
oracle優化技巧
一、編碼習慣以及技巧
1、SELECT子句中避免使用 " * ":
ORACLE在解析的過程中, 會將"*" 依次轉換成所有的列名, 這個工作是通過查詢資料字典完成的, 這意味著將耗費更多的時間。
2、sql語句用大寫的:
因為oracle總是先解析sql語句,把小寫的字母轉換成大寫的再執行。
3、WHERE子句中的連線順序:
ORACLE採用自下而上的順序解析WHERE子句,根據這個原理,表之間的連線必須寫在其他WHERE條件之前, 那些可以過濾掉最大數量記錄的條件必須寫在WHERE子句的末尾。
4、儘量多使用COMMIT:
只要有可能,在程式中儘量多使用COMMIT
COMMIT所釋放的資源:
a. 回滾段上用於恢復資料的資訊.
b. 被程式語句獲得的鎖
c. redo log buffer 中的空間
d. ORACLE為管理上述3種資源中的內部花費
5、用TRUNCATE替代DELETE:
當刪除表中的記錄時,在通常情況下, 回滾段(rollback segments ) 用來存放可以被恢復的資訊. 如果你沒有COMMIT事務,ORACLE會將資料恢復到刪除之前的狀態(準確地說是恢復到執行刪除命令之前的狀況) 而當運用TRUNCATE時, 回滾段不再存放任何可被恢復的資訊.當命令執行後,資料不能被恢復.因此很少的資源被呼叫,執行時間也會很短. (譯者按: TRUNCATE
TRUNCATE是DDL不是6、用EXISTS替代IN、用NOT EXISTS替代NOT IN:
在許多基於基礎表的查詢中,為了滿足一個條件,往往需要對另一個表進行聯接.在這種情況下, 使用EXISTS(或NOT EXISTS)通常將提高查詢的效率. 在子查詢中,NOT IN子句將執行一個內部的排序和合並. 無論在哪種情況下,NOT IN都是最低效的 (因為它對子查詢中的表執行了一個全表遍歷). 為了避免使用NOT IN ,我們可以把它改寫成外連線(Outer Joins)或NOT EXISTS.
例子:
(高效)
SELECT * FROM EMP ( (低效)
SELECT * FROM EMP (基礎表) WHERE EMPNO > 0 AND DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE
7、用EXISTS替換DISTINCT:
當提交一個包含一對多表資訊(比如部門表和僱員表)的查詢時,避免在SELECT子句中使用DISTINCT. 一般可以考慮用EXIST替換, EXISTS使查詢更為迅速,因為RDBMS核心模組將在子查詢的條件一旦滿足後,立刻返回結果. 例子:
(低效):
SELECT DISTINCT DEPT_NO,DEPT_NAME FROM DEPT D , EMP E
WHERE D.DEPT_NO = E.DEPT_NO
(高效):
SELECT DEPT_NO,DEPT_NAME FROM DEPT D WHERE EXISTS (SELECT 'X'
FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO);
8、避免在索引列使用not,is null ,is not null ,以及使用計算。
9、用>= 替代>
10、用UNION替換OR (適用於索引列)
通常情況下, 用UNION替換WHERE子句中的OR將會起到較好的效果. 對索引列使用OR將造成全表掃描. 注意, 以上規則只針對多個索引列有效. 如果有column沒有被索引, 查詢效率可能會因為你沒有選擇OR而降低. 在下面的例子中, LOC_ID 和REGION上都建有索引.
高效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE REGION = “MELBOURNE”
低效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你堅持要用OR, 那就需要返回記錄最少的索引列寫在最前面.
11、用in 替換or 。
12、總是使用索引的第一個列:
如果索引是建立在多個列上, 只有在它的第一個列(leading column)被where子句引用時,優化器才會選擇使用該索引. 這也是一條簡單而重要的規則,當僅引用索引的第二個列時,優化器使用了全表掃描而忽略了索引
13、避免改變索引列的型別.:
當比較不同資料型別的資料時, ORACLE自動對列進行簡單的型別轉換.
假設 EMPNO是一個數值型別的索引列.
SELECT … FROM EMP WHERE EMPNO = '123'
實際上,經過ORACLE型別轉換, 語句轉化為:
SELECT … FROM EMP WHERE EMPNO = TO_NUMBER('123')
幸運的是,型別轉換沒有發生在索引列上,索引的用途沒有被改變.
現在,假設EMP_TYPE是一個字元型別的索引列.
SELECT … FROM EMP WHERE EMP_TYPE = 123
這個語句被ORACLE轉換為:
SELECT … FROM EMP WHERE TO_NUMBER(EMP_TYPE)=123
因為內部發生的型別轉換, 這個索引將不會被用到! 為了避免ORACLE對你的SQL進行隱式的型別轉換, 最好把型別轉換用顯式表現出來. 注意當字元和數值比較時, ORACLE會優先轉換數值型別到字元型別
14、需要當心的WHERE子句:
某些SELECT 語句中的WHERE子句不使用索引. 這裡有一些例子.
