
十、最大熵模型與EM演算法
一、最大熵模型
證明:,求導是凸函式,在x=1處取得極值



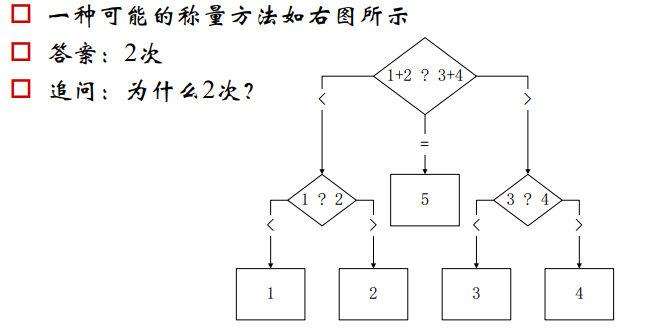
1、熵
熵是資訊的度量,與資訊量成反比。
資訊量:
事件發生的概率越高,對應的資訊量越低,事件發生的概率越小,對應的資訊量越大。
熵是資訊量的期望:


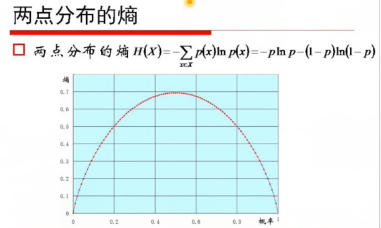
兩點分佈的最大熵:

三點分佈:
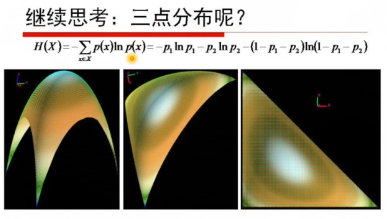
p1=p2=p3的時候,曲面的值最高(圖1)
當X滿足均勻分佈時,熵最大:

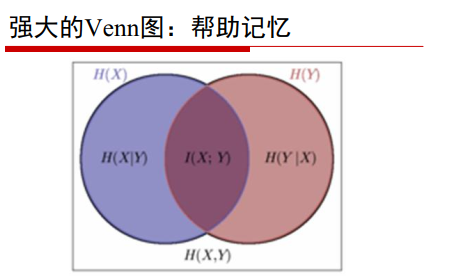
聯合熵和條件熵
聯合熵:H(X,Y),表示X,Y同時發生的不確定性
解釋:聯合熵=X發生的熵+X發生的條件下Y發生的熵
聯合熵的性質:
- 聯合熵>=變數熵中最大的
- 聯合熵<=變數熵之和
條件熵:Y發生的條件下,X發生的不確定性

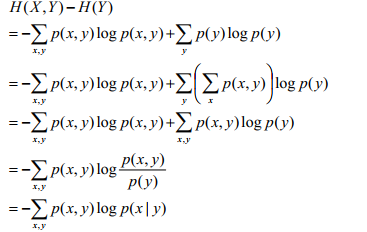
相對熵
度量兩個分佈之間的差異
如果用距離度量的話,兩個分佈的點的個數要相等,如果不等的話,無法進行單個點距離的度量。

E_px 表示期望
證明:利用Jenson不等式,
Jensen不等式表述如下:
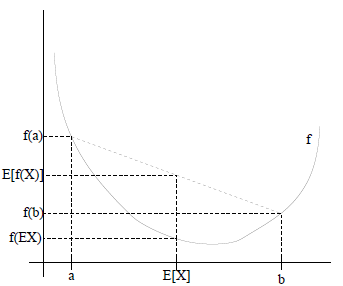
如果f是凸函式,X是隨機變數,那麼
- 如果f是凹函式,X是隨機變數,那麼

交叉熵
互資訊

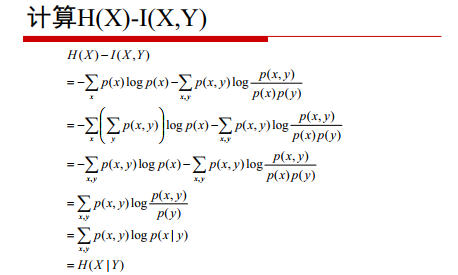
(五六行新增負號)
總結

2、最大熵模型
承認已知事物
對未知事物不做任何假設,沒有任何偏見
示例:

假設1:

假設2:

利用最大熵模型:

承認已知的X,讓未知的Y的概率最大。
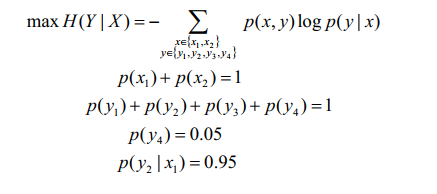
寫成一般的形式:

相關推薦
十、最大熵模型與EM演算法
一、最大熵模型 lnx<=x−1lnx<=x−1 證明:f(x)=x−1−lnx,x>0f(x)=x−1−lnx,x>0,求導是凸函式,在x=1處取得極值 1、熵 熵是資訊的度量,與資訊量成反比。
斯坦福大學-自然語言處理入門 筆記 第十一課 最大熵模型與判別模型(2)
一、最大熵模型 1、模型介紹 基本思想:我們希望資料是均勻分佈的,除非我們有其他的限制條件讓給我們相信資料不是均勻分佈的。均勻分佈代表高熵(high entropy)。所以,最大熵模型的基本思想就是我們要找的分佈是滿足我們限制條件下,同時熵最高的分佈。 熵:表示分佈的不
斯坦福大學-自然語言處理入門 筆記 第八課 最大熵模型與判別模型
一、生成模型與判別模型 1、引言 到目前為止,我們使用的是生成模型(generative model),但是在實際使用中我們也在大量使用判別模型(discriminative model),主要是因為它有如下的優點: 準確性很高 更容易包含很多和
【統計學習方法-李航-筆記總結】六、邏輯斯諦迴歸和最大熵模型
本文是李航老師《統計學習方法》第六章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: http://www.cnblogs.com/YongSun/p/4767100.html https://blog.csdn.net/tina_ttl/article/details/53519391
統計學習---邏輯斯蒂迴歸與最大熵模型
邏輯斯蒂迴歸和最大熵模型 邏輯斯蒂分佈 邏輯斯蒂迴歸模型 將權值向量和輸入向量加以擴充後的邏輯斯蒂模型為 模型引數估計 極大似然估計法 最大熵模型 最大熵原理:在所有可能的概率模型中,熵最大的模型是最好的模型。通常用約
NLP --- 最大熵模型的解法(GIS演算法、IIS演算法)
上一節中我們詳細的介紹了什麼是最大熵模型,也推匯出了最大熵模型的目標公式,但是沒給出如何求解的問題,本節將詳細講解GIS演算法求解最大熵模型的過程,這裡先把上一節的推匯出的公式拿過來: 上面第一個式子是說我們要尋找的P要滿足k個約束條件,下式說是在滿足的約束的情況下,找到是熵值最大的那
《統計學習方法(李航)》邏輯斯蒂迴歸與最大熵模型學習筆記
作者:jliang https://blog.csdn.net/jliang3 1.重點歸納 1)線性迴歸 (1)是確定兩種或以上變數間相互依賴的定量關係的一種統計分析方法。 (2)模型:y=wx+b (3)誤差函式: (4)常見求解方法 最小
李航·統計學習方法筆記·第6章 logistic regression與最大熵模型(1)·邏輯斯蒂迴歸模型
第6章 logistic regression與最大熵模型(1)·邏輯斯蒂迴歸模型 標籤(空格分隔): 機器學習教程·李航統計學習方法 邏輯斯蒂:logistic 李航書中稱之為:邏輯斯蒂迴歸模型 周志華書中稱之為:對數機率迴歸模
邏輯斯諦迴歸與最大熵模型-《統計學習方法》學習筆記
0. 概述: Logistic迴歸是統計學中的經典分類方法,最大熵是概率模型學習的一個準則,將其推廣到分類問題得到最大熵模型,logistic迴歸模型與最大熵模型都是對數線性模型。 本文第一部分主
