資料結構之二叉樹應用(哈夫曼樹及哈夫曼編碼實現)(C++)
阿新 • • 發佈:2019-01-23
一、哈夫曼樹
1.書上用的是靜態連結串列實現,本文中的哈夫曼樹用 排序連結串列 實現;2.實現了從 字元頻率統計、構建權值集合、建立哈夫曼樹、生成哈夫曼編碼,最後對 給定字串的編碼、解碼功能。3.使用到的 “SortedList.h”標頭檔案,在上篇博文:資料結構之排序單鏈表。二、構建過程
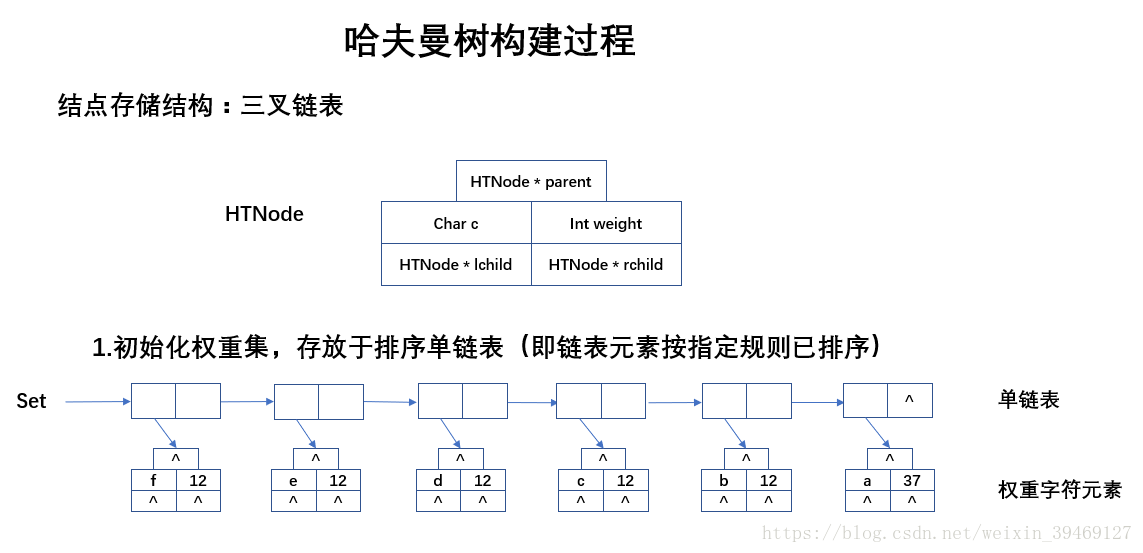
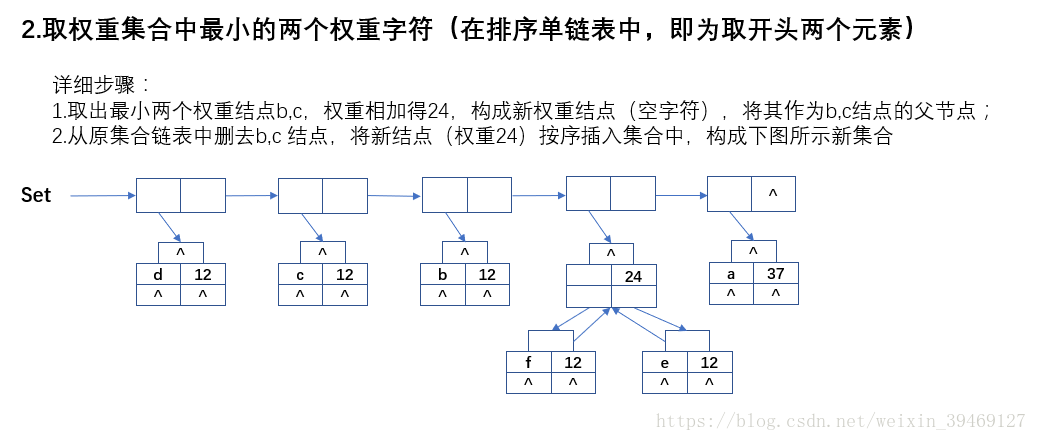
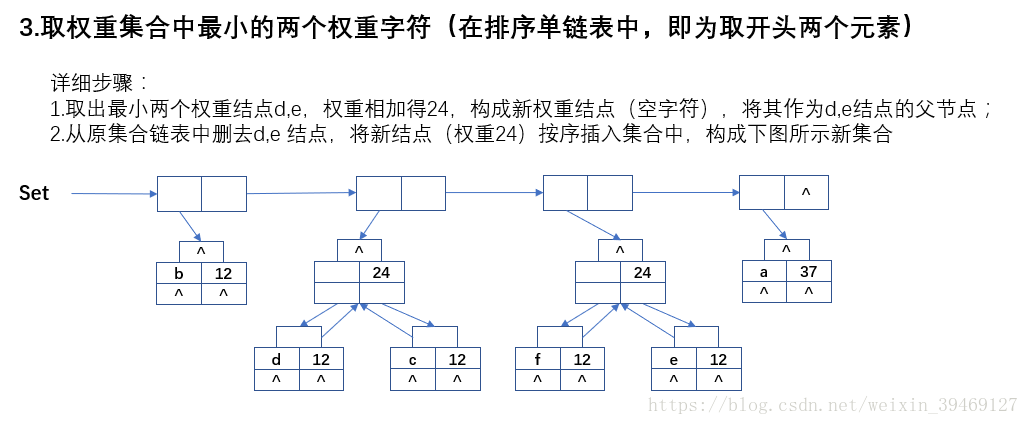
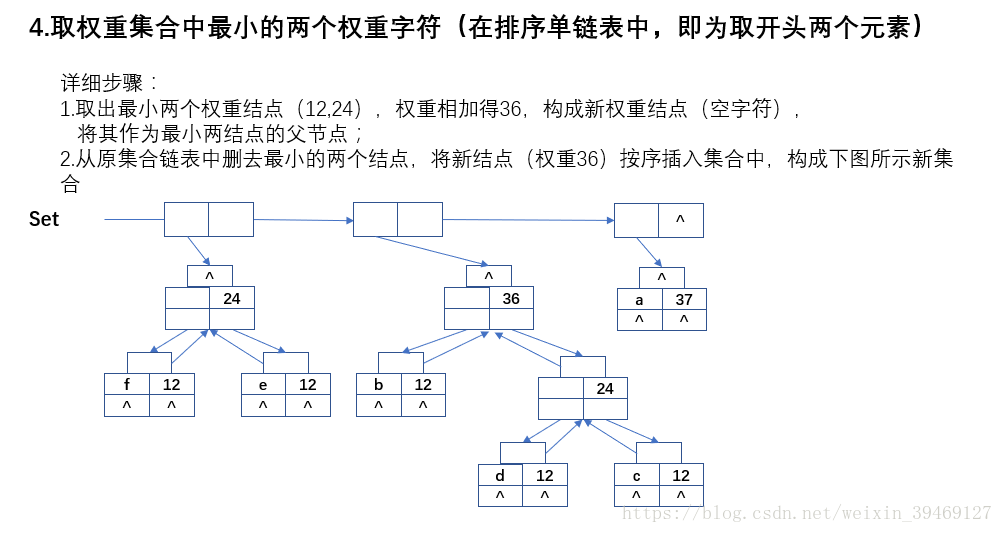
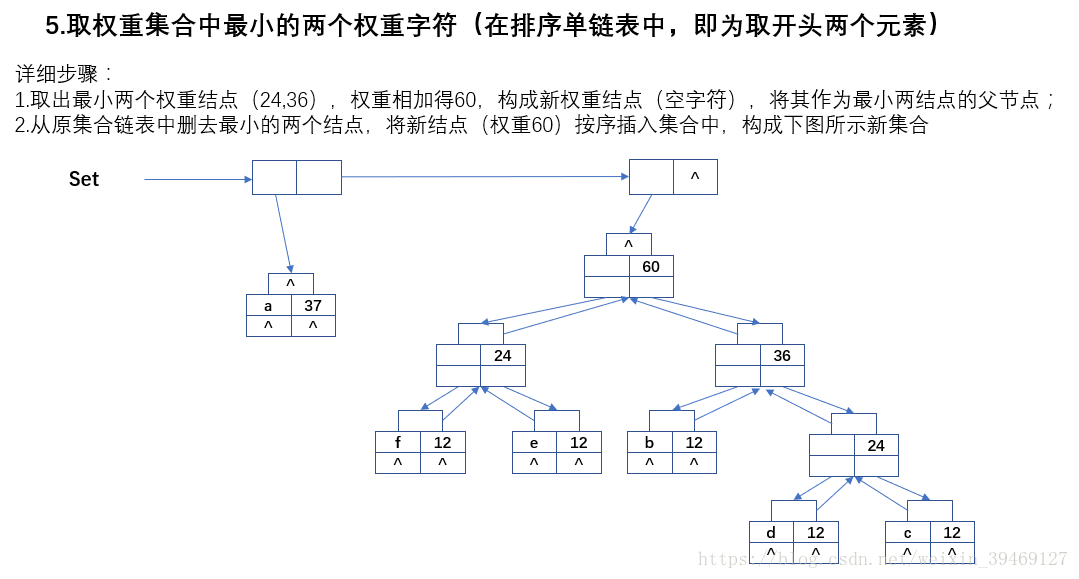
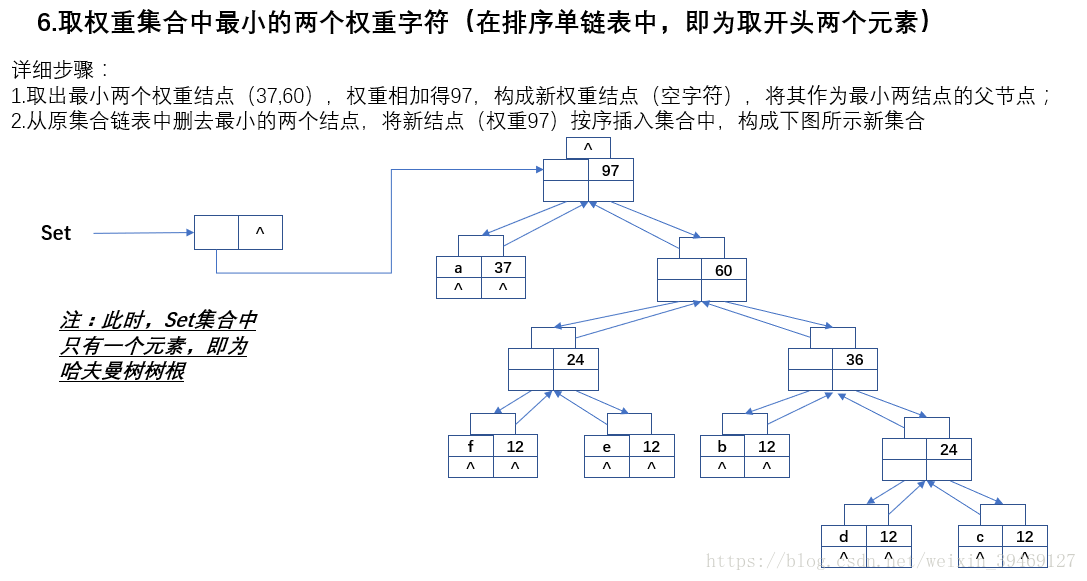
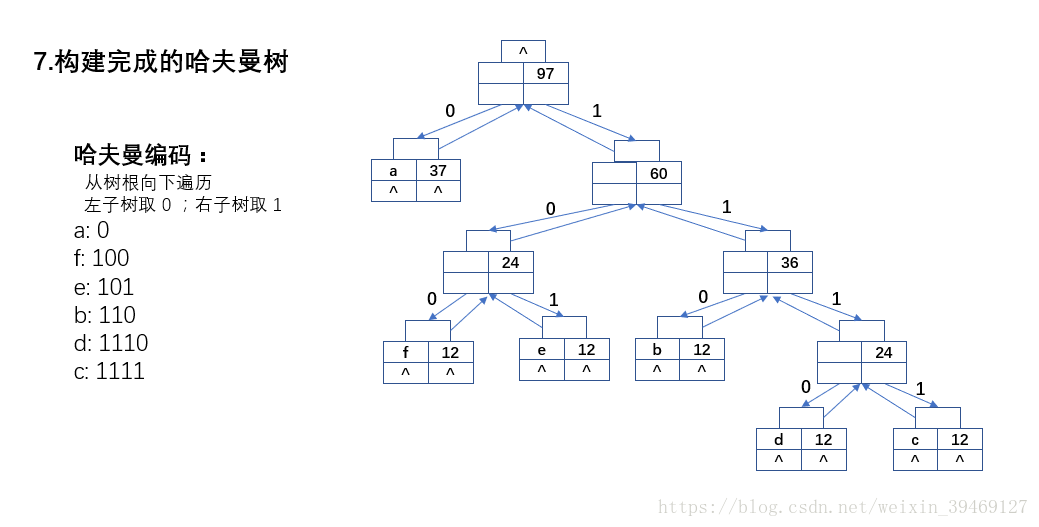
三、程式碼
//檔名:"HfmTree.h" #pragma once #include "SortedList.h" //"C1_Test.h" 排序列表 #include <string> using namespace std; /* . 二叉樹應用:哈夫曼樹及哈夫曼編碼實現 . 儲存結構:三叉連結串列 */ //哈夫曼樹結點 struct HTNode { char c; //字元域 int weight; //權重 HTNode * parent; //雙親結點 HTNode * lchild; //左指標域 HTNode * rchild; //右指標域 friend ostream & operator <<(ostream& out, HTNode *p) { /* . 友元函式過載輸出操作符,實現物件輸出 */ out << "(" << p->c << ":" << p->weight << ")"; return out; } }; class HfmTree { private: /* . 詞頻陣列 . 