
FCN原始碼解讀之solve.py
solve.py是FCN中解決方案檔案,即通過執行solve.py檔案可以實現FCN模型的訓練和測試過程。以下拿voc-fcn32s資料夾裡的solve.py舉例分析。
一、原始碼及分析如下:
#coding=utf-8 import caffe import surgery, score import numpy as np import os import sys try: import setproctitle setproctitle.setproctitle(os.path.basename(os.getcwd())) except: pass #載入網路模型的引數資訊 weights = '../ilsvrc-nets/vgg16-fcn.caffemodel' # init 初始化(選擇要執行此程式碼訓練的GPU) caffe.set_device(int(sys.argv[1])) caffe.set_mode_gpu() #使用caffe中的隨機梯度下降法解決方案(SGDSolver,也即FCN模型訓練時每次迭代只訓練一張圖片) solver = caffe.SGDSolver('solver.prototxt') solver.net.copy_from(weights) #直接從上述載入的模型中拷貝引數初始化網路 # surgeries 由於Vgg16模型是沒有上取樣層的,所以遇到上取樣層(即含有'up'字眼的層),需要利用surgery.py中的interp()函式進行 #這些層的初始化,所採用的初始化方法是雙線性插值,詳見我的另一篇部落格https://blog.csdn.net/qq_21368481/article/details/80289350 interp_layers = [k for k in solver.net.params.keys() if 'up' in k] surgery.interp(solver.net, interp_layers) # scoring val中儲存測試集的索引號 val = np.loadtxt('../data/segvalid11.txt', dtype=str) #總訓練次數為25*4000=100000次(注:這裡不修改的話,直接在solve.prototxt中修改max_iter是沒有用的) for _ in range(25): solver.step(4000) #每訓練4000次,進行一次測試,並儲存一下模型引數(對應solve.prototxt中的snapshot: 4000) score.seg_tests(solver, False, val, layer='score')
但是直接執行上述程式碼是無法執行的,會報很多錯誤,需要進行修改才能執行,具體修改後的程式碼如下(讀者可以和上述原始碼對比一下,做出相應的修改):
#coding=utf-8 import sys sys.path.append('D:/caffe/caffe-master/python') #載入caffe中的python檔案所在路徑(以免報錯),注意要載入自己的 import caffe import surgery, score import numpy as np import os try: import setproctitle setproctitle.setproctitle(os.path.basename(os.getcwd())) except: pass ''' 載入Vgg16模型引數(原因在於FCN中FCN32s是在Vgg16模型上fine-tune來的,而 FCN16s是在FCN32s的基礎上訓練的,所以在FCN16s的solve.py檔案中要載入FCN32s 訓練完後的模型(例如caffemodel-url中給的fcn32s-heavy-pascal.caffemodel, caffemodel-url檔案在每個FCN模型資料夾都有,例如voc-fcn32s資料夾,直接 複製裡面的網址下載即可),FCN8s的載入FCN16s訓練好的模型引數。 Vgg16模型引數和其deploy.prototxt檔案可從我提供的百度雲連結上下載: ''' vgg_weights = 'vgg16-fcn.caffemodel' vgg_proto = 'vgg16_deploy.prototxt' #載入Vgg16模型的deploy.prototxt檔案 #weights = '../ilsvrc-nets/vgg16-fcn.caffemodel' # init 初始化 #caffe.set_device(int(sys.argv[1])) caffe.set_device(0) caffe.set_mode_gpu() #如果是CPU訓練修改為caffe.set_mode_cpu(),但是好像CPU帶不起FCN這個龐大模型(記憶體不夠) solver = caffe.SGDSolver('solver.prototxt') #solver.net.copy_from(weights) vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN) #利用上述載入的vgg_weights和vgg_proto初始化Vgg16網路 #將上述網路通過transplant()函式強行復制給FCN32s網路(具體複製方法仍可參見我的 #另一篇部落格https://blog.csdn.net/qq_21368481/article/details/80289350) surgery.transplant(solver.net, vgg_net) del vgg_net #刪除Vgg16網路 # surgeries interp_layers = [k for k in solver.net.params.keys() if 'up' in k] surgery.interp(solver.net, interp_layers) #此處訓練集的路徑需要換成自己的,其中的seg11valid.txt裡存放的是訓練集每張圖片的檔名(不包含副檔名) #可以自行設定哪些圖片作為訓練集(個人建議直接拿Segmentation資料夾中的val.txt裡的當做訓練集) val = np.loadtxt('D:/VOC2012/ImageSets/Segmentation/seg11valid.txt', dtype=str) for _ in range(25): solver.step(4000) score.seg_tests(solver, False, val, layer='score')
1.1 執行
在修改完上述檔案的情況下,如果是windows下(裝了Anaconda的話直接開啟Anaconda Prompt,如果沒裝的話直接cmd開啟命令提示符視窗),直接在voc-fcn32s檔案路徑下輸入以下語句即可進行訓練。
python solve.py如下圖所示:

如果在linux下,開啟終端,也在voc-fcn32s檔案路徑下輸入以下語句:
sudo python solve.py
1.2 常見錯誤
(1)ImportError: No module named surgery