在下面的例子裡,
(1)‘!=’ 將不使用索引. 記住, 索引只能告訴你什麼存在於表中, 而不能告訴你什麼不存在於表中.
(2) ‘||'是字元連線函式. 就象其他函式那樣, 停用了索引.
(3) ‘+'是數學函式. 就象其他數學函式那樣, 停用了索引.
(4)相同的索引列不能互相比較,這將會啟用全表掃描.
15、建立索引,但該索引又允許為空,我們都指定 索引列 is null 會使索引失效,解決的方法是,建立索引時,增加一個常量。
如:
create index IDX_DEPT_FSTANDARDCODE on T_ORG_DEPARTMENT (FSTANDARDCODE, 0);
二、常用SQL操作
1.0 建立完整表SQL
CREATE TABLE banping
(
id NUMBER(5) CONSTRAINT banping_id_pk PRIMARY KEY,
last_name VARCHAR2(10) CONSTRAINT banping_last_name_nn NOT NULL,
first_name VARCHAR2(10) NOT NULL UNIQUE,
userid VARCHAR2(8) CONSTRAINT banping_userid_uk UNIQUE,
start_date DATE DEFAULT SYSDATE,
title VARCHAR2(10),
dept_id NUMBER(7) CONSTRAINT banping_dept_id_fk REFERENCES dept(id),
salary NUMBER(11, 2),
user_type VARCHAR2(4) CONSTRAINT banping_user_type_ck CHECK (user_type IN(
'IN',
'OUT')),
CONSTRAINT banping_uk_title UNIQUE (title, salary)
)
INITRANS 1
MAXTRANS 255
PCTFREE 20
PCTUSED 50
STORAGE( INITIAL 1024k
NEXT 1024k
PCTINCREASE 0
MINEXTENTS 1
MAXEXTENTS 5)
TABLESPACE data;
2、欄位解釋:Schema:表的所有者
Table:表名
Column:欄位名
Datatype:欄位的資料型別
Tablespace:表所在的表空間
Pctfree:為了行長度增長而在每個塊中保留的空間的量(以佔整個空間減去塊頭部後所剩餘空間的百分比形式表示),當剩餘空間不足pctfree時,不再向該塊中增加新行。
Pctused:在塊剩餘空間不足pctfree後,塊已使用空間百分比必須小於pctused後,才能向該塊中增加新行。
INITRANS:在塊中預先分配的事務項數,預設值為1
MAXTRANS:限定可以分配給每個塊的最大事務項數,預設值為255
STORAGE:標識決定如何將區分配給表的儲存子句
LOGGING:指定表的建立將記錄到重做日誌檔案中。它還指定所有針對該表的後續操作都將被記錄下來。這是預設設定。
NOLOGGING:指定表的建立將不被記錄到重做日誌檔案中。
CACHE:指定即使在執行全表掃描時,為該表檢索的塊也將放置在緩衝區快取記憶體的LRU列表最近使用的一端。
NOCACHE:指定在執行全表掃描時,為該表檢索的塊將放置在緩衝區快取記憶體的LRU列表最近未使用的一端。
STORAGE子句:
INITIAL:初始區的大小
NEXT:下一個區的大小
PCTINCREASE:以後每個區空間增長的百分比
MINEXTENTS:段中初始區的數量
MAXEXTENTS:最大能擴充套件的區數
如果已為表空間定義了MINIMUM EXTENT,則表的區大小將向上舍入為MINIMUM EXTENT值的下一個較高的倍數。
3、語言增加約束條件:alter table dept add constraint dept_id_pk primary key(id);
1.1、建立兩種臨時表(會話級與事務級)
1.會話級臨時表
會話級臨時表是指臨時表中的資料只在會話生命週期之中存在,當用戶退出會話結束的時候,Oracle自動清除臨時表中資料。
格式:
Create Global Temporary Table Table_Name
(
Col1 Type1,
Col2 Type2
...
)
On Commit Preserve Rows;
2.事務級臨時表
事務級臨時表是指臨時表中的資料只在事務生命週期中存在。
Create Global Temporary Table Table_Name
(
Col1 Type1,
Col2 Type2
...
