聚類演算法——python實現SOM演算法
阿新 • • 發佈:2018-12-31
演算法簡介
SOM網路是一種競爭學習型的無監督神經網路,將高維空間中相似的樣本點對映到網路輸出層中的鄰近神經元。
訓練過程簡述:在接收到訓練樣本後,每個輸出層神經元會計算該樣本與自身攜帶的權向量之間的距離,距離最近的神經元成為競爭獲勝者,稱為最佳匹配單元。然後最佳匹配單元及其鄰近的神經元的權向量將被調整,以使得這些權向量與當前輸入樣本的距離縮小。這個過程不斷迭代,直至收斂。
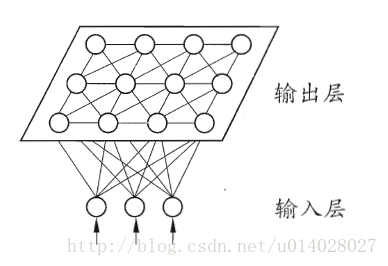
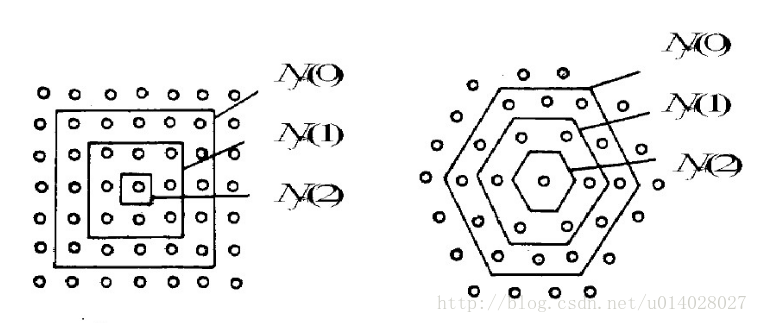
網路結構:輸入層和輸出層(或競爭層),如下圖所示。 輸入層:假設一個輸入樣本為X=[x1,x2,x3,…,xn],是一個n維向量,則輸入層神經元個數為n個。 輸出層(競爭層):通常輸出層的神經元以矩陣方式排列在二維空間中,每個神經元都有一個權值向量。 假設輸出層有m個神經元,則有m個權值向量,Wi = [wi1,wi2,....,win], 1<=i<=m。
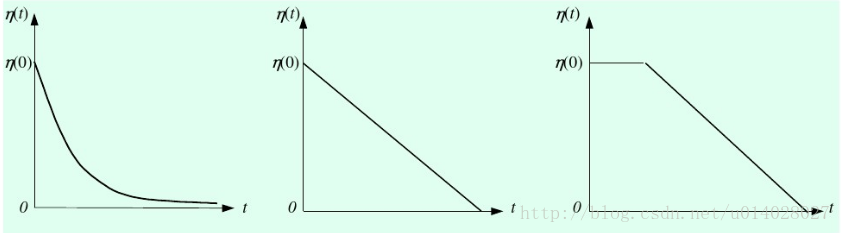
演算法流程: 1. 初始化:權值使用較小的隨機值進行初始化,並對輸入向量和權值做歸一化處理 X’ = X/||X|| ω’i= ωi/||ωi||, 1<=i<=m ||X||和||ωi||分別為輸入的樣本向量和權值向量的歐幾里得範數。 2.將樣本輸入網路:樣本與權值向量做點積,點積值最大的輸出神經元贏得競爭, (或者計算樣本與權值向量的歐幾里得距離,距離最小的神經元贏得競爭)記為獲勝神經元。 3.更新權值:對獲勝的神經元拓撲鄰域內的神經元進行更新,並對學習後的權值重新歸一化。 ω(t+1)= ω(t)+ η(t,n) * (x-ω(t)) η(t,n):η為學習率是關於訓練時間t和與獲勝神經元的拓撲距離n的函式。 η(t,n)=η(t)e^(-n) η(t)的幾種函式影象如下圖所示。 4.更新學習速率η及拓撲鄰域N,N隨時間增大距離變小,如下圖所示。 5.判斷是否收斂。如果學習率η<=ηmin或達到預設的迭代次數,結束演算法。
python程式碼實現SOM
import numpy as np
import pylab as pl
class SOM(object):
def __init__(self, X, output, iteration, batch_size):
"""
:param X: 形狀是N*D, 輸入樣本有N個,每個D維
:param output: (n,m)一個元組,為輸出層的形狀是一個n*m的二維矩陣
:param iteration:迭代次數
:param batch_size:每次迭代時的樣本數量
初始化一個權值矩陣,形狀為D*(n*m),即有n*m權值向量,每個D維
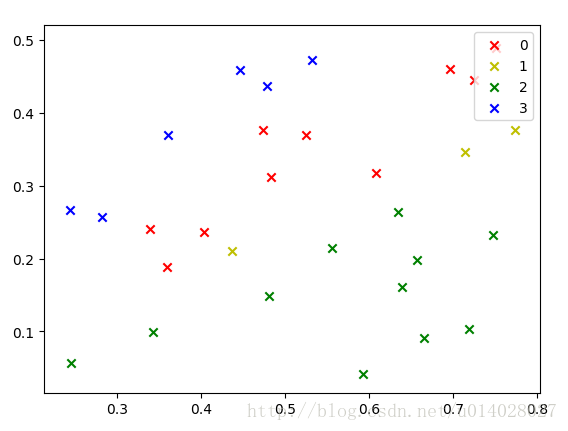
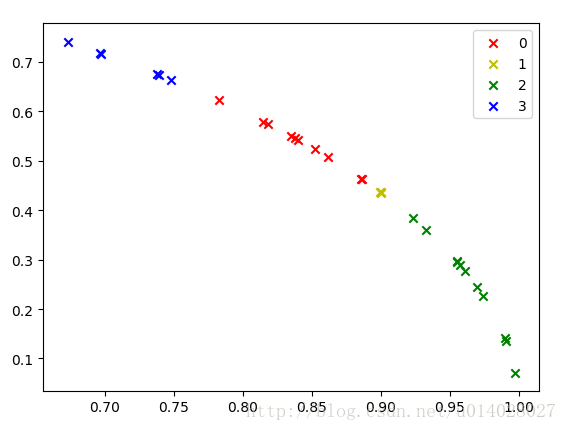
""" 由於資料比較少,就直接用的訓練集做測試了,執行結果圖如下,分別是對未歸一化的資料和歸一化的資料進行的展示。