將與voc-fcn32s資料夾同一根目錄下的surgery.py檔案複製到voc-fcn32s資料夾中,並在開頭新增如下程式碼:
from __future__ import division
import sys
sys.path.append('D:/caffe/caffe-master/python') #新增自己caffe中的python資料夾路徑
import caffe
import numpy as np如果還報No module named score等,同理解決。
(2)路徑錯誤
訓練前,還需要修改一下train.prototxt和val.prototxt中的data層中資料集載入路徑,拿train.prototxt為例,'sbdd_dir'後的路徑修改為自己資料集的路徑。
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "voc_layers"
layer: "SBDDSegDataLayer"
param_str: "{\'sbdd_dir\': \'D:/VOC2012\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
}
}
同時也要修改一下voc_layers.py檔案,因為這裡面也有訓練集和測試集的載入路徑,且在訓練過程中是會時時通過這個檔案下的程式碼載入訓練圖片(原因在於上述train.prototxt中是data層中的module:"voc_layers",所代表的意思就是通過voc_layers.py自行定義的訓練集和測試集載入方式來載入),測試圖片載入同理。
主要修改其中的class SBDDSegDataLayer(caffe.Layer)類中的setup(self, bottom, top)函式中的路徑和load_label(self, idx)函式中的資料集格式以及class VOCSegDataLayer(caffe.Layer)類中的setup(self, bottom, top)函式的路徑,都修改為自己的。
詳細可參見我的另一篇部落格:https://blog.csdn.net/qq_21368481/article/details/80246028。
二、實時繪製loss-iter曲線
caffe中的loss分兩種,一種是本次單次迭代輸出的loss,一種是多次迭代的平均loss,具體可以參見caffe中的src資料夾下的solver.cpp中的Step(int iters) 函式和UpdateSmoothedLoss(Dtype loss, int start_iter, int average_loss) 函式。
如下所示,Iteration 20, loss = 390815中的loss為20次迭代輸出的平均loss,而rain net output #0: loss = 151572為本次單次迭代輸出的loss,也即為何兩者是不同的(只有在Iteration 0時兩者才會相同,因為平均loss是從0開始累加求平均計算出來,第0次迭代輸出的平均loss就是第0次迭代輸出的loss)。
平均loss的好處的更加平滑,當然不用loss直接用單次的loss都是一樣的,兩者都能反映訓練過程中loss的變化趨勢。
I0611 22:14:55.219404 6556 solver.cpp:228] Iteration 0, loss = 557193
I0611 22:14:55.219404 6556 solver.cpp:244] Train net output #0: loss = 557193 (* 1 = 557193 loss)
I0611 22:14:55.233840 6556 sgd_solver.cpp:106] Iteration 0, lr = 1e-010
I0611 22:15:03.114138 6556 solver.cpp:228] Iteration 20, loss = 390815
I0611 22:15:03.114138 6556 solver.cpp:244] Train net output #0: loss = 151572 (* 1 = 151572 loss)
I0611 22:15:03.115141 6556 sgd_solver.cpp:106] Iteration 20, lr = 1e-010
I0611 22:15:11.631978 6556 solver.cpp:228] Iteration 40, loss = 299086
I0611 22:15:11.632982 6556 solver.cpp:244] Train net output #0: loss = 22125.5 (* 1 = 22125.5 loss)
I0611 22:15:11.634985 6556 sgd_solver.cpp:106] Iteration 40, lr = 1e-010
I0611 22:15:19.864284 6556 solver.cpp:228] Iteration 60, loss = 238765
I0611 22:15:19.865325 6556 solver.cpp:244] Train net output #0: loss = 154152 (* 1 = 154152 loss)
I0611 22:15:19.866287 6556 sgd_solver.cpp:106] Iteration 60, lr = 1e-0101.Step(int iters) 函式
template <typename Dtype>
void Solver<Dtype>::Step(int iters) {
const int start_iter = iter_; //起始迭代點
const int stop_iter = iter_ + iters; //終止迭代點
int average_loss = this->param_.average_loss(); //平均loss=(前average_loss-1次迭代的loss總和+本次迭代的loss)/average_loss
losses_.clear(); //清楚用來儲存每次迭代所輸出的loss
smoothed_loss_ = 0; //smoothed_loss即平均loss(注:每次呼叫Step()函式平均loss就會清零,即從本次迭代開始重新開始累計求平均)
while (iter_ < stop_iter) {
// zero-init the params
net_->ClearParamDiffs();
if (param_.test_interval() && iter_ % param_.test_interval() == 0
&& (iter_ > 0 || param_.test_initialization())
&& Caffe::root_solver()) {
TestAll();
if (requested_early_exit_) {
// Break out of the while loop because stop was requested while testing.
