
【資料探勘】【筆記】資料預處理之類別特徵編碼
阿新 • • 發佈:2019-01-09
定義
類別特徵:如['male', 'female']等,模型不能直接識別的資料。處理的目的是將不能夠定量處理的變數量化。
特別的比如星期[1, 2, ... , 7]雖然是數字,但是數值之間沒有大小順序關係,需要視為類別特徵。
處理
編碼為模型可識別的數值型特徵。
根據模型處理能力的不同,需要考慮單純對映為數值或啞變數編碼。(尤其是線型模型和SVMs with standard kernels, knn?)
sklearn.preprocessing.OneHotEncder
This estimator transforms each categorical feature with m possible values into m binary features, with only one active.
把所有可能取值轉換為二進位制表示,只含一個一的那種?
結果
- dt, rf, gb, ada等對於縮放,編碼等不敏感,結果差異不大
- svr, knn結果縮放有提高,編碼還會變差?
pandas.get_dummies
啞變數編碼,適用於pd.DataFrame。
功能和OneHot類似,有額外的drop_first功能。
總結
- 啞變數編碼對於sklearn中的sklearn模型的意義不大。尤其是基於樹模型沒有影響。
- 線性模型有影響
- svm影響不大,甚至預設引數時因為特徵增加,表現下降
- knn不受影響(knn受冗餘特徵的影響較大)
為什麼無關緊要的特徵會損害KNN?
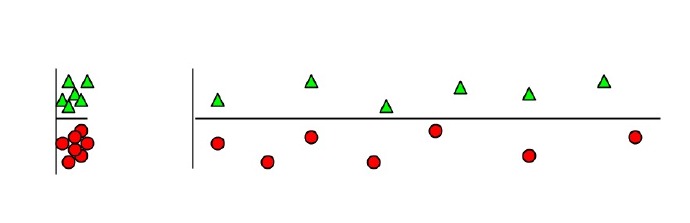
答:如上圖,橫軸為無關緊要特徵,因為橫軸特徵的出現,將原本鮮明的聚類特徵模糊化,縱軸權重被橫軸稀釋,從而得到錯誤的聚類結果。