目前支援:英文字元(含大小寫),共52個 */ static const int _ARR_SIZE = 52; //詞頻陣列大小 static const char _START_C = 'a'; //詞頻陣列 0 下標對應的 字元 'a' static const int _MAGNIFICATION = 100; //詞頻放大倍數 int charFreqArr[_ARR_SIZE]{0}; //詞頻陣列(含大小寫),初始化為 0 string charCodeArr[_ARR_SIZE]{ "" }; //字元編碼陣列 void _Arr_StatisticCharFreq(string &s); //統計字元頻率 /* , 權值集合排序單鏈表 */ SortedList<HTNode> * varySet; //變化的權值集合 連結串列(用於構建哈夫曼樹根結點的生成) SortedList<HTNode> * originSet; //初始的權重集合 連結串列(用於存放 葉節點指標) /* . 哈夫曼樹 */ HTNode * root; //哈夫曼樹根結點 int leafNum; //葉結點數 void _CreateWeightSet(); //建立權值集合(排序單鏈表) void _CreateHfmTree(); //構建哈夫曼樹 void _GenerateHfmCode(); //生成哈夫曼編碼 public: HfmTree(); //無參構造 void Init(string &s); //初始化字串 void HfmCodeDisplay(); //顯示哈夫曼編碼 string Encoding(string s); //編碼 string Decoding(string s); //解碼 };
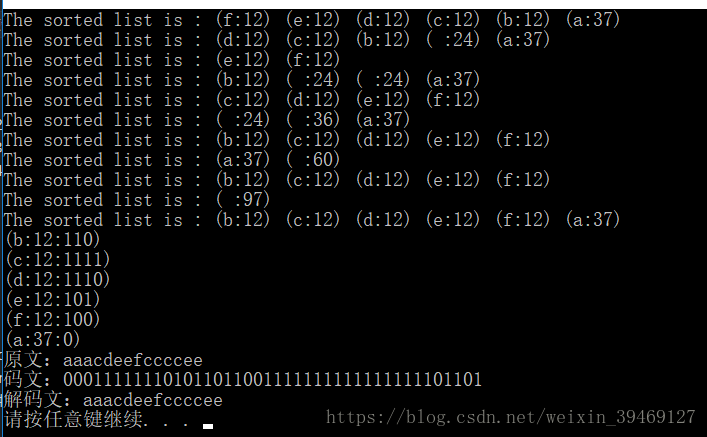
//檔名:"HfmTree.cpp" #include "stdafx.h" #include <iostream> #include <string> #include "HfmTree.h" using namespace std; int _HTNode_Compare(HTNode * e1, HTNode *e2) { /* . 實現 SortedList 類的 compare 介面 */ if (e1->weight > e2->weight) return 1; else if (e1->weight == e2->weight) return 0; else return -1; } HfmTree::HfmTree() { /* . 