
hdfs基礎知識整理
(1)HDFS為什麼會塊那麼大?
其目的是減少定址的開銷
(2)HDFS的塊抽象帶來的好處
1.檔案中所有的塊並不需要儲存在同一個磁碟中,因此他可以利用任意一個磁碟進行儲存,一個大檔案就可以拆分成很多個小檔案存放在不同的磁碟中。
2.大大簡化了儲存子系統的設計,很容易就可以計算出塊的個數,元資料大小不一不方便fsImage的管理。
3.如果一個塊不可用了,馬上可以從相關的檔案中複製過去,對使用者是透明的,檔案馬上會回到正常數量。
(3)塊快取
通常datanode從一個磁碟中訪問檔案,對於訪問比較頻繁的資料會被顯示儲存在datanode的快取中,一個塊僅在一個datanode的記憶體中。使用者或應用通過在快取池(cache pool)中增加一個cache directive來告訴namenode需要快取的哪些檔案及快取多久,快取池是一個用於管理快取許可權和資源使用的管理型分組/
(4)聯邦HDFS
一個namenode可能管理/user下的所有檔案,而另一個namenode可能管理/share寫的所有檔案(/user,/share都是namenode配置檔案目錄),多個namenode共同管理HDFS,某一個namenode失效也不會影響其他namenode。
(5)HDFS的高可用性
如果namenode失效了,可能導致所有的客戶端,包括,mapreduce作業都無法正常讀寫或舉例檔案。而且系統恢復時間太長也會影響到日常維護。
Hadoop2針對以上問題增加了HDFS的高可用性的支援。
(1)配置備用的namenode,當活動的namenode失效時,備用的namenode會自動接管並開始服務,不會有明顯的的中斷。
(2)目前有兩種高可用性共享儲存:NFS過濾器或群體日誌管理器。
(3)QJM(quorum journal manager)是一個專用的HDFS實現,為提供一個高可用的編輯器而設計,被推薦用於大多數HDFS部署中。QJM以一組日誌節點的形式執行,每一次編輯必須寫入多數日誌節點。典型的,有三個journal節點,所以系統能夠忍受其中任何一個丟失。這種安排與zookeeper的工作方式類似,當然必須認識到,QJM的實現並沒有使用Zookeeper。
