
【資料探勘筆記六】挖掘頻繁模式、關聯和相關性:基本概念和方法
6.挖掘頻繁模式、關聯和相關性:基本概念和方法
頻繁模式(frequent pattern)是頻繁地出現在資料集中的模式。
6.1 基本概念
頻繁模式挖掘搜尋給定資料集中反覆出現的聯絡,旨在發現大型事務或關係資料集中項之間有趣的關聯或相關性,其典型例子就是購物籃分析。
購物籃分析假設全域是商品的集合,每種商品有一個布林變數,表示該商品是否出現在購物籃中。每個購物籃是一個布林向量表示,分析布林向量,可得到反映商品頻繁關聯或同時購買的購買模式,這些模式可用關聯規則(association rule)形式表示。如購買計算機也趨向於同時購買防毒軟體,用如下規則表示:computer=>antivirus_software[support=2%;confidence=60%]。規則的支援度(support)和置信度(confidence)是規則興趣度的兩種度量,分別反映所發現規則的有用性和確定性。如果規則滿足最小支援度閾值和最小置信度閾值,則關聯規則是有趣的。

同時滿足最小支援度閾值(min_sup)和最小置信度閾值(min_conf)的規則稱為強規則。
項的集合稱為項集,包含k個項的項集稱為k項集。項集的出現頻度是包含項集的事務數,稱為項集的頻度、支援度計數或計數。項集支援度也稱為相對支援度,而出現頻度稱為絕對支援度。如果項集I的相對支援度滿足預定義的最小支援度閾值(即 I的絕對支援度滿足對應的最小支援度計數閾值),則I是頻繁項集(frequent itemset)。頻繁k項集的集合通常記為Lk。關聯規則的挖掘一般兩步:
第一:找出所有的頻繁項集;第二:由頻繁項集產生強關聯規則。
從大型資料集中挖掘頻繁項集的主要挑戰是:產生大量滿足最小支援度(min_sup)的閾值的項集。項集X在資料集D中是閉的(closed),如果不存在真超項集Y,使得Y與X在D中具有相同的支援度計數。項集X是資料集D中的閉頻繁項集(closed frequent itemset),如果X在D中是閉的和頻繁的。項集X是D中的極大頻繁項集(maximal frequent itemset)或極大項集(max-itemset),如果X是頻繁的,並且不存在超項集Y,使得並且 Y在D中是頻繁的。
6.2 頻繁項集挖掘方法
Apriori演算法是一種發現頻繁項集的基本演算法,為布林關聯規則挖掘頻繁項集的原創性演算法。
1)Apriori演算法:通過限制候選產生髮現頻繁項集
先驗性質:頻繁項集的所有非空子集也一定是頻繁的。也稱為反單調性(antimonotone),指如果一個集合不能通過測試,則它的所有超集也不能通過相同的測試。
基於先驗性質,Apriori演算法使用逐層搜尋的迭代方法,其中k項集用於探索k+1項集。首先,通過掃描資料庫,累計每個項的計數,並收集滿足最小支援度的項,找出頻繁I項集的集合,記集合L1;然後,使用L1找出頻繁2項集的集合L2,使用L2找出L3,如此下去,直到不能再找到頻繁k項集。找出每個Lk
基於先驗性質從Lk-1找出Lk,由連線步和剪枝步組成:
連線步:為找出Lk,通過將Lk-1與自身連線產生候選k項集的集合,記為Ck,演算法這裡假定事務或項集中的項按欄位序排序。
剪枝步:Ck是Lk的超集,Ck中的成員可以是頻繁也可以不是,但所有的頻繁k項集都包含在Ck中。
挖掘布林關聯規則發現頻繁項集的Apriori演算法如下:

2)由頻繁項集產生關聯規則
一旦資料庫D中的事務找出頻繁項集,就可以直接產生強關聯規則(強關聯規則滿足最小支援度和最小置信度)。
3)提高Apriori演算法的效率
提高基於Apriori挖掘的效率:
採用基於雜湊的技術(雜湊項集到對應的桶中):一種基於雜湊的技術可用於壓縮候選k項集的集合Ck(k>1)。
事務壓縮(壓縮排一步迭代掃描的事務數):不包含任何頻繁k項集的事務不可能包含任何頻繁(k+1)項集。
劃分(為找候選項集劃分資料):第一階段把D中的事務化分成n個非重疊的分割槽;第二階段評估每個候選的實際支援度,確定全域性頻繁項集。
抽樣:對給定資料的一個子集上挖掘。
動態項集計數:在掃描不同點新增候選項集,動態項集計數將資料庫劃分為用開始點標記的塊。