無參構造 */ //初始化變化集合連結串列 this->varySet = new SortedList<HTNode>(); this->varySet->Init(_HTNode_Compare, this->varySet->_ASC); //初始化原始集合連結串列 this->originSet = new SortedList<HTNode>(); this->originSet->Init(_HTNode_Compare, this->originSet->_ASC); //初始化哈夫曼樹 及 葉節點數 this->root = NULL; this->leafNum = 0; } void HfmTree::Init(string &s) { /* . 初始化字串,並構建哈夫曼樹 */ //1.字元頻率統計 _Arr_StatisticCharFreq(s); //2.建立權值集合單鏈 _CreateWeightSet(); //3.建立哈夫曼樹 _CreateHfmTree(); //4.生成哈夫曼編碼 _GenerateHfmCode(); } void HfmTree::_Arr_StatisticCharFreq(string &s) { /* . 統計字元頻率 */ //指標 p 指向詞頻陣列 int * p = this->charFreqArr; int sum = s.length(); //總字元數 char c = '\0'; //詞頻統計 for (int i = 0; i < (int)s.length(); i++) { c = s[i]; p[c - this->_START_C]++; //52個字元(a-z|A-Z)陣列基底 0 為 'a' } //詞頻陣列 歸一化 for (int i = 0; i < this->_ARR_SIZE; i++) { p[i] = (int)(p[i] * this->_MAGNIFICATION / sum); //放大 100 倍(若某些字元權重太小,可擴大倍數) } } void HfmTree::_CreateWeightSet() { /* . 