HDFS的故障切換與規避
(1)系統中有一個稱之為故障轉移控制器(failover controller)的新實體,管理著將活動namenode轉移為備用namenode的轉移過程。預設的是一種使用了zookeeper來確保有且僅有一個活動的namenode。
(2)在網速非常慢,或者網路被分割的情況下,同樣也可能激發故障轉移,但是先前的活動的namenode依舊是活動的namenode,高可用實現做了更進一步的優化,以確保先前活動的namenode不會執行危害系統並導致奔潰的操作,該方法稱之為“規避”。
QJM與NFS過濾器的區別
QJM僅允許一個namenode像編輯日誌寫入資料,然而,對於先前的活動namenode而言,仍有可能響應並處理客戶過時的請求,因此,設定一個SSH規避命令來殺死namenode的程序是一個好主意。當使用NFS過濾器實現共享編輯日誌時,由於不可能同一時間只允許一個namenode寫入資料(這也是為什麼推薦QJM的原因),因此需要更有力的規避方法。規避機制包括:撤銷namenode訪問共享儲存目錄的許可權等。
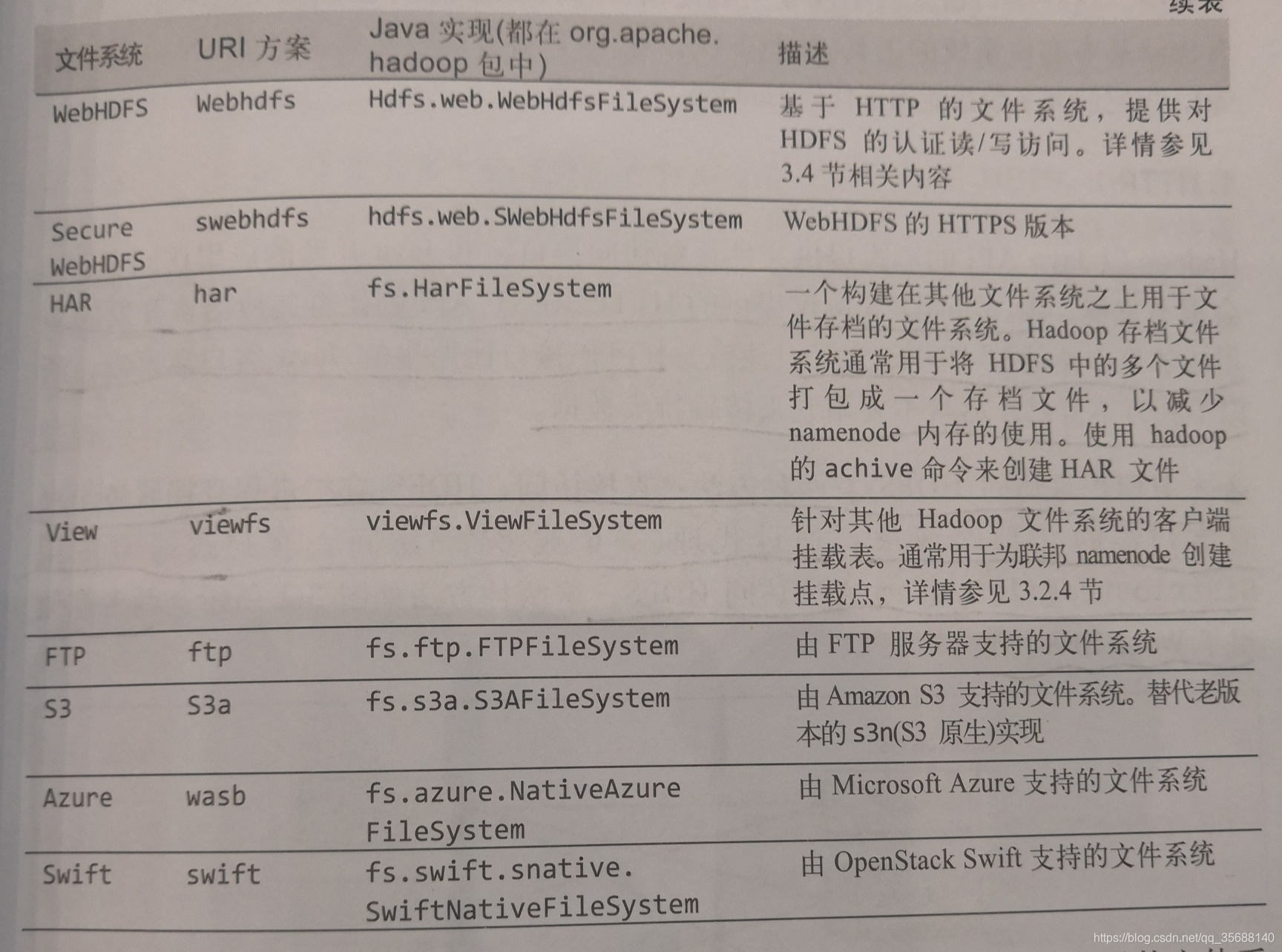
(6)Hadoop檔案系統
(1)hadoop中的檔案系統:

(2)非java程式訪問HDFS
Hadoop以java API的形式提供檔案系統的訪問介面,非java開發的應用訪問非常不方便。由WebHDFS協議提供了HTTP REST API介面,使得其他語言可以與HDFS互動。
注:HTTP介面比原生的Java客戶端要慢,所以不到萬不得已,儘量不要用它來傳輸特大資料。
HTTP訪問HDFS的兩種方法:直接使用HDFS的守護程序服務與來自HTTP的請求;通過代理的方式實現訪問,客戶端通常使用DistributedFileSystem API訪問HDFS。這兩者都使用了WebHDFS協議。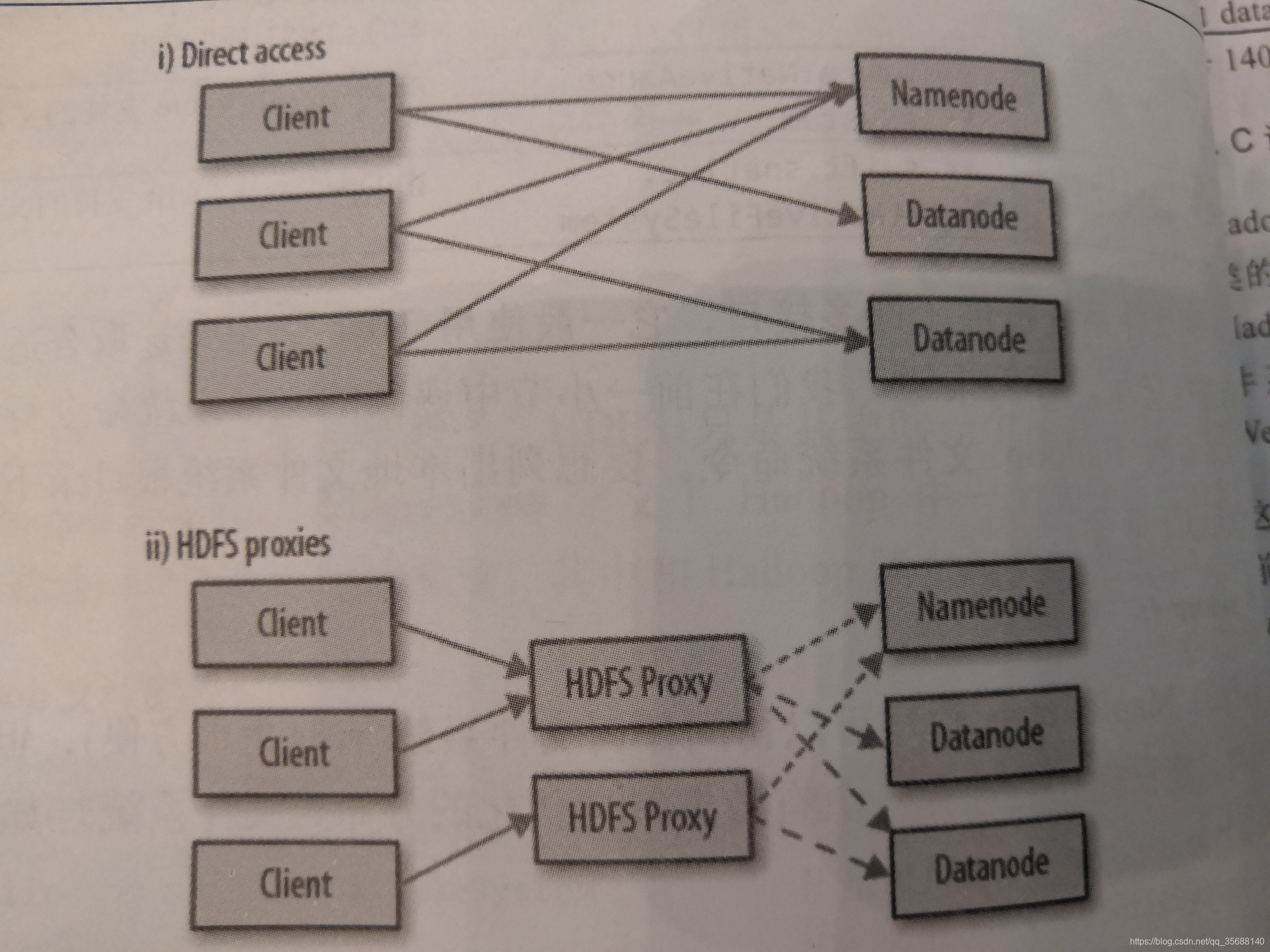