4)挖掘頻繁項集的模式增長方法
Apriori可能產生大量的候選項集,需要重複地掃描整個資料庫,通過模式匹配檢查一個大的候選集合,這個開銷比較大。因此,提出一種頻繁模式增長的方法(Frequent-Pattern Growth,FP-growth),該方法採用分治策略。首先將代表頻繁項集的資料庫壓縮到一顆頻繁模式樹(FP樹),該樹保留項集的關聯資訊;然後把壓縮後的資料庫劃分成一組條件資料庫(一種特殊型別的投影資料庫),每個資料庫關聯一個頻繁項或模式段,並分別挖掘每個條件資料庫。對於每個模式片段,只考察與它相關聯資料集。
FP樹的挖掘:由長度為1的頻繁模式(初始字尾模式)開始,構造它的條件模式基(一個子資料庫,由FP樹中與該字尾模式一起出現出現的字首路徑集組成)。然後,構造它的條件FP樹,並遞迴地在該樹上進行挖掘。模式增長通過後綴模式與條件FP樹產生的頻繁模式連線實現。
FP-growth方法將發現長頻繁模式的問題轉換成在較小的條件資料庫中遞迴地搜尋一些較短模式,然後連線字尾。使用最不頻繁的項做字尾,提供了很好的選擇性,顯著地降低了搜尋開銷。
演算法:FP-Growth,使用FP樹,通過模式增長挖掘頻繁模式
輸入:D:事務資料庫
min_sup:最小支援度閾值
輸出:頻繁模式的完全集
方法:
1.按以下步驟構造 FP 樹:
a.掃描事務資料庫D一次,收集頻繁項的集合F和它們的支援度計數,對F按支援度計數降序 排序,結果為頻繁項列表L。
b.建立FP樹的根節點,以null標記它,對於D中每個事務Trans,執行:
選擇Trans中的頻繁項,並按L中次序排序。設Trans排序後的頻繁項列表為[p|P],其中p是第一個元素,而P是剩餘元素的列表。呼叫insert_tree([p|P],T)。
如果T有子女N使得N.item_name=p.item_name,則N的計數增加1;否則建立一個新結點N,將其計數置為1,連結到它的父節點T,並且通過結點鏈結構將其連結到具有相同item_name的結點。如果P非空,則遞迴地呼叫insert_tree(P,N)。
2.FP樹的挖掘同構呼叫FP_growth(PF_tree,null)實現,該過程實現如下:
Procedure FP_growth(Tree,a)
if Tree包含單個路徑P then
for 路徑P中結點的每個組合(記作b)
產生模式a ∪ b ,其支援度計數support_count等於b 中結點的最小支援度計數
else for Tree的頭表中的每個ai{
產生一個模式b=a ∪ ai,其支援度計數support_count=ai.support_count;
構造b的條件模式基,然後構造b的條件FP樹Treeb;
if Treeb ≠ ∅ then
呼叫FP_growth(Treeb,b);
}
對FP-growth方法的效能研究表明,對於挖掘長的頻繁模式和短的頻繁模式,都是有效的和可伸縮的,並且大約比Apriori演算法快一個數量級。
5)使用垂直資料格式挖掘頻繁項集
Apriori演算法和FP-growth演算法都是以事務為行、商品項為列,即水平資料格式。
垂直資料格式,商品項為行,事務為列。
使用垂直資料格式,不需要掃描資料庫來確定k+1項集的支援度,因為每個k項集已攜帶了計算支援度的完整資訊。
6)挖掘閉模式和極大模式
挖掘閉頻繁項集的剪枝策略包括:
a.項合併:如果包含頻繁項集X的每個事務都包含項集Y,但不包含 Y 的任何真超集,則 X ∪ Y形成一個閉頻繁項集,並且不必搜尋包含X但不包含Y的任何項集。
b.子項集剪枝:如果頻繁項集X是一個已經發現的閉頻繁項集Y的真子集,並且support_count(X)=support_count(Y),則X和Y在集合列舉樹種的所有後代都不可能是閉頻繁項集,因此可以剪枝。
c.項跳過:在深度優先挖掘閉項集時,每一層都有一個與頭表和投影資料庫相關聯的字首項集X;如果一個區域性頻繁項p在不同層的多個頭表中都具有相同的支援度,則可以將p從較高層頭表中剪裁掉。
當一個新的頻繁項集匯出後,要進行兩種閉包檢查:超集檢查,檢查新的頻繁項集是否是某個具有相同支援度的、已經發現的、閉項集的超集;子集檢查,檢查新發現的項集是否是某個具有相同支援度的、已經發現的、閉項集的子集。
