【資料探勘】分類之kNN
阿新 • • 發佈:2018-12-31
1.演算法簡介
kNN的思想很簡單:計算待分類的資料點與訓練集所有樣本點,取距離最近的k個樣本;統計這k個樣本的類別數量;根據多數表決方案,取數量最多的那一類作為待測樣本的類別。距離度量可採用Euclidean distance,Manhattan distance和cosine。
用Iris資料集作為測試,程式碼參考[1]
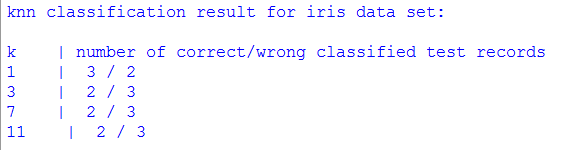
import numpy as np import scipy.spatial.distance as ssd def read_data(fn): """ read dataset and separate into characteristics data and label data """ # read dataset file with open(fn) as f: raw_data = np.loadtxt(f, delimiter= ',', dtype="float", skiprows=1, usecols=None) #initialize charac=[]; label=[] #obtain input characrisitics and label for row in raw_data: charac.append(row[:-1]) label.append(int (row[-1])) return np.array(charac),np.array(label) def knn(k,dtrain,dtest,dtr_label): """k-nearest neighbors algorithm""" pred_label=[] #for each instance in test dataset, calculate #distance in respect to train dataset for di in dtest: distances=[] for ij,dj in enumerate(dtrain): distances.append((ssd.euclidean(di,dj),ij)) #sort the distances to get k-neighbors k_nn=sorted(distances)[:k] #classify accroding to the maxmium label dlabel=[] for dis,idtr in k_nn: dlabel.append(dtr_label[idtr]) pred_label.append(np.argmax(np.bincount(dlabel))) return pred_label def evaluate(result): """evaluate the predicited label""" eval_result=np.zeros(2,int) for x in result: #pred_label==dte_label if x==0: eval_result[0]+=1 #pred_label!=dte_label else: eval_result[1]+=1 return eval_result dtrain,dtr_label=read_data('iris-train.csv') dtest,dte_label=read_data('iris-test.csv') K=[1,3,7,11] print "knn classification result for iris data set:\n" print "k | number of correct/wrong classified test records" for k in K: pred_label=knn(k,dtrain,dtest,dtr_label) eval_result=evaluate(pred_label-dte_label) #print the evaluted result into screen print k," | ", eval_result[0], "/", eval_result[1] print