第一種情況,namenode和datanode內嵌的web伺服器作為WebHDFS的端點執行(dfs.webhdfs.enabled設定為true,WebHDFS預設是啟動的)檔案元資料由namenode管理。
第二種情況依靠獨立的代理伺服器通過HTTP訪問HDFS。通常情況下,代理伺服器,是現在不同資料中心部署的Hadoop叢集之間的資料傳輸,或從外部網路訪問雲端執行的Hadoop叢集。
HttpFS代理提供和WebHDFS相同的HTTP(和HTTPS)介面,客戶端可以通過webhdfsURI訪問這兩個介面類。HttpFS代理啟動獨立於namenode和datanode的守護程序,使用httpfs.sh指令碼,預設在一個不同的埠上監聽(埠號14000)。
(7)HDFS的API之FSDataInputStream讀取資料
(1)FSDataInputstream繼承了java.io.DataInputStream,支援隨機訪問,可以從任意的位置讀取資料。呼叫seek()來定位大於檔案長度會引發IOException,與java.io.DataInputStream中的skip()不同,seek()可以移到檔案中的任意一個絕對位置,skip()則只能相當於當前位置到另一個位置(相對位置)。

(2)FSDataInputStream類也實現了PositionedReadable介面,從一個指定偏移量處讀取檔案的一部分:
public interface PositionedReadable {
int read(long var1, byte[] var3, int var4, int var5) throws IOException;
void readFully(long var1, byte[] var3, int var4, int var5) throws IOException;
void readFully(long var1, byte[] var3) throws IOException;
}
read()方法從檔案的指定position處讀取至多為length位元組的資料並快取至buffer的指定偏移量offset。返回值實際上是讀到的位元組數。(返回值可能小於指定的length)