break;
}
}
for (int i = 0; i < callbacks_.size(); ++i) {
callbacks_[i]->on_start();
}
const bool display = param_.display() && iter_ % param_.display() == 0;
net_->set_debug_info(display && param_.debug_info());
// accumulate the loss and gradient
Dtype loss = 0;
for (int i = 0; i < param_.iter_size(); ++i) { //這裡的param_.iter_size()對於FCN來說,對應solver.prototxt中的iter_size這個引數
loss += net_->ForwardBackward(); //前向計算+後向傳播(從中可以看出每次迭代過程中其實是param_.iter_size()次前向計算和後向傳播)
}
loss /= param_.iter_size(); //求平均
// average the loss across iterations for smoothed reporting
UpdateSmoothedLoss(loss, start_iter, average_loss); //更新平均loss
if (display) { //一般而言都設定display=average_loss,這裡可以看看FCN中是設定
LOG_IF(INFO, Caffe::root_solver()) << "Iteration " << iter_
<< ", loss = " << smoothed_loss_; //輸出平均loss
const vector<Blob<Dtype>*>& result = net_->output_blobs();
int score_index = 0;
for (int j = 0; j < result.size(); ++j) {
const Dtype* result_vec = result[j]->cpu_data();
const string& output_name =
net_->blob_names()[net_->output_blob_indices()[j]];
const Dtype loss_weight =
net_->blob_loss_weights()[net_->output_blob_indices()[j]];
for (int k = 0; k < result[j]->count(); ++k) {
ostringstream loss_msg_stream;
if (loss_weight) { //只有loss層的loss_weight=1,其他層都是0
loss_msg_stream << " (* " << loss_weight
<< " = " << loss_weight * result_vec[k] << " loss)";
}
LOG_IF(INFO, Caffe::root_solver()) << " Train net output #"
<< score_index++ << ": " << output_name << " = "
<< result_vec[k] << loss_msg_stream.str(); //輸出單次迭代的loss值
}
}
}
for (int i = 0; i < callbacks_.size(); ++i) {
callbacks_[i]->on_gradients_ready();
}
ApplyUpdate();
// Increment the internal iter_ counter -- its value should always indicate
// the number of times the weights have been updated.
++iter_;
SolverAction::Enum request = GetRequestedAction();
// Save a snapshot if needed.
if ((param_.snapshot()
&& iter_ % param_.snapshot() == 0
&& Caffe::root_solver()) ||
(request == SolverAction::SNAPSHOT)) {
Snapshot();
}
if (SolverAction::STOP == request) {
requested_early_exit_ = true;
// Break out of training loop.
break;
}
}
}void Solver<Dtype>::UpdateSmoothedLoss(Dtype loss, int start_iter,
int average_loss) {
if (losses_.size() < average_loss) { //如果losses_中還未儲存完average_loss次迭代輸出的loss,則直接求平均
losses_.push_back(loss);
int size = losses_.size();
smoothed_loss_ = (smoothed_loss_ * (size - 1) + loss) / size; //求前size次迭代輸出的loss的平均值
} else { //如果losses_中已經存在average_loss次迭代輸出的loss,則取離本次迭代最近的average_loss-1次迭代輸出的loss與本次loss求平均
int idx = (iter_ - start_iter) % average_loss;
smoothed_loss_ += (loss - losses_[idx]) / average_loss;
losses_[idx] = loss; //將本次迭代輸出的loss存入losses_中的相應位置
}
}3.修改後的solve.py檔案如下(實現實時繪製loss-iter曲線)
#coding=utf-8
import sys
sys.path.append('D:/caffe/caffe-master/python')
import caffe
import surgery, score
import numpy as np
import os