構建哈夫曼樹 */ //哈夫曼結點變數 HTNode * node = NULL; //指標 p 指向詞頻陣列 int * p = this->charFreqArr; //遍歷詞頻陣列 for (int i = 0; i < this->_ARR_SIZE; i++) { if (p[i] == 0) continue; //初始化 樹結點 node = new HTNode; node->c = (char)(i + this->_START_C); //取字元 node->weight = p[i]; //取權重 node->parent = NULL; node->lchild = NULL; node->rchild = NULL; //順序插入 權重集合單鏈表 this->varySet->Insert(node); } //顯示集合 this->varySet->Display(); } void HfmTree::_CreateHfmTree() { /* . 建立哈夫曼樹 */ //初始化 樹結點 HTNode *first = NULL, *second = NULL, *newNode = NULL; //權值集合 元素結點數 只剩一個時,結束 while (this->varySet->Length() > 1) { //獲取並刪除 權值集合前兩個元素 (集合升序排列,前兩個為權值最小) first = this->varySet->Delete(1); second = this->varySet->Delete(1); //構建 新權值 根結點,並初始化 newNode = new HTNode; newNode->c = '\0'; newNode->weight = first->weight + second->weight; //權值相加 newNode->parent = NULL; newNode->lchild = first; newNode->rchild = second; //賦值 兩個結點的 雙親 first->parent = newNode; second->parent = newNode; //並將新結點 順序插入集合,並顯示集合 this->varySet->Insert(newNode); this->varySet->Display(); //將刪除的兩個元素結點(非後建的根結點),加入到 初始集合 中,並顯示 if (first->c != '\0') this->originSet->Insert(first); if (second->c != '\0') this->originSet->Insert(second); this->originSet->Display(); } //取權重集合鏈 第一個元素 作為 哈夫曼樹根 this->root = this->varySet->Delete(1); } void HfmTree::_GenerateHfmCode() { /* . 