length長度的位元組數資料讀取到buffer’中(或在只接受buffer位元組陣列的版本中,讀取buffer.length長度位元組資料),除非已經讀到了檔案末尾,這種情況下將丟擲EOFException異常。
注意:seek()方法是一個相對高開銷的操作,需要慎重使用,建議用流資料來構建應用的訪問模式(比如mapreduce),而非執行大量seek()方法。
(8)HDFS的API之FileSystem寫入資料
(1)最簡單的方法就是指定一個Path,返回一個用於寫入資料的流:
public FSDataOutputStream create(Path f) throws IOException
(2)過載方法Progressable用於傳遞迴調介面,可以把資料寫入datanode的進度通知應用,這個展示進度對mapreduce相當重要:
public interface Progressable {
void progress();
}
(3)另一個新建檔案的方法就是append()方法在現有的檔案末尾追加資料:
public FSDataOutputStream append(Path f) throws IOException
(9)檔案模式
大量日誌檔案中,可能用一個表示式來獲取所有的檔案(類似於正則表示式),該操作稱之為“通配”。FileSystem中的方法:
public FileStatus[] globStatus(Path pathPattern) throws IOException

例子如下:

FileSystem中的listStatus()和globStatus()方法提供了可選的PathFilter物件,globStatus會匹配Path下的檔案,PathFilter會過濾掉不想要的檔案:
public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws IOException
例項PathFilter過濾檔案:

(10)檔案讀取