)
On Commit Delete Rows;
當一個事務結束(commit or rollback),Oracle自動清除臨時表中資料。
1.3、索引
1、索引分為5種:唯一索引,組合索引,反向鍵索引,點陣圖索引,基於函式的索引
2、一個基表不能建太多的索引;
空值不能被索引
只有唯一索引才真正提高速度,一般的索引只能提高30%左右。
3、索引提高查詢速度,對插入,更新操作則會變慢。
create unique index index_name on t_dept(n_id);
1.4、建立序列
CREATE SEQUENCE sequence_name
[START WITH num]
[INCREMENT BY increment]
[MAXVALUE num|NOMAXVALUE]
[MINVALUE num|NOMINVALUE]
[CYCLE|NOCYCLE]
[CACHE num|NOCACHE]
語法解析:
① START WITH:從某一個整數開始,升序預設值是1,降序預設值是-1。
② INCREMENT BY:增長數。如果是正數則升序生成,如果是負數則降序生成。升序預設值是1,降序預設值是-1。
③ MAXVALUE:指最大值。
④ NOMAXVALUE:這是最大值的預設選項,升序的最大值是:1027,降序預設值是-1。
⑤ MINVALUE:指最小值。
⑥ NOMINVALUE:這是預設值選項,升序預設值是1,降序預設值是-1026。
⑦ CYCLE:表示如果升序達到最大值後,從最小值重新開始;如果是降序序列,達到最小值後,從最大值重新開始。
⑧ NOCYCLE:表示不重新開始,序列升序達到最大值、降序達到最小值後就報錯。預設NOCYCLE。
⑨ CACHE:使用CACHE選項時,該序列會根據序列規則預生成一組序列號。保留在記憶體中,當使用下一個序列號時,可以更快的響應。當記憶體中的序列號用完時,系統再生成一組新的序列號,並儲存在快取中,這樣可以提高生成序列號的效率。Oracle預設會生產20個序列號。
⑩ NOCACHE:不預先在記憶體中生成序列號。
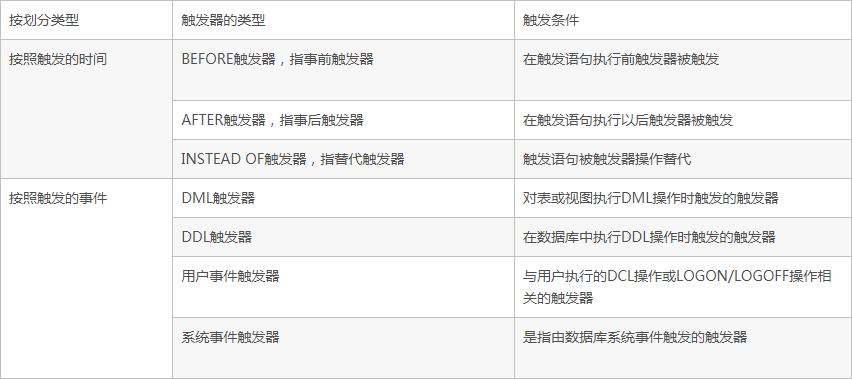
1.5、建立觸發器
1、對shcema的觸發器控制
create or replace trigger tri_dm1
before insert or update or delete on scott.emp
begin
if user <>'SCOTT' then
raise_application_error(-20001,'You don''t have access to modify this table.');
end if;
end;
/
2.利用觸發器進行表和備份表之間的同步複製。
CREATE OR replace TRIGGER duplicate_emp
AFTER UPDATE OR INSERT OR DELETE ON scott.emp
FOR EACH ROW
BEGIN
IF inserting THEN
INSERT INTO employee
VALUES (:new.empno,
:new.ename,
:new.job,
:new.mgr,
:new.hiredate,
:new.sal,
:new.comm,
:new.deptno);
ELSIF deleting THEN
DELETE FROM employee
WHERE empno = :old.empno;
ELSE
UPDATE employee
SET empno = :new.empno,
ename = :new.ename,
job = :new.job,
mgr = :new.mgr,
hiredate = :new.hiredate,
sal = :new.sal,
comm = :new.comm,
deptno = :new.deptno
WHERE empno = :old.empno;
END IF;
END;
/
3.建立觸發器,對scott.emp 表進行DML操作時的時間、使用者進行日誌記錄。
CREATE OR replace TRIGGER dm1_log
AFTER INSERT OR UPDATE OR DELETE ON scott.emp
DECLARE
oper emp_log.oper%TYPE;
BEGIN
IF inserting THEN
oper := 'insert';
ELSIF deleting THEN
oper := 'delete';
ELSE
oper := 'update';
END IF;
INSERT INTO emp_log
VALUES (USER,
SYSDATE,
oper);
END;
1.8、建立儲存過程
CREATE OR replace PROCEDURE pr_tets(name IN VARCHAR2,
o_msg OUT VARCHAR2,
o_rs SYS_REFCURSOR) AS
BEGIN
EXCEPTION
WHEN other THEN
ROLLBACK;
END
END
1.9、建立函式
2.0、建立包與包體
2.1、賦許可權
2.2、insert into /update /delete /select
三、常用場景需要用到的高階函式
1、查詢樹狀資料 (多選下拉介面)
2、統計每五分鐘的資料量
3、增加執行緒提高查詢效率
4、有插入又更新的資料匯入