生成哈夫曼編碼 */ HTNode * p = NULL, *q = NULL; char c = '\0'; //遍歷葉子結點(初始權重集合) for (int i = 0; i < this->originSet->Length(); i++) { //獲取葉結點 p = this->originSet->Get(i + 1); //獲取字元 c = p->c; //從葉節點 到 根 的遍歷 while (p->parent != NULL) { //q 取 p 的根結點 q = p->parent; if (q->lchild == p) this->charCodeArr[c - this->_START_C] = "0" + this->charCodeArr[c - this->_START_C]; else this->charCodeArr[c - this->_START_C] = "1" + this->charCodeArr[c - this->_START_C]; //p 向根移動 p = p->parent; } //置空 遊走指標 p = NULL; q = NULL; } } void HfmTree::HfmCodeDisplay() { /* . 顯示哈夫曼編碼 */ HTNode *p = NULL; for (int i = 0; i < this->originSet->Length(); i++) { p = this->originSet->Get(i + 1); cout << "(" << p->c << ":" << p->weight << ":" << this->charCodeArr[p->c - this->_START_C] << ")" << endl; } } string HfmTree::Encoding(string s) { /* . 編碼 */ //初始化編碼字串 string encodingStr = ""; //遍歷字符集 for (int i = 0; i < (int)s.length(); i++) { encodingStr = encodingStr + this->charCodeArr[s[i] - this->_START_C]; } return encodingStr; } string HfmTree::Decoding(string s) { /* . 解碼 */ //初始化 解碼字串 string decodingStr = ""; //初始化結點指標:p 指向哈夫曼樹根結點 HTNode *p = this->root; //初始化 編碼: 0 1 int code = 0; //遍歷碼串 for (int i = 0; i < (int)s.length(); i++) { //從根 遍歷,按碼串路徑 尋葉子結點 while (p->lchild != NULL && p->rchild != NULL) { //取字元碼 0 或 1,轉換成 整型 code = s[i] - '0'; // 0|左子樹 1|右子樹 if (code == 0) p = p->lchild; else p = p->rchild; //自增 i i++; } //抵消一次自增 i--; //葉節點字元拼接 decodingStr = decodingStr + p->c; //指標 p 置到 根結點 p = this->root; } return decodingStr; }
//檔名:"HfmTree_Test.cpp" #include "stdafx.h" #include <iostream> #include "HfmTree.h" using namespace std; int main() { //利用 s 構建哈夫曼樹 string s = "abcadefa"; HfmTree * t = new HfmTree(); t->Init(s); t->HfmCodeDisplay(); //在構造的哈夫曼樹基礎上,測試 編碼 解碼 string s1 = "aaacdeefccccee"; //編碼的字元範圍不可超過 構建哈夫曼樹時的葉節點字符集 範圍 string s2 = t->Encoding(s1); cout << "原文:" << s1 << endl; cout << "碼文:" << s2 << endl; cout << "解碼文:" << t->Decoding(s2) << endl; return 0; }