讀取資料時,如果DFSInputStream在於datanode通訊時遇到錯誤,會嘗試從這個塊的另一個最近的鄰近datanode讀取資料。他會記住那個故障datanode,以保證以後不會反覆讀取該節點上後續的塊。DFSInputStream也會通過校驗和確認從datanode發來的資料是否完整。如果發現有損壞的塊,DFSInputStream會試圖從其他的datanode讀取器副本,也會將損壞的塊通知給namenode。這個設計的重點是,每次客戶端可以直接連到datanode,且namenode會告知客戶端最佳的datanode。
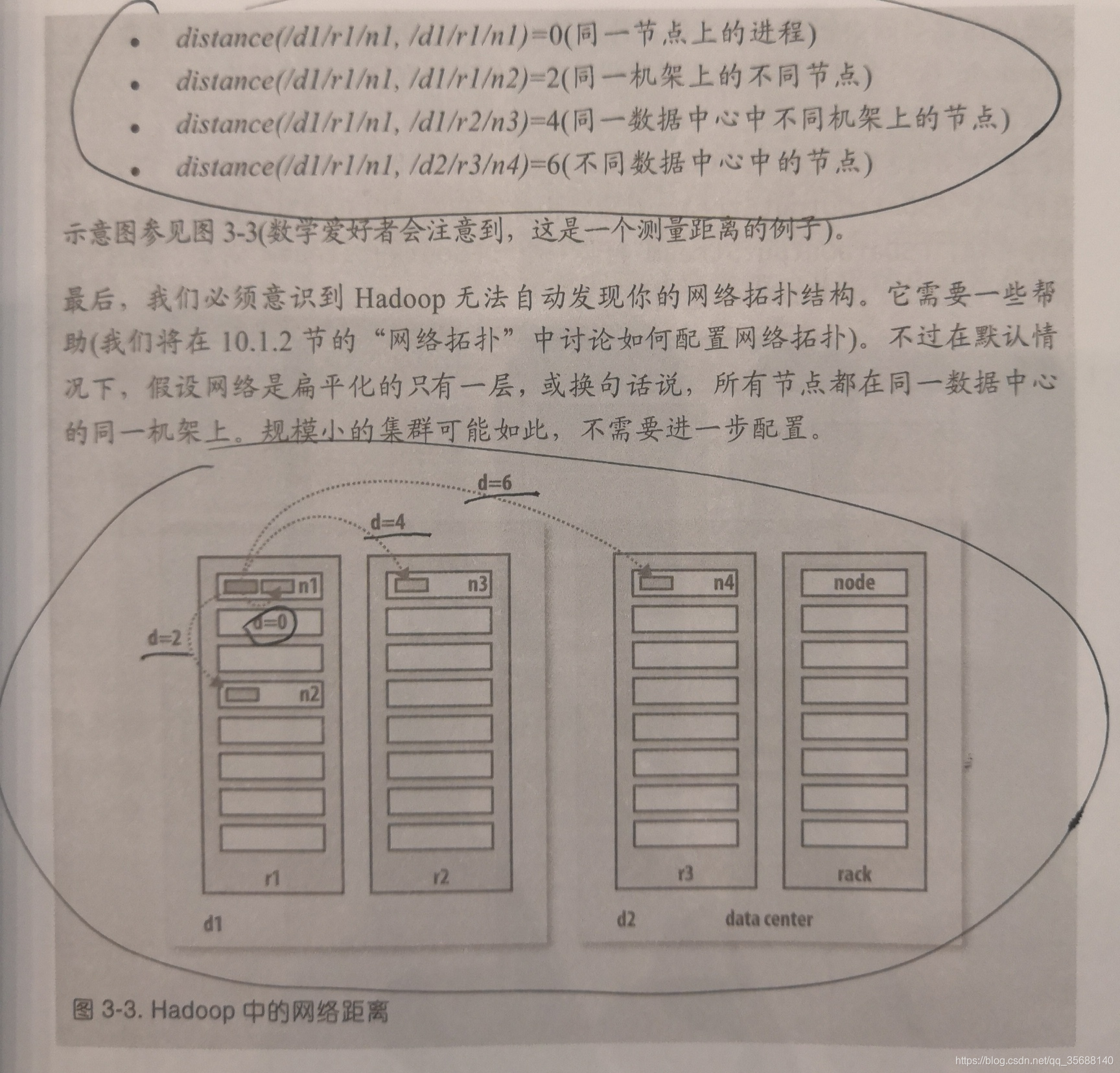
那麼上面說的“彼此臨近”到底如何解釋?

(11)檔案寫入
寫入時,DFSOutputStream將他分成一個個的資料包,並寫入內部佇列,稱之為“資料佇列”(data queue)。DataStreamer處理資料佇列,如果副本數為3,那麼它就會將資料流式分到3個管道中datanode。同時,DFSOutputStream也維護著一個內部資料佇列來等待datanode收到確認回執,稱為“確認佇列”。
如果在寫操作的過程紅,有任何的datanode發生故障
會先關閉首先建立的管道,確認佇列中所有資料包都添加回資料佇列的最前端,以確保故障節點下游的datanode不會漏掉任何一個數據包。為儲存在另一個正常的datanode的當前資料塊制定一個新的標識,並將該標識傳給namenode,以便故障datanode在恢復以後刪除儲存的部分資料塊。從管道中刪除故障的datanode,基於兩個正常的datanode構建一個新管線。餘下的資料寫入管線中正常的datanode。
在一個塊被寫入的期間可能有多個datanode同時發生故障,但非常少見,只要寫入了dfs.namenode.replication.min的複本數(預設為1),寫操作就會成功!並且這個塊可以在叢集中非同步複製,直到達到目標副本數為止(dfs.replication的預設值為3)。
寫入的檔案會產生很多副本,到底每個副本放在哪個datanode上?