6.3 那些模式是有趣的:模式評估方法
關聯規則挖掘演算法基本都使用支援度-置信度框架。不過低支援度閾值挖掘或挖掘長模式時,會產生很多無趣的規則,這是關聯規則挖掘應用的瓶頸之一。
1)強規則不一定有趣的
基於支援度-置信度框架識別出的強關聯規則,不足以過濾掉無趣的關聯規則,需要度量相關性和蘊涵關係。
2)從關聯分析到相關分析
為識別規則的有趣性,需使用相關性度量來擴充關聯規則的支援度-置信度框架。相關規則不僅用支援度和置信度度量,而且還用項集A和B之間的相關性度量。相關性度量的方法有:
提升度(lift):項集A的出現獨立於項集B的出現,如果P(A∪B)=P(A)P(B);否則,作為事件,項集A和B是依賴的(dependent)和相關的(correlated),則A和B出現之間的提升度定義為:
lift(A,B)=P(A∪B)/P(A)P(B)
如果lift(A,B)<1,則說明A的出現和B的出現是負相關的;如果lift(A,B)>1,則A和B是正相關的,意味每一個的出現蘊涵另一個的出現;如果lift(A,B)=1,則說明A和B是獨立的,沒有相關性。

這四個度量,度量值僅受A、B和A∪B的支援度的影響,或說是受條件概率P(A|B)和P(B|A)的影響,而不受事務總個數的影響。四種度量方法的另一個共同性質是:每個度量值都去【0,1】,且值越大,A和B越緊密。
總結:僅使用支援度和置信度度量來挖掘關聯可能產生大量規則,其中有可能存在使用者不感興趣的;因此,可用模式興趣度度量來擴充套件支援度-置信度框架,有助於聚焦到強模式聯絡的規則挖掘上。
6.4 小結
1)大量資料中的頻繁模式、關聯和相關關係的發現在選擇性銷售、決策分析和商務管理方面是有用的。一個流行的應用領域是購物籃分析,同構搜尋經常一起(或依次)購買的商品的集合,研究顧客的購買習慣。
2)關聯規則挖掘首先找出頻繁項集(項的集合,如 A和B,滿足最小支援度閾值,或任務相關元組的百分比),然後,由它們產生形如A->B的強關聯規則;這些規則滿足最小置信度閾值(預定義的,在滿足A的條件下滿足B的概率);可進一步分析關聯,發現項集A和B之間具有統計相關性的相關規則。
3)對於頻繁項集挖掘,已有許多有效的、可伸縮的演算法,可匯出關聯和相關規則,分成三類:類Apriori演算法、基於頻繁模式增長的演算法,如FP-growth;3)使用垂直資料格式的演算法。
4)Apriori演算法是為布林關聯規則挖掘頻繁項集的原創新演算法,逐層進行挖掘,利用先驗性質:頻繁項集的所有非空子集也都是頻繁的;在第k次迭代(k≥2),根據頻繁(k-1)項集形成k項集候選,並掃描資料庫一次,找出完成的頻繁k項集的集合Lk;使用涉及雜湊和事務壓縮技術的變形使得過程更有效。其他變形包括劃分資料(對每分割槽挖掘,然後合併結果)和抽樣資料(對資料子集挖掘);這些變形可將資料掃描次數減少到一兩次。
5)頻繁模式增長(FP-growth)是一種不產生候選的挖掘頻繁項集方法;構造一個高度壓縮的資料結構(FP樹),壓縮原來的事務資料庫;和類Apriori方法使用產生-測試策略不同,FP-growth更聚焦於頻繁模式(段)增長,避免了高代價的候選產生,可獲得更好的效率。
6)使用處置資料格式挖掘頻繁模式(ECLAT)將給定的、用TID-項集形式的水平資料格式事務資料集變換成項-TID-集合形式的垂直資料格式;根據先驗性質和附加的優化技術(如diffset),通過TID-集的交,對變換後的資料集進行挖掘。
7)並非所有的強關聯規則都是有趣的,應用模式評估度量來擴充套件支援度-置信度框架,識別有效的有趣規則;一種度量是零不變的,如果它的值不受零事務(即不包含所考慮項集的事務)的影響,在許多模式評估度量中,給出了提升度、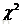
6.5 專案課題
DBLP資料集(http://www.informatik.unitrier.de/~ley/db/)包括超過100萬篇發表在電腦科學會議和雜誌上的論文項。這些項中,很多作者有合著關係,提出一種方法,挖掘密切相關的(即經常一起寫文章的)合著者關係;根據挖掘結果和模式評估度量,分析那種度量方法更有效。