import sys
#plot 載入繪製圖像所需要的python庫
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
import math
//根據上述UpdateSmoothedLoss()函式修改為python語言而來,目的就是更新平均loss
def UpdateSmLoss(loss,losses_,iterval,average_loss,sm_loss):
sizel = len(losses_)
listloss=loss.tolist() #array轉化為list
if sizel < average_loss:
losses_.append(listloss)
sm_loss = (sm_loss*sizel+listloss)/(sizel+1)
else:
idx = iterval % average_loss
sm_loss += (listloss-losses_[idx]) / average_loss
losses_[idx] = listloss
return sm_loss,losses_
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
vgg_weights = 'vgg16-fcn.caffemodel'
vgg_proto = 'vgg16_deploy.prototxt'
#weights = 'vgg16-fcn.caffemodel'
# init
#caffe.set_device(int(sys.argv[1]))
caffe.set_device(0)
caffe.set_mode_gpu()
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
solver = caffe.SGDSolver('solver.prototxt')
#parameter 實時繪製所需要的一些引數
niter = 100000 #對應solver.prototxt中的max_iter: 100000
display = 20 #對應solver.prototxt中的display: 20
snapshotnum = 4000 #對應solver.prototxt中的snapshot: 4000
ave_loss = 20 #對應solver.prototxt中的average_loss: 20
#losses_用於儲存當前迭代次數的前average_loss次迭代所產生的loss
losses_ = []
sm_loss = 0 #平均loss
#train_loss 用於儲存每次的sm_loss,以便畫折線圖
train_loss = np.zeros(np.ceil(niter * 1.0 / display))
vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN)
surgery.transplant(solver.net, vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
val = np.loadtxt('D:/VOC2012/ImageSets/Segmentation/seg11valid.txt', dtype=str)
#for _ in range(25):
#solver.step(4000)
#score.seg_tests(solver, False, val, layer='score')
plt.close()
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
plt.grid(True)
plt.ion() #開啟互動式繪圖(實現實時繪圖的關鍵語句)
for it in range(niter):
solver.step(1) #python下的step()函式,對應於上述Step()函式
_train_loss = solver.net.blobs['loss'].data #取出每次迭代輸出的loss
[sm_loss,losses_] = UpdateSmLoss(_train_loss,losses_,it,ave_loss,sm_loss) #更新
if it % display == 0 and it !=0: #滿足條件時展示平均loss
ax.scatter(it,sm_loss,c = 'r',marker = 'o') #繪製loss的散點圖
train_loss[it // display - 1] = sm_loss #儲存平均loss
if it > display:
ax.plot([it-20,it],[train_loss[it // display - 2],train_loss[it // display - 1]],'-r') #繪製折線圖
plt.pause(0.0001)
if it % snapshotnum == 0 and it != 0: #對應原solve.py檔案中的最後兩句程式碼,每snapshotnum次迭代進行一次測試
score.seg_tests(solver, False, val, layer='score')
losses_ = [] #測試後需要清空losses_以及平均loss,對應於每次進入Step()函式都需要對這兩者清空
sm_loss = 0效果圖如下:
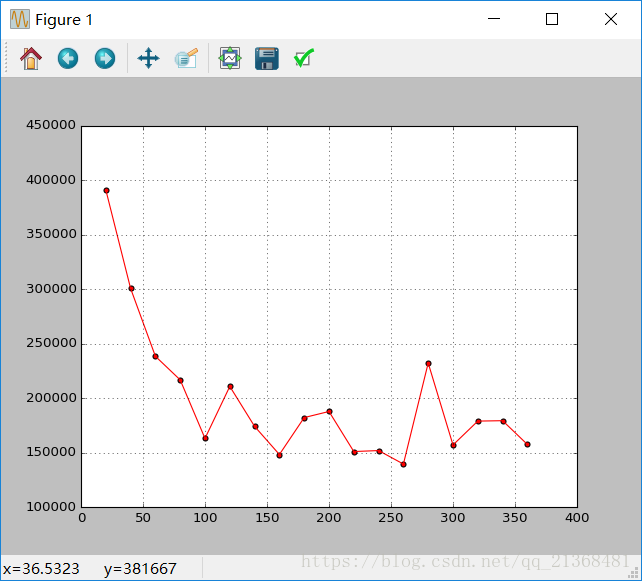
注:可以發現在訓練過程中輸出的本次單次迭代loss和多次迭代的平均loss是一樣的,原因在於每次進入到Step()函式都需要對losses_ 和smoothed_loss清空導致每次進入Step()函式後losses_的大小總為0,也就只會進入if (losses_.size() < average_loss)這個條件裡,導致兩種loss相同。
I0611 22:08:17.291122 8428 solver.cpp:228] Iteration 160, loss = 63695.3
I0611 22:08:17.291122 8428 solver.cpp:244] Train net output #0: loss = 63695.3 (* 1 = 63695.3 loss)
I0611 22:08:17.292124 8428 sgd_solver.cpp:106] Iteration 160, lr = 1e-010