Hadoop預設的策略是:
(1)在執行客戶端的節點上存放第一個副本(如果客戶端在叢集之外,就隨機選擇一個節點,不過會盡量避免儲存太滿或太忙的節點)
(2)第二個複本放在與第一個不同且隨機另外選擇的機架中節點(離架)
(3)第三個複本與第二個複本在同一個機架上的隨機其他節點上。
(4)其他複本放在叢集中隨機選擇的節點上,不過系統會盡量避免在同一個的機架上放太多複本。
資料寫入的一致性(一致模型):
(1)剛寫入的內容並不能保證立即就可以被所有的reader看到,因為資料還沒有重新整理快取並存儲。
(2)當前正在寫入的塊對其他reader是不可見的,其他的reader來讀取時,資料長度為0。當他寫完了當前塊時,就可以被其他的reader看到了。(以塊為單位)
(3)HDFS提供了一種強行將所有快取寫入到datanode中的手段,即對FSDataOutputStream呼叫hflush()方法。當hflush()方法返回成功以後,所有到達的資料全部被寫入管道,並對所有的新reader可見。
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes());
out.hflush();
//assertThat是Junit4中的一個方法,用來判斷前後的資料是否相等
assertThat(fs.getFileStatus(p).getLen(),is(((long)"content".getBytes())));
注意:hflush()不保證datanode將所有的資料寫入到磁碟,僅確保資料在datanode的記憶體中(如果出現立即斷電,資料丟失),為確保資料寫入到了磁碟上,可以使用hsync()代替。
out.close()中其實隱含了hflush();
(4)hsync()操作類似於Java API資料寫入本地檔案,我們可以利用重新整理資料流且同步之後看到檔案內容一樣。
FileOutputStream out = new FileOutputStream("1");
out.write("content".getBytes());
out.flush();//重新整理到記憶體
out.getFD().sync();//同步到磁碟
注:hflush()的呼叫可以減少資料的丟失的可能性,但是也會增加額外的開銷(hsync()開銷更大)。所以在資料的魯棒性和吞吐量之間會有所取捨,將hflush()的呼叫保持在一個合適的頻率。
通過distcp並行複製
為了實現多執行緒對一組檔案的並行處理,Hadoop提供了一個distcp,該程式可以並行從hadoop檔案系統中複製大量資料,也可以將大量的資料複製到hadoop中。
將file1中的檔案複製到file2中:
% hadoop distcp file1 file2
關鍵字-overwrite強制覆蓋原有檔案
如果檔案file1中的內容修改,我們可以用命令同步到file2中:
% hadoop distcp -updata file1 file2
(1)distcp是作為一個Mapreduce作業來實現的,該複製公國是通過叢集中並行執行的map完成的。這裡沒有reduce。
(2)預設情況下,將近20個map被使用,但是可以通過distcp指定的-m來修改map的數量。
(3)關於distcp的一個常見的使用例項是在兩個HDFS叢集間傳送資料,例如,以下命令在第二個叢集上為第一個叢集/foo目錄建立一個備份:
hadoop distcp -updata -delete -p hdfs://namenode1/foo hadfs://namenode2/foo
-delete選項使得distcp可以刪除目標路徑中任意沒在原路徑中出現的檔案或目錄,-p表示檔案的狀態屬性(如:許可權、塊大小、複本數)被保留。
(4)如果兩個叢集執行的是HDFS的不相容版本,你可以將webhdfs協議用於他們之間的distcp:
hadoop distcp webhdfs://namenode1:50070/foo webhdfs://namenode2:50070/foo
批註:另一個變種是使用HttpFs代理作為distcp源或者目標,這樣的優點是可以設定防火牆和控制頻寬。
注意:如果想保持HDFS的負載均衡,最好不要讓distcp用-m指定1,這樣他的任務由一個map執行,對該map所在的datanode影響較大,多個map可以緩解這種負載不均衡的現象,但也無法避免,最好使用預設的20個map即可。當然可以運用工具來控制叢集中的塊分佈的均勻程度來進一步緩解這種負載不均衡的現象。