回 46 return sp; 47 sp = sp->next; 48 } 49 if (isBuild) { 50 sp = malloc(sizeof(State)); 51 for (i = 0; i < PREFIX_NUM; ++i) { 52 sp->pref[i] = prefix[i]; 53 } 54 sp->suf = NULL; 55 sp->sufNum = 0; 56 sp->next = statetab[h]; //頭插法 57 statetab[h] = sp; 58 } 59 return sp; 60 } 61 62 /*直接在頭結點插入字尾,減少插入時間*/ 63 State *addsuffix(State *sp, char *suffix); 64 inline State *addsuffix(State *sp, char *suffix) { 65 Suffix *suf = malloc(sizeof(Suffix)); 66 suf->word = suffix; 67 suf->next = sp->suf; 68 sp->sufNum++; 69 sp->suf = suf; 70 return sp; 71 } 72 73 /*往資料結構中插入一個新的項,使用inline行內函數加快速度*/ 74 void add(char *prefix[PREFIX_NUM], char *suffix); 75 inline void add(char *prefix[PREFIX_NUM], char *suffix) 76 { 77 State *sp = NULL; 78 sp = lookup(prefix, 1); 79 sp = addsuffix(sp, suffix); 80 // memmove(prefix, prefix + 1, sizeof(prefix[0])); 81 memcpy(prefix, prefix + 1, sizeof(prefix[0])); 82 prefix[1] = suffix; 83 } 84 85 double seed = 997; 86 87 /*如上面所要求的隨機生成器*/ 88 double rrand() { 89 double lambda = 3125.0; 90 double m = 34359738337.0; 91 double r; 92 seed = fmod(lambda * seed, m); //要包含標頭檔案#include <math.h> 93 r = seed / m; 94 return r; 95 } 96 97 void build(char *prefix[PREFIX_NUM], FILE *f); 98 inline void build(char *prefix[PREFIX_NUM], FILE *f) { 99 char buf[40]; 100 while (fscanf(f, "%39s", buf) != EOF) { 101 add(prefix, strdup(buf)); 102 } 103 } 104 105 /*從這裡生成markov鏈*/ 106 void generate(int nwords, FILE *OUT) { 107 State *sp; 108 char *prefix[PREFIX_NUM], *w; 109 unsigned int i; 110 for (i = 0; i < PREFIX_NUM; ++i) 111 prefix[i] = "\0"; 112 113 for (i = 0; i < nwords; ++i) { 114 sp = lookup(prefix, 0); 115 Suffix *suf = sp->suf; 116 if (sp->sufNum == 1) { 117 w = suf->word; 118 } else { 119 int n = sp->sufNum - (int)(rrand() * sp->sufNum) - 1; 120 while (suf != NULL) { 121 if (n == 0) { 122 w = suf->word; 123 break; 124 } 125 suf = suf->next; 126 n--; 127 } 128 } 129 if (strcmp(w, "(end)") == 0) 130 break; 131 fprintf(OUT, "%s ", w); 132 memcpy(prefix, prefix + 1, (PREFIX_NUM - 1) * sizeof(Suffix)); 133 // strcpy(prefix[0], prefix[1]); 134 prefix[1] = w; 135 } 136 } 137 138 int main() { 139 unsigned long int nwords; 140 unsigned int i; 141 scanf("%lu", &nwords); 142 char *prefix[PREFIX_NUM]; 143 for (i = 0; i < PREFIX_NUM; ++i) 144 prefix[i] = "\0"; 145 FILE *in = fopen("article.txt", "r"); 146 build(prefix, in); 147 fclose(in); 148 /*末尾處加(end)*/ 149 add(prefix, "(end)"); 150 FILE *out = fopen("markov.txt", "w"); 151 generate(nwords, out); 152 fclose(out); 153 return 0; 154 }