機器學習筆記(6)-邏輯迴歸與最大熵模型
Logistic迴歸 Logistic 迴歸雖然名字叫回歸,但是它是用來做分類的。其主要思想是: 根據現有資料對分類邊界線建立迴歸公式,以此進行分類。假設現在有一些資料點,我們用一條直線對這些點進行擬合(這條直線稱為最佳擬合直線),這個擬合的過程就叫做迴歸。
統計學習方法 6-邏輯斯諦迴歸與最大熵模型
邏輯斯諦迴歸模型 邏輯斯諦分佈 二元邏輯斯諦迴歸模型 模型引數估計 多元邏輯斯諦迴歸 最大熵模型 最大熵原理 最大熵原理認為,學習概率模型時,在所有可能的概率模型(分佈)中,熵最大的模型是最好的模型。通常用約束條件來確定概率模型
最大熵模型
定性 全部 投資 情況 進行 算法 出了 信息 簡單 我們不要把雞蛋都放在一個籃子裏面講得就是最大熵原理,從投資的角度來看這就是風險最小原則。從信息論的角度來說,就是保留了最大的不確定性,也就是讓熵達到了最大。最大熵院裏指出,對一個隨機事件的概率分布進行預測的時候,我
通俗理解最大熵模型
log logs ima 最大熵 ges es2017 最大熵模型 blog image 通俗理解最大熵模型
淺談最大熵模型中的特徵
最近在看到自然語言處理中的條件隨機場模型時,發現了裡面涉及到了最大熵模型,這才知道最大熵模型自己還是一知半解,於是在知乎上查閱了很多資料,發現特別受用,飲水思源,我將自己整理的一些資料寫下來供大家參考 僅僅對輸入抽取特徵。即特徵函式為 對輸入和輸出同時抽取特徵。即特徵函式為
【機器學習】最大熵模型原理小結
最大熵模型(maximum entropy model, MaxEnt)也是很典型的分類演算法了,它和邏輯迴歸類似,都是屬於對數線性分類模型。在損失函式優化的過程中,使用了和支援向量機類似的凸優化技術。而對熵的使用,讓我們想起了決策樹演算法中的ID3和C4.5演算法。理解了最
最大熵模型(MaxEnt)解析
給出了最大熵模型的一般形式(其中的f為特徵函式,後面我們還會講到): 而文獻【5】中我們從另外一種不同的角度也得出了多元邏輯迴歸的一般形式: 可見,儘管採用的方法不同,二者最終是殊途同歸、萬法歸宗了。 所以我們說無論是多元邏輯迴歸,還是最大熵模型,又或者是Sof
一些對最大熵模型的理解
一、最大熵原理 概念:對於隨機變數X,其概率分佈為P(X),一般在約束條件下會有無數P(X)存在。最大熵原理就是在所有符合約束條件的P(X)中,熵最大的模型即為最優模型。 二、最大熵模型 最大熵模型,就是基於最大熵原理的分類模型。李航《統計學習方法》中對最大熵模型的描述
最大熵模型中的數學推導
最大熵模型中的數學推導 0 引言 寫完SVM之後,一直想繼續寫機器學習的系列,無奈一直時間不穩定且對各個模型演算法的理
七種常見閾值分割程式碼(Otsu、最大熵、迭代法、自適應閥值、手動、迭代法、基本全域性閾值法)
整理了一些主要的分割方法,以後用省的再查,其中大部分為轉載資料,轉載連結見資料; 一、工具:VC+OpenCV 二、語言:C++ 三、原理 (1) otsu法(最大類間方差法,有時也稱之為大津演算法)使用的是聚類的思想,把影象的灰度數按灰度級分成2個部分,使得兩
NLP --- 最大熵模型的引入
前幾節我們詳細的闡述了什麼是HMM,同時給出了HMM的三個問題,也給出瞭解決這三個問題的方法最後給出了HMM的簡單的應用。其中為了解決第三個問題我們引入了EM演算法,這個演算法有點麻煩,但是不難理解,而解決第一個和第二個問題時使用的演算法基本上都是基於動態規劃的,這裡需要大家首